opencv︱opencv中实现行人检测:HOG+SVM(二)
接:opencv︱HOG描述符介绍+opencv中HOG函数介绍(一)
相关博文:Recorder︱图像特征检测及提取算法、基本属性、匹配方法转载于:Opencv HOG行人检测
源码分析(一)和HOG:从理论到OpenCV实践
HOG+SVM是传统计算机视觉中的经典组合模型。
零、行人检测综述
来源于:行人检测、跟踪与检索领域年度进展报告
行人检测,就是将一张图片中的行人检测出来,并输出bounding
box级别的结果。而如果将各个行人之间的轨迹关联起来,就变成了行人跟踪。而行人检索则是把一段视频中的某个感兴趣的人检索出来。
行人检测领域的工作大致可被归为以下三类:
- 第一类是将传统的检测方法Boosting trees 和 CNN 结合起来。张姗姗等人在CVPR 2016的工作是使用 ICF
提取proposal,然后使用 CNN 进行重新打分来提高检测的性能;在 ECCV 2016上,中山大学林倞教授课题组使用RPN 提取
proposal,同时提取卷积特征,然后使用 Boosting trees进行二次分类,性能得到了很大的提升。 - 第二类是解决多尺度问题,例如在视频数据中人的尺度变化问题。颜水成教授课题组提供了一种解决方法:训练两个网络,一个网络关注大尺度的人,另一个网络关注小尺度的人,在检测时将两个网络进行加权融合得到最终的结果,这样能使性能得到很大的提升;UCSD
在 ECCV
2016上有一个类似的工作,提出在高层提取大尺度人的特征,在低层提取小尺度人的特征,这样能保留尽量多的信息量,使得对小尺度的行人也有较好的检测效果。 - 第三类是使用语义分割信息来辅助行人检测。首先对整个图像进行语义分割,然后将分割的结果作为先验信息输入到检测网络中(包括传统的 ICF
网络,以及现在常用的CNN),这样可以通过对整体环境的感知来提高检测的效果。
新提高检测率的科研方式:
2016年张姗姗等人从分析的角度对各个工作进行总结和归纳。通过分析错误案例来找到错误来源,并提出相应的解决方案以进一步提高检测率。研究发现,在高层级中主要有两类错误,分别是定位错误和背景分类错误。可以尝试两个解决方案,其一是针对检测框对齐性比较差这一现象,可以通过使用对齐性更好的训练样本标签来解决;而针对模型判别能力比较差的问题,可以通过在传统的 ICF 模型上使用 CNN 进行重新打分来提升检测的性能。
数据集:
CVPR 2017上将会公布一个新的行人检测数据集:CityPersons。CityPersons数据集是脱胎于语义分割任务的Cityscapes数据集,对这个数据集中的所有行人提供 bounding box 级别的对齐性好的标签。由于CityPersons数据集中的数据是在3个不同国家中的18个不同城市以及3个季节中采集的,其中单独行人的数量明显高于Caltech 和 KITTI 两个数据集。实验结果也表明,CityPersons 数据集上训练的模型在 Caltech 和 KITTI 数据集上的测试漏检率更低。也就是说,CityPersons数据集的多样性更强,因而提高了模型的泛化能力。
文中提到所有论文的下载链接为:http://pan.baidu.com/s/1eRO9xoY
一、基本理解
HOG属于特征提取,它统计梯度直方图特征。具体来说就是将梯度方向(0->360°)划分为9个区间,将图像化为16x16的若干个block,每个block在化为4个cell(8x8)。对每一个cell,算出每一点的梯度方向和模,按梯度方向增加对应bin的值,最终综合N个cell的梯度直方图形成一个高维描述子向量。实际实现的时候会有各种插值。
选用的分类器是经典的SVM。
检测框架为经典的滑动窗口法,即在位置空间和尺度空间遍历搜索检测。
原始图像打完补丁后就直接用固定的窗口在图像中移动,计算检测窗口下的梯度,形成描述子向量,然后就直接SVM了

