一文读懂GoogLeNet神经网络
本文介绍的是著名的网络结构GoogLeNet,,目的是试图领会其中结构设计思想。
一文读懂GoogLeNet神经网络
- GoogLeNet特点
- 优化网络质量的生物学原理
- GoogLeNet网络结构的动机
- GoogLeNet架构细节
- Inception模块和普通卷积结构的差异
- 辅助分类器
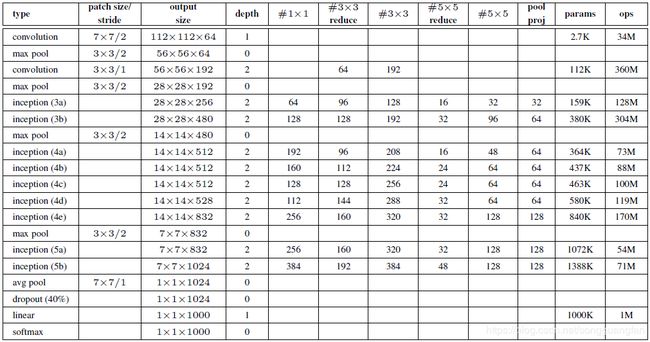
- GoogLeNet网络架构
- GoogLeNet训练以及样本预处理
- GoogLeNet测试以及测试样本处理
- GoogLeNet检测+分类
- MultiBox方法
- SelectiveSearch方法
GoogLeNet特点
1.此网络架构的主要特点就是提升了对网络内部计算资源的利用。
2.增加了网络的深度和宽度,网络深度达到22层(不包括池化层和输入层),但没有增加计算代价。
3.参数比2012年冠军队的网络少了12倍,但是更加准确。
4.对象检测得益于深度架构和传统的计算机视觉算法(R-CNN)。
优化网络质量的生物学原理
基于赫布原理和多尺度处理。
赫布原理:突触前神经元向突触后神经元的持续重复的刺激可以导致突触传递效能的增加。赫布理论有下列的特性:
1.知觉获知是在神经系统中的表征是一群而不是一个细胞,因此这是一个较为分散的表征系统。表征不同的心智活动,并不完全系于细胞的独特身分,因为一个细胞可同时参与几个细胞集团。
2.在细胞集合中,无论是组成分子或是联络通路,均有相当程度的余裕性,所以容许神经系统有部分的破坏,依然能执行所负担的功能。同时这些平行通路可容许由不同的部位到达兴奋全体的目的。
3.细胞集合的成立虽然依赖连结,但连结的成果并非使刺激直通于反应,而是在中枢建立一个有缓冲作用(使刺激的影响能盘桓较久)的回路。
4.人的大脑神经元运作的方式的确和原子内粒子的运作方式类似,人类的大脑的确是所有神经网络的总和。每个神经元本身并不重要,重要的是这些神经元怎么联合起来,联合起来可以做些什么事,这才是的细胞集合的核心。
GoogLeNet网络结构的动机
提高网络性能最直接的方法就是增加网络的尺寸(深度和宽度)这样会带来两个问题:
- 扩大后的网络含有大量的参数,容易产生过拟合,大量的带标签的训练样本不容易得到。
- 扩大后的网络要消耗大量的计算资源。
解决这两个问题的基本方法:将全连接变成稀疏连接,包括卷积层。即Dropout理论,符合赫布原理,在非严格条件下,实际上是可行的。同时GoogLeNet还参考了以下方法:
1.CNN典型的结构:一堆卷积层+若干全连接层。
2.针对大规模数据集问题,现在的趋势是增加层数和层的尺寸,并且使用dropout解决过拟合问题。
3.使用Max Pool和Average Pool。
4.使用Network in Network方法,增加网络的表现能力,这种方法可以看做是一个额外的1*1卷积层再加上一个ReLU层。NIN最重要的是降维,解决了计算瓶颈,从而解决网络尺寸受限的问题。这样就可以增加网络的深度和宽度了,而且不会有很大的性能损失。
5.当前最好的对象检测方法是R-CNN。R-CNN将检测问题分解为两个子问题:首先利用低级特征(颜色和超像素一致性)在分类不可知时寻找潜在目标,然后使用CNN分类器识别潜在目标所属类别。GoogLeNet在这两个阶段都进行了增强效果。
GoogLeNet架构细节
Inception模块和普通卷积结构的差异
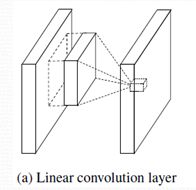
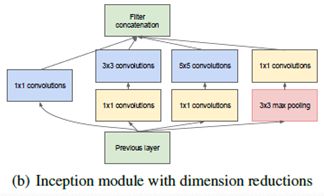
图(a)是传统的多通道卷积操作,图(b)是GoogLeNet中使用的Inception模块,两者的区别在于:
- Inception使用了多个不同尺寸的卷积核,还添加了池化,然后将卷积和池化结果串联在一起。
- 卷积之前有1×1的卷积操作,池化之后也有1×1的卷积操作。
- Inception模块中的多尺寸卷积核的卷积卷积过程和普通卷积过程不同。
第一点不同的原因是:Inception的主要思想就是如何找出最优的局部稀疏结构并将其覆盖为近似的稠密组件,这里就是将不同的局部结构组合到了一起。
第二点不同的原因是:原始的卷积是广义线性模型GLM(generalized linear model),GLM的抽象等级较低,无法很好的表达非线性特征,这种1×1的卷积操作将高相关性的节点聚集在一起。什么是高相关性节点呢?两张特征图中相同位置的节点就是相关性高的节点。假设当前层的输入大小是28×28×256,卷积核大小为1×1×256,卷积得到的输出大小为28×28×1。可以看出这种操作一方面将原来的线性模型变成了非线性模型,将高相关性节点组合到了一起,具有更强的表达能力,另一方面减少了参数个数。举个例子:
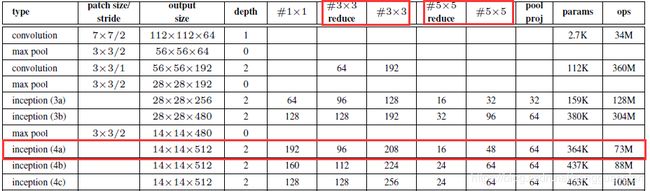
假设将Inception(4a)换成传统的3×3卷积,那么转换前后的参数个数对比如下:
3×3卷积的参数个数是512×3×3×480=2211840,Inception的参数个数是192×1×1×480 + 96×1×1×480 + 208×3×3×96 + 16×1×1×480 + 48×5×5×16 + 64×1×1×480 = 536064。Inception结构的参数个数明显比普通卷积结构的少了很多。
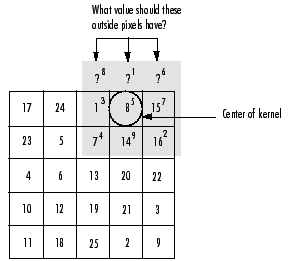
第三点不同体现在:卷积核与接受域对齐方式不同。图3左是普通卷积过程,其对齐方式是让卷积核的左上角和接受域的左上角对齐,这种对齐方式卷积核始终在接受域的内部,不会跑到接受域的外部。图3右是GoogLeNet使用的卷积过程,其对齐方式是让卷积核的中心和接受域的左上角对齐,这种对齐方式卷积核可能会跑到接受域的外部,此时接受域外部和卷积核重合的部分采取补0的措施。GoogLeNet卷积方式使得步长是1的卷积得到的输出大小和输入大小一致。

