TensorFlow SiameseNet 人脸识别总结
主要用SiameseNet模型实现人脸识别的功能
借鉴https://www.jianshu.com/p/1df484d9eba9
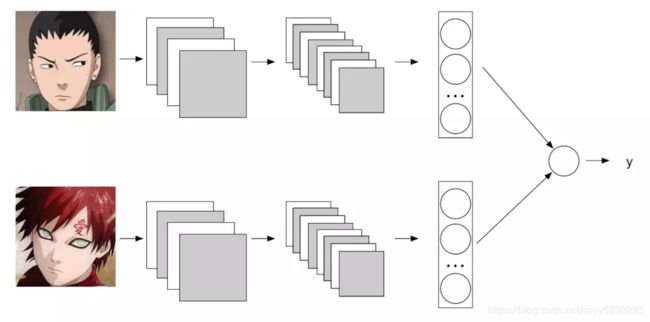
 数据集采用微软的MS-Celeb-1M公开人脸数据集,大家直接下载对齐好的那个数据集,首先网络上有一份清理过的list,文件名是:MS-Celeb-1M_clean_list.txt,大约160M。然后用组合算法生成positive_pairs_path.txt和negative_pairs_path.txt两个文件,也是这里代码需要用到的。
数据集采用微软的MS-Celeb-1M公开人脸数据集,大家直接下载对齐好的那个数据集,首先网络上有一份清理过的list,文件名是:MS-Celeb-1M_clean_list.txt,大约160M。然后用组合算法生成positive_pairs_path.txt和negative_pairs_path.txt两个文件,也是这里代码需要用到的。
下面就主要讲解下代码,方便以后自己得理解:
1、文件config.py代码解读:
这部分主要是定义一些宏:
/////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
import tensorflow as tf
flags = tf.app.flags
FLAGS = flags.FLAGS
flags.DEFINE_integer('train_iter', 500001, 'Total training iter')
flags.DEFINE_integer('validation_step', 1000, 'Total training iter')
flags.DEFINE_integer('step', 1000, 'Save after ... iteration')
flags.DEFINE_integer('DEV_NUMBER', -2000, '验证集数量')
flags.DEFINE_integer('batch_size', 256, '批大小')
flags.DEFINE_string('BASE_PATH', 'same_size/lfw/', '图片位置')
flags.DEFINE_string('negative_file', 'negative_pairs_path.txt', '不同人的文件')
flags.DEFINE_string('positive_file', 'positive_pairs_path.txt', '相同人的文件')
///////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
2、dataset.py文件解读
这部分主要是实现数据集的前期准备工作:
///////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
import numpy as np
from PIL import Image
from config import FLAGS
import os
DEV_NUMBER = FLAGS.train_iter
BASE_PATH = FLAGS.BASE_PATH
batch_size = FLAGS.batch_size
从同一个人和不同一个人的文件夹中读取数据
negative_pairs_path_file = open(FLAGS.negative_file, 'r')
negative_pairs_path_lines = negative_pairs_path_file.readlines()
positive_pairs_path_file = open(FLAGS.positive_file, 'r')
positive_pairs_path_lines = positive_pairs_path_file.readlines()
定义数据对,其中similar_list 作为标签,同一个人为1,不同人为0
left_image_path_list = []
right_image_path_list = []
similar_list = []
将negative和positive里对应的人名放到left_image_path_list 和right_image_path_list 里,标签放到similar_list中
for line in negative_pairs_path_lines:
left_right = line.strip().split(' ')
left_image_path_list.append(left_right[0])
right_image_path_list.append(left_right[1])
similar_list.append(0)
for line in positive_pairs_path_lines:
left_right = line.strip().split(' ')
left_image_path_list.append(left_right[0])
right_image_path_list.append(left_right[1])
similar_list.append(1)
将数据转化为np格式,方便以后的操作
left_image_path_list = np.asarray(left_image_path_list)
right_image_path_list = np.asarray(right_image_path_list)
similar_list = np.asarray(similar_list)
利用np.random.permutation将数据打乱,同时对应上标签
np.random.seed(10)
shuffle_indices = np.random.permutation(np.arange(len(similar_list)))
left_shuffled = left_image_path_list[shuffle_indices]
right_shuffled = right_image_path_list[shuffle_indices]
similar_shuffled = similar_list[shuffle_indices]
根据DEV_NUMBER设置训练集和交叉验证集
left_train, left_dev = left_shuffled[:DEV_NUMBER], left_shuffled[DEV_NUMBER:]
right_train, right_dev = right_shuffled[:DEV_NUMBER], right_shuffled[DEV_NUMBER:]
similar_train, similar_dev = similar_shuffled[:DEV_NUMBER], similar_shuffled[DEV_NUMBER:]
