三步教你搭建给黑白照片上色的神经网络 !(附代码)

来源:量子位
本文长度为7970字,建议阅读8分钟
本文为你介绍通过搭建神经网络,来给黑白照片上色的教程。

深度学习云平台FloydHub最近在官方博客上发了一篇通过搭建神经网络,来给黑白照片上色的教程,在Twitter和Reddit论坛上都广受好评。
FloydHub是个YC孵化的创业公司,号称要做深度学习领域的Heroku。它在GPU系统上预装了TensorFlow和很多其他的机器学习工具,用户可以按时长租用,训练自己的机器学习模型。免费版支持1个项目、每月20小时GPU时长、10G存储空间,用上色项目练个手足够了。
进入正题~
以下内容编译自FloydHub官方博客:
我将分三个步骤展示如何打造你自己的着色神经网络。
第一部分介绍核心逻辑。我们将用40行代码来构建一个简单的神经网络,叫做“Alpha”版本着色机器人。这个代码里没有太多技巧,但是有助于熟悉语法。
下一步是创建一个具备泛化能力的神经网络,叫做“Beta”版本,它能够对以前没见过的图像进行着色。
最后,将神经网络与分类器相结合,得到最终版本。Inception Resnet V2是训练120万张图像后得到的神经网络,我们使用了该模型。为了使着色效果更加吸引人,我们使用了来自素材网站Unsplash的人像集,来训练这个神经网络。
Alpha版本机器人的Jupyter Notebook代码、上述三个版本实现代码的FloydHub和GitHub地址,以及在FloydHub的GPU云上运行的所有实验代码,都在文末。
核心逻辑
在本节中,我将概述如何渲染图像、数字颜色的基础知识以及神经网络的主要逻辑。
黑白图像可以在像素网格中表示。每个像素有对应于其亮度的值,取值范围为0 - 255,从黑色到白色。

图像与数字的对应
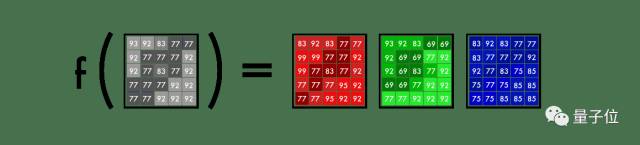
彩色图像可以分为三层,分别是红色层、绿色层和蓝色层。直观上,你可能会认为植物只存在于绿色层,但事实可能与你的直觉相反。想象一下,将白色背景上的绿叶分成三个图层。
如下图所示,叶子在三个图层中都存在。这些层不仅可以确定颜色,还确定了亮度。

三个通道的绿叶
例如,为了得到白色这个颜色,你需要将所有颜色均匀分布。添加等量红色和蓝色后,绿色会变得更亮。因此,彩色图像使用三个通道来编码颜色和对比度:

RGB调色
就像黑白图像一样,彩色图像中每个图层值的范围也是0 – 255,值为0意味着该图层中没有颜色。如果在所有颜色图层中该值都为0,则该图像像素为黑色。
神经网络能建立输入和输出之间的关系。更准确地说,着色任务就是让网络找到连接灰度图像与彩色图像的特征。
因此,着色神经网络,就是要寻找将灰度值网格连接到三色网格的特征。
Alpha版本
我们从简单版本开始,建立一个能给女性脸部着色的神经网络。这样,当添加新特征时,你可以熟悉已有模型的核心语法。
只需要40行代码,就能实现下图所示的转换。中间图像是用神经网络完成的,右边图像是原始的彩色照片。这个网络使用了相同图像做训练和测试,在beta版本中还会再讲这一点。

1、颜色空间
首先,使用一种能改变颜色通道的算法,从RGB到Lab。其中,L表示亮度,a和b分别表示颜色光谱,绿-红和蓝-黄。
如下所示,Lab编码的图像具有一个灰度层,并将三个颜色层压成两层,这意味着在最终预测中可以使用原始灰度图像。此外,我们只需预测两个通道。