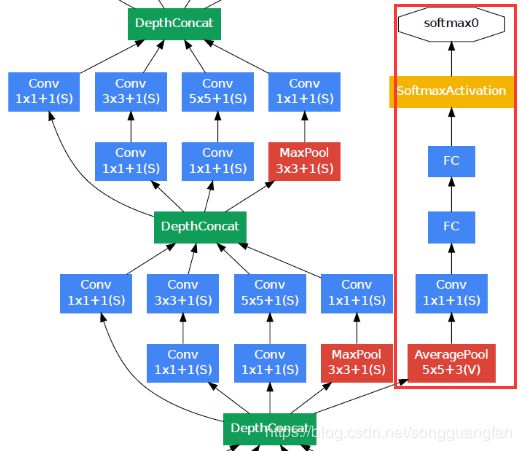
辅助分类器
根据实验数据,发现神经网络的中间层也具有很强的识别能力,为了利用中间层抽象的特征,在某些中间层中添加含有多层的分类器。如下图所示,红色边框内部代表添加的辅助分类器。
GoogLeNet网络架构
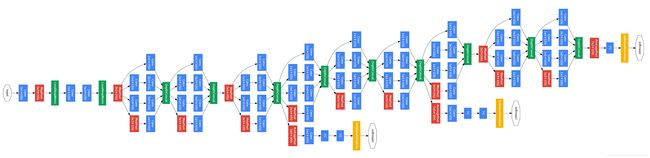
第一幅图是GoogLeNet基本结构,第二幅图是添加了辅助分类器的结构。
GoogLeNet神经网络中,使用了前两节提到的Inception模块和辅助分类器,而且由于全连接网络参数多,计算量大,容易过拟合,所以GoogLeNet没有采用AlexNet(2012年ImageNet冠军队使用的网络结构,前五层是卷积层,后三层是全连接层)中的全连接结构,直接在Inception模块之后使用Average Pool和Dropout方法,不仅起到降维作用,还在一定程度上防止过拟合。
在Dropout层之前添加了一个7×7的Average Pool,一方面是降维,另一方面也是对低层特征的组合。我们希望网络在高层可以抽象出图像全局的特征,那么应该在网络的高层增加卷积核的大小或者增加池化区域的大小,GoogLeNet将这种操作放到了最后的池化过程,前面的Inception模块中卷积核大小都是固定的,而且比较小,主要是为了卷积时的计算方便。
第二幅图中蓝色部分是卷积块,每个卷积块后都会跟一个ReLU(受限线性单元)层作为激活函数(包括Inception内部的卷积块)
GoogLeNet训练以及样本预处理
- 训练7个GoogLeNet模型,其中包含一个加宽版本,其余6个模型初始化和超参数都一样,只是采样方法和样本顺序不同
- 采用模型和数据并行技术,用几个高端GPU训练一周可得到收敛(估算)
- 多个模型的训练是不同步的,超参数的变化也是不一样的,比如dropout和学习率
- 有些模型主要训练小尺寸样本,有些模型训练大尺寸样本
- 采样时,样本尺寸缩放从8%到100%,宽高比随机选取3/4或4/3(多尺度)
- 将图像作光度扭曲,也就是随机更改图像的对比度,亮度和颜色。这样可以增加网络对这些属性的不变性
- 使用随机插值方法重置图像尺寸(因为网络输入层的大小是固定的),
使用到的随机插值方法:双线性插值,区域插值,最近邻插值,三次方插值,这些插值方法等概率的被选择使用。图像放大时,像素也相应地增加 ,增加的过程就是“插值”程序自动选择信息较好的像素作为增加的像素,而并非只使用临近的像素,所以在放大图像时,图像看上去会比较平滑、干净 - 改变超参数(反向传播若干次之后改变超参数,或者误差达到某阈值时改变超参数)
GoogLeNet测试以及测试样本处理
- 对于一个测试样本,将图像的短边缩放成4种尺寸,分别为256,288,320,352。
- 从每种尺寸的图像的左边,中间,右边(或者上面,中间,下面)分别截取一个方形区域。
- 从每个方形区域的4个拐角和中心分别截取一个224×224区域,再将方形区域缩小到224×224,这样每个方形区域能得到6张大小为224×224的图像,加上它们的镜像版本(将图像水平翻转),一共得到4×3×6×2=144张图像。这样的方法在实际应用中是不必要的,可能存在更合理的修剪方法。下图展示了不同修剪方法和不同模型数量的组合结果:

在论文《Some improvements on deep convolutional neural network based image classification》提到了用贪心算法只要10到15个修剪样本就可以了。
每个模型的Softmax分类器在多个修剪图片作为输入时都得到多个输出值,然后再对所有分类器的softmax概率值求平均。
GoogLeNet检测+分类
检测方法使用SelectiveSearch+MultiBox (Google),主要是为了获取可能含有对象的候选区域,分类方法使用上述提到的GoogLeNet神经网络。
MultiBox方法

- 将AlexNet(如图8)的最后一层改为输出k个边界框和k个置信度。
- 边界框编码为四个节点值,分别是边界框的左上顶点和右下顶点的相对坐标。
- 置信度是为这个边界框打分,表示该边界框含有目标的可能性,这里k=200。
- 位置损失函数:
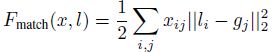
如果第i个预测框对应第j个目标,那么xij=1,否则为0。 - 置信度损失函数(逻辑回归)
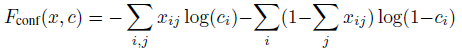
如果第i个预测框和某一个目标匹配,那么 。 - 最终的损失函数为:
![]()
SelectiveSearch方法
将超像素尺寸改为原来的2倍,这样生成的候选框减少一半。此处并非严格的将超像素尺寸扩大1倍,而是在超像素合并过程中删除掉一半被合并的像素。


第一幅图是SelectiveSearch的合并效果图,第二幅图是SelectiveSearch合并算法伪代码。
假设R初始时有k个区域,合并两个区域时删除被合并的两个区域,直到R中只有k/2个区域时,执行正常的合并操作,不再删除候选区域。这样生成的候选框比原始SelectiveSearch算法生成的候选框数量少一半。
通过MultiBox和SelectiveSearch方法得到一系列的候选框,将这些候选框输入到GoogLeNet神经网络中进行分类,得到最终的结果。
检测分类的性能:
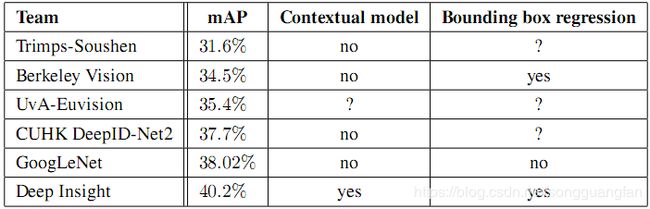
1.单个模型性能:
2. 综合性能

GoogLeNet单个模型的分类性能比Deep Insight差2个百分点,6个模型放在一起平均之后的性能比Deep Insight高了3个百分点。