根据人名将图像转化为np格式,并保存在image_arr_list中
def vectorize_imgs(img_path_list):
image_arr_list = []
for img_path in img_path_list:
if os.path.exists(BASE_PATH + img_path):
img = Image.open(BASE_PATH + img_path)
img_arr = np.asarray(img, dtype='float32')
image_arr_list.append(img_arr)
else:
print(img_path)
return image_arr_list
产生batch数据集
def get_batch_image_path(left_train, right_train, similar_train, start):
end = (start + batch_size) % len(similar_train)
if start < end:
return left_train[start:end], right_train[start:end], similar_train[start:end], end
# 当 start > end 时,从头返回
return np.concatenate([left_train[start:], left_train[:end]]), \
np.concatenate([right_train[start:], right_train[:end]]), \
np.concatenate([similar_train[start:], similar_train[:end]]), \
end
batch数据集的np格式
def get_batch_image_array(batch_left, batch_right, batch_similar):
return np.asarray(vectorize_imgs(batch_left), dtype='float32') / 255., \
np.asarray(vectorize_imgs(batch_right), dtype='float32') / 255., \
np.asarray(batch_similar)[:, np.newaxis]
if __name__ == '__main__':
pass
///////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
3、model.py文件解读
这里主要实现SiameseNet网络,并定义损失函数
///////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
import tensorflow as tf
variables_dict = {
"hidden_Weights": tf.Variable(tf.truncated_normal([144, 128], stddev=0.1), name="hidden_Weights"),
"hidden_biases": tf.Variable(tf.constant(0.1, shape=[128]), name="hidden_biases")
}
class SIAMESE(object):
def siamesenet(self, input, reuse=False):
with tf.name_scope("model"):
with tf.variable_scope("conv1") as scope:
conv1 = tf.layers.conv2d(input, filters=64, kernel_size=[5, 5], strides=[1, 1],
padding='SAME', activation=tf.nn.relu, reuse=reuse, name=scope.name)
pool1 = tf.layers.max_pooling2d(conv1, pool_size=[3, 3], strides=[2, 2],
padding='SAME', name='pool1')
with tf.variable_scope("conv2") as scope:
conv2 = tf.layers.conv2d(pool1, filters=128, kernel_size=[5, 5], strides=[1, 1],
padding='SAME', activation=tf.nn.relu, reuse=reuse, name=scope.name)
pool2 = tf.layers.max_pooling2d(conv2, pool_size=[3, 3], strides=[2, 2],
padding='SAME', name='pool2')
with tf.variable_scope("conv3") as scope:
conv3 = tf.layers.conv2d(pool2, filters=256, kernel_size=[3, 3], strides=[1, 1],
padding='SAME', activation=tf.nn.relu, reuse=reuse, name=scope.name)
pool3 = tf.layers.max_pooling2d(conv3, pool_size=[3, 3], strides=[2, 2],
padding='SAME', name='pool3')
with tf.variable_scope("conv4") as scope:
conv4 = tf.layers.conv2d(pool3, filters=512, kernel_size=[3, 3], strides=[1, 1],
padding='SAME', activation=tf.nn.relu, reuse=reuse, name=scope.name)
pool4 = tf.layers.max_pooling2d(conv4, pool_size=[3, 3], strides=[2, 2],
padding='SAME', name='pool4')
with tf.variable_scope("conv5") as scope:
conv5 = tf.layers.conv2d(pool4, filters=16, kernel_size=[3, 3], strides=[1, 1],
padding='SAME', activation=tf.nn.relu, reuse=reuse, name=scope.name)
pool5 = tf.layers.max_pooling2d(conv5, pool_size=[3, 3], strides=[2, 2],
padding='SAME', name='pool5')
