Linux(centos6.5)系统网络ip配置及hadoop完全分布式集群部署详细步骤
Hadoop集群搭建及网络ip配置@TOC
1、hadoop运行环境配置
此处需要三台虚拟机,以为HDFS的NameNode、SecondaryNameNode和Yarn的ResourceManager比较耗费资源,现实开发中也是不会配置在同一台服务器,电脑内存最好8G或以上,不然就算虚拟机开启的是命令界面到时候启动集群后也会卡
- 虚拟机网络设置为NAT模式

重新启动系统。
[root@hadoop101 ~]# sync
[root@hadoop101 ~]# reboot - 克隆虚拟机

点击下一步后会显示如下
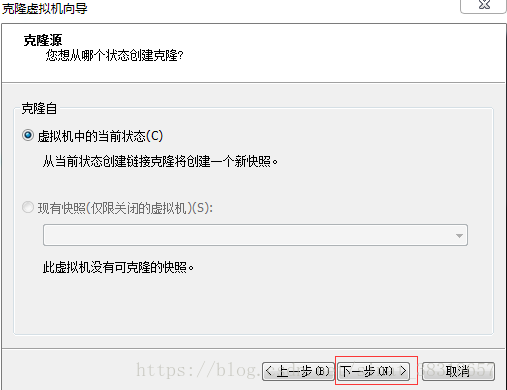
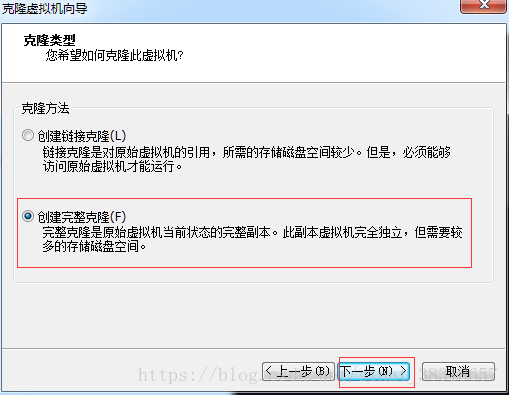


然后启动虚拟机 - 修改网络ip
(1) 在终端命令窗口中输入
[root@hadoop101 /]#vim /etc/udev/rules.d/70-persistent-net.rules
进入如下页面删除eth0行,将eth1修改为eth0,同时复制物理ip地址

(2)修改ip地址
[root@hadoop101 /]# vim /etc/sysconfig/network-scripts/ifcfg-eth0
修改前

(注意ip地址应和虚拟机中的网络地址前三个数一样,否则会导致连不了网,后面那个就不能同)