△ Lab编码图像
科学研究表明,人类眼睛中有94%细胞确定着亮度,只有6%细胞是用来感受颜色的。如上图所示,灰度图像比彩色层更加清晰。这是我们在最终预测中保留灰度图像的另一个原因。
2、从黑白到彩色
最终预测应该是这样的:向网络输入灰度层(L),然后预测Lab中的两个颜色层ab。要创建最终输出的彩色图像,我们需要把输入的灰度(L)图像和输出的a、b层加在一起,创建一个Lab图像。

图像转化函数
我们使用卷积过滤器将一层变成两层,可以把它们看作3D眼镜中的蓝色和红色滤镜。每个过滤器确定能从图片中看到的内容,可以突出或移除某些东西,来从图片中提取信息。这个网络可以从过滤器中创建新图像,也可以组合多个过滤器形成新图像。
卷积神经网络能自动调整每个滤波器,以达到预期结果。我们将从堆叠数百个滤波器开始,然后将它们缩小成两层,即a层和b层。
在详细介绍其工作原理之前,先介绍代码。
3、在FloydHub上部署代码
如果你刚接触FloydHub,请看这个2分钟安装教程(https://www.floydhub.com/),以及手把手教学指南(https://blog.floydhub.com/my-first-weekend-of-deep-learning/),然后就可以开始在GPU云上训练深度学习模型了。
4、Alpha版本
安装好FloydHub后,执行以下命令:
git clone https://github.com/emilwallner/Coloring-greyscale-images-in-Keras打开文件夹并启动FloydHub。
cd Coloring-greyscale-images-in-Keras/floydhub floyd init colornet
FloydHub Web控制台将在浏览器中打开,系统会提示你创建一个名为colornet的FloydHub新项目。完成后,返回终端并执行相同的初始化命令。
floyd init colornet
接下来执行本项目任务。
floyd run --data emilwallner/datasets/colornet/2:data --mode jupyter --tensorboard对于这个任务的一些简单说明:
-
我们在FloydHub的数据集目录(—data emilwallner / datasets / colornet / 2:data)中载入了一个公开数据集,你在FloydHub上查看并使用此数据集和许多其他公开数据集;
-
启用了Tensorboard (—tensorboard);
-
在Jupyter Notebook下运行代码 (—mode jupyter);
-
如果能使用GPU,你还可以将GPU (—gpu)添加到命令中,这样运行速度能提高50倍。
在FloydHub网站上的选项“Jobs”下,点击Jupyter Notebook可链接到以下文件:floydhub / Alpha version / working_floyd_pink_light_full.ipynb,打开它并摁下shift+enter。
逐渐增大epoch值,体会神经网络是如何学习的。
model.fit(x=X, y=Y, batch_size=1, epochs=1)
开始时把epoch设置为1,逐渐增加到10、100、5500、1000和3000。epoch值表示神经网络从图像中学习的次数。在训练神经网络的过程中,你可以在主文件夹中找到这个图像img_result.png。
# Get images image = img_to_array(load_img('woman.png')) image = np.array(image, dtype=float) # Import map images into the lab colorspace X = rgb2lab(1.0/255*image)[:,:,0] Y = rgb2lab(1.0/255*image)[:,:,1:] Y = Y / 128 X = X.reshape(1, 400, 400, 1) Y = Y.reshape(1, 400, 400, 2) model = Sequential() model.add(InputLayer(input_shape=(None, None, 1))) # Building the neural network model = Sequential() model.add(InputLayer(input_shape=(None, None, 1))) model.add(Conv2D(8, (3, 3), activation='relu', padding='same', strides=2)) model.add(Conv2D(8, (3, 3), activation='relu', padding='same')) model.add(Conv2D(16, (3, 3), activation='relu', padding='same')) model.add(Conv2D(16, (3, 3), activation='relu', padding='same', strides=2)) model.add(Conv2D(32, (3, 3), activation='relu', padding='same')) model.add(Conv2D(32, (3, 3), activation='relu', padding='same', strides=2)) model.add(UpSampling2D((2, 2))) model.add(Conv2D(32, (3, 3), activation='relu', padding='same')) model.add(UpSampling2D((2, 2))) model.add(Conv2D(16, (3, 3), activation='relu', padding='same')) model.add(UpSampling2D((2, 2))) model.add(Conv2D(2, (3, 3), activation='tanh', padding='same')) # Finish model model.compile(optimizer='rmsprop',loss='mse