flattened = tf.contrib.layers.flatten(pool5)
with tf.variable_scope("local") as scope:
output = tf.nn.relu(tf.matmul(flattened, variables_dict["hidden_Weights"]) +
variables_dict["hidden_biases"], name=scope.name)
return output
def contrastive_loss(self, model1, model2, y):
with tf.name_scope("output"):
output_difference = tf.abs(model1 - model2)
W = tf.Variable(tf.random_normal([128, 1], stddev=0.1), name='W')
b = tf.Variable(tf.zeros([1, 1]) + 0.1, name='b')
y_ = tf.add(tf.matmul(output_difference, W), b, name='distance')
# CalculateMean loss
with tf.name_scope("loss"):
losses = tf.nn.sigmoid_cross_entropy_with_logits(labels=y, logits=y_)
loss = tf.reduce_sum(losses)
return model1, model2, y_, loss
/////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
4、train.py文件解读
/////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
import tensorflow as tf
from model import SIAMESE
from dataset import *
import logging
logging.basicConfig(level=logging.DEBUG,
format="%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s",
datefmt='%b %d %H:%M')
with tf.name_scope("in"):
left = tf.placeholder(tf.float32, [None, 72, 72, 3], name='left')
right = tf.placeholder(tf.float32, [None, 72, 72, 3], name='right')
with tf.name_scope("similarity"):
label = tf.placeholder(tf.int32, [None, 1], name='label') # 1 if same, 0 if different
label = tf.to_float(label)
left_output = SIAMESE().siamesenet(left, reuse=False)
print(left_output.shape)
right_output = SIAMESE().siamesenet(right, reuse=True)
model1, model2, distance, loss = SIAMESE().contrastive_loss(left_output, right_output, label)
global_step = tf.Variable(0, trainable=False)
train_step = tf.train.AdamOptimizer(0.0001).minimize(loss, global_step=global_step)
# saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
saver = tf.train.Saver(tf.global_variables(), max_to_keep=20)
# saver.restore(sess, 'checkpoint_trained/model_3.ckpt')
# setup tensorboard
tf.summary.scalar('step', global_step)
tf.summary.scalar('loss', loss)
for var in tf.trainable_variables():
tf.summary.histogram(var.op.name, var)
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter('train.log', sess.graph)
left_dev_arr, right_dev_arr, similar_dev_arr = get_batch_image_array(left_dev, right_dev, similar_dev)
# train iter
idx = 0
for i in range(FLAGS.train_iter):
batch_left, batch_right, batch_similar, idx = get_batch_image_path(left_train, right_train, similar_train, idx)
batch_left_arr, batch_right_arr, batch_similar_arr = \
get_batch_image_array(batch_left, batch_right, batch_similar)
_, l, summary_str = sess.run([train_step, loss, merged],
feed_dict={left: batch_left_arr, right: batch_right_arr, label: batch_similar_arr})
writer.add_summary(summary_str, i)
logging.info("\r#%d - Loss" % i, l)
if (i + 1) % FLAGS.validation_step == 0:
val_distance = sess.run([distance],
feed_dict={left: left_dev_arr, right: right_dev_arr, label: similar_dev_arr})
logging.info(np.average(val_distance))
if i % FLAGS.step == 0 and i != 0:
saver.save(sess, "checkpoint/model_%d.ckpt" % i