修改后

(3)执行以下命令激活网络
[root@hadoop101 /]# service network restart

(4)如果报错,重启虚拟机
[root@hadoop101 /]# reboot
- 修改主机名
(1)进入Linux系统查看本机的主机名。通过hostname命令查看。
[root@hadoop100 /]# hostname
(2)如果感觉此主机名不合适,我们可以进行修改。通过编辑/etc/sysconfig/network文件。
[root@hadoop100~]# vi /etc/sysconfig/network
(3)打开此文件后,可以看到主机名。修改此主机名为我们想要修改的主机名
修改文件中主机名称
NETWORKING=yes
NETWORKING_IPV6=no
HOSTNAME= hadoop101
注意:主机名称不要有“_”下划线
(4)保存退出
(5)打开/etc/hosts
[root@hadoop100 ~]# vim /etc/hosts
添加如下内容(IP地址和主机名应和自己配置的对应)
192.168.61.101 hadoop101
192.168.61.102 hadoop102
192.168.61.103 hadoop103
(6)并重启设备重启后查看主机名,已经修改成功
- 关闭防火墙
(1)查看防火墙开机启动状态
[root@hadoop101 ~]# chkconfig iptables --list
(2)关闭防火墙
[root@hadoop101 ~]# chkconfig iptables off
- 在opt目录下创建文件
(1)创建master用户
在root用户里面执行如下操作
[root@hadoop101 opt]# adduser master
[root@hadoop101 opt]# passwd master
更改用户 test 的密码 。
新的 密码:
无效的密码: 它没有包含足够的不同字符
无效的密码: 是回文
重新输入新的 密码:
passwd: 所有的身份验证令牌已经成功更新。
(2)设置master用户具有root权限
[root@hadoop101 master]# vi /etc/sudoers
找到下面一行,在root下面添加一行,如下所示:
#Allow root to run any commands anywhere
root ALL=(ALL) ALL
masterALL=(ALL) ALL
修改完毕,现在可以用master帐号登录,然后用命令 su - ,即可获得root权限进行操作。
(3)在/opt目录下创建文件夹
a.在root用户下创建module、software文件夹
[root@hadoop101 opt]# mkdir module
[root@hadoop101 opt]# mkdir softwar
b.修改module、software文件夹的所有者
[root@hadoop101 opt]# chown master:master module
[root@hadoop101 opt]# chown master:master sofrware
- 安装jdk
(1)卸载现有jdk
查询是否安装java软件:
[root@hadoop101 opt]# rpm -qa|grep java
如果安装的版本低于1.7,卸载该jdk:
[root@hadoop101 opt]# rpm -e 软件包
(2)自行下载一个jdk和hadoop
[root@hadoop101software]# ls
hadoop-2.7.2.tar.gz jdk-8u144-linux-x64.tar.gz
(3)解压jdk到/opt/module目录下
[root@hadoop101software]# tar -zxvf jdk-8u144-linux-x64.tar.gz -C /opt/module/
(4)配置jdk环境变量
a.先获取jdk路径:
[root@hadoop101 jdk1.8.0_144]# pwd
/opt/module/jdk1.8.0_144
b.打开/etc/profile文件:
[root@hadoop101 jdk1.8.0_144]# vi /etc/profile
在profie文件末尾添加jdk路径:
##JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH= P A T H : PATH: PATH:JAVA_HOME/bin
保存后退出:
:wq
c.让修改后的文件生效:
[root@hadoop101 jdk1.8.0_144]# source /etc/profile
d.测试jdk安装成功
[root@hadoop101 jdk1.8.0_144]# java -version
java version “1.8.0_144”
(如果java -version不可以用就重启)
- 安装Hadoop
(1)进入到Hadoop安装包路径下:
[root@hadoop101 ~]# cd /opt/software/
(2)解压安装文件到/opt/module下面
[root@hadoop101 software]# tar -zxf hadoop-2.7.2.tar.gz -C /opt/module/
(3)在/opt/module/hadoop-2.7.2/etc/hadoop路径下配置hadoop-env.sh
a) Linux系统中获取jdk的安装路径:
[root@hadoop101 jdk1.8.0_144]# echo $JAVA_HOME
/opt/module/jdk1.8.0_144
b) 修改hadoop-env.sh文件中JAVA_HOME 路径:
[root@hadoop101 hadoop]# vi hadoop-env.sh
修改JAVA_HOME如下
export JAVA_HOME=/opt/module/jdk1.8.0_144
(4)将hadoop添加到环境变量
获取hadoop安装路径:
[root@ hadoop101 hadoop-2.7.2]# pwd
/opt/module/hadoop-2.7.2
打开/etc/profile文件:
[root@ hadoop101 hadoop-2.7.2]# vi /etc/profile
在profie文件末尾添加jdk路径:(shitf+g)
##HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
保存后退出:
:wq
让修改后的文件生效:
[root@ hadoop101 hadoop-2.7.2]# source /etc/profile
重启(如果hadoop命令不能用再重启):
[root@ hadoop101 hadoop-2.7.2]# reboot
修改/opt目录下的所有文件所有者为master
[root@hadoop101 opt]# chown master:master -R /opt/
切换到atguigu用户
[root@hadoop101 opt]# su master#一般不会用root
安装三台虚拟机都一致为以上这样的步骤
2、完全分布式部署
-
SSH无密码登录(为了集群之间通信)
(1)基本语法
ssh 另一台电脑的ip地址
(2)无密钥配置
进入到我的home目录
[master@hadoop101 opt]$ cd ~/.ssh
生成公钥和私钥:
[master@hadoop101 .ssh]$ ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)将公钥拷贝到要免密登录的目标机器上
[master@hadoop101 .ssh]$ ssh-copy-id hadoop102
[master@hadoop101 .ssh]$ ssh-copy-id hadoop103
按照以上的这些步骤配置ResourceManager所在的虚拟机无密登录另外两台,
其中NameNode所在的虚拟机还要切换到root账户配置一次(此处是hadoop101要切换root账户配置)
- 集群规划

- 配置文件
(1)core-site.xml
[master@hadoop101 hadoop]$ vi core-site.xml
fs.defaultFS
hdfs://hadoop101:9000
hadoop.tmp.dir
/opt/module/hadoop-2.7.2/data/tmp
(2)Hdfs
[master@hadoop101 hadoop]$ vi hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
(3)hdfs-site.xml
dfs.replication
3
dfs.namenode.secondary.http-address
hadoop103:50090 #注意此处为secondaryNameNode的主机地址
(4)slaves(告诉namenode有几个节点)
[master@hadoop101 hadoop]$ vi slaves
hadoop101
hadoop102
hadoop103
(5)yarn-env.sh
[master@hadoop101 hadoop]$ vi yarn-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
(6)yarn-site.xml
[master@hadoop101 hadoop]$ vi yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
hadoop102 #注意此处为resourcemanager的主机
(7)mapred-env.sh
[master@hadoop101 hadoop]$ vi mapred-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
(8)(对mapred-site.xml.template重新命名为) mapred-site.xml
[master@hadoop101 hadoop]$ mv mapred-site.xml.template mapred-site.xml
[master@hadoop101 hadoop]$ vi mapred-site.xml
(9)mapred-site.xml
[master@hadoop101 hadoop]$ vi mapred-site.xml
mapreduce.framework.name
yarn
每台机器都是如上配置几个文件
3、集群启动及测试
如果集群是第一次启动,需要格式化namenode
[atguigu@hadoop102 hadoop-2.7.2]$ bin/hdfs namenode -format
- 启动HDFS并查看
[master@hadoop101 hadoop-2.7.2]$ sbin/start-dfs.sh
[master@hadoop101 hadoop-2.7.2]$ jps #查看节点
4166 NameNode
4482 Jps
4263 DataNode
[master@hadoop102 hadoop-2.7.2]$ jps
3218 DataNode
3288 Jps
[master@hadoop103 hadoop-2.7.2]$ jps
3221 DataNode
3283 SecondaryNameNode
3364 Jps
- 启动yarn
[master@hadoop102 hadoop-2.7.2]$ sbin/start-yarn.sh
注意:Namenode和ResourceManger如果不是同一台机器
不能在NameNode上启动 yarn,应该在ResouceManager所在的机器上启动yarn。