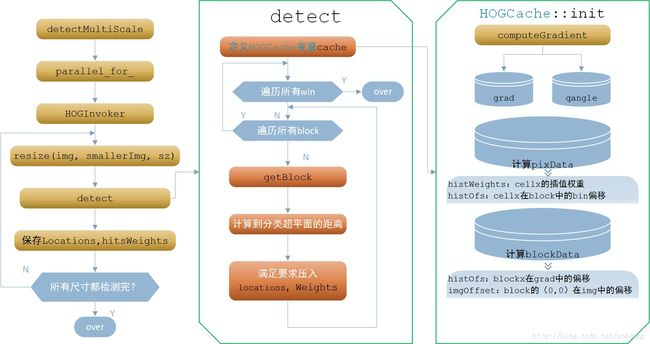
二、opencv实现的code
#include 上述过程并没有像人脸检测Demo里有Load训练好的模型的步骤,这个getDefaultPeopleDetector是默认模型,这个模型数据在OpenCV源码中是一堆常量数字,这些数字是通过原作者提供的行人样本INRIAPerson.tar训练得到的。
这里只是用到了HOG的识别模块,OpenCV把HOG包的内容比较多,既有HOG的特征提取,也有结合SVM的识别,这里的识别只有检测部分,OpenCV提供默认模型,如果使用新的模型,需要重新训练。
三、如何降低行人检测误识率
本节转载于:机器视觉学习笔记(3)–如何降低行人检测误识率
现在的行人检测算法大多是应用HOG特征识别整体,虽然这也能达到较高的识别率,但误识别率也比较大,因此有必要进行优化识别。
通过大量样本分析发现,人体的姿态除了四肢,其他大体固定,人体示意图如图1所示。
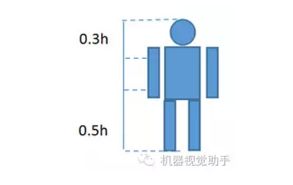
图1:人体示意图
我们可以通过组合识别优化检测算法来实现。首先可以通过腿部识别,再在腿部的对应上区域对肩膀至头部位识别,从而降低误识率。
腿部由于走动原因姿态会有变化,所以很难用比较直观的特征去识别,可以用HOG+SVM识别腿部,如图2所示。

图2:腿部识别
肩膀至头部的边缘轮廓类似形状Ω,如图3所示。
图3:肩膀至头部轮廓形状
由此我们可以知道其形状特征大体固定,可将轮廓的Hu不变矩作为主要特征,训练识别器。识别可得,如图4所示。

图4:肩膀至头部识别
由此我可以得到最终的行人检测,如图5所示。

图5:行人检测
在本人收集的训练库上,用该算法与OPenCV自带的行人检测算法相比,误识率有显著的降低。
四、行人检测的数据库与开源项目
1、
http://pascal.inrialpes.fr/soft/olt/行人检测开源库
简介:
Dalal于2005年提出了基于HOG特征的行人检测方法, HOG特征目前也被用在其他的目标检测与识别、图像检索和跟踪等领域中。
2、行人检测DataSets
参考于:NLP+VS︱深度学习数据集标注工具、图像语料数据库、实验室搜索ing…
(1).基于背景建模:利用背景建模方法,提取出前景运动的目标,在目标区域内进行特征提取,然后利用分类器进行分类,判断是否包含行人;
(2).基于统计学习的方法:这也是目前行人检测最常用的方法,根据大量的样本构建行人检测分类器。提取的特征主要有目标的灰度、边缘、纹理、颜色、梯度直方图等信息。分类器主要包括神经网络、SVM、adaboost以及现在被计算机视觉视为宠儿的深度学习。
Caltech行人数据库:http://www.vision.caltech.edu/Image_Datasets/CaltechPedestrians/
该数据库是目前规模较大的行人数据库,采用车载摄像头拍摄,约10个小时左右,视频的分辨率为640×480,30帧/秒。标注了约250,000帧(约137分钟),350000个矩形框,2300个行人,另外还对矩形框之间的时间对应关系及其遮挡的情况进行标注。数据集分为set00~set10,其中set00~set05为训练集,set06~set10为测试集(标注信息尚未公开)。性能评估方法有以下三种:(1)用外部数据进行训练,在set06~set10进行测试;(2)6-fold交叉验证,选择其中的5个做训练,另外一个做测试,调整参数,最后给出训练集上的性能;(3)用set00~set05训练,set06~set10做测试。由于测试集的标注信息没有公开,需要提交给Pitor Dollar。结果提交方法为每30帧做一个测试,将结果保存在txt文档中(文件的命名方式为I00029.txt I00059.txt ……),每个txt文件中的每行表示检测到一个行人,格式为“[left, top,width, height, score]”。如果没有检测到任何行人,则txt文档为空。该数据库还提供了相应的Matlab工具包,包括视频标注信息的读取、画ROC(Receiver Operatingcharacteristic Curve)曲线图和非极大值抑制等工具。
其他数据集可参考:行人检测:http://www.52ml.net/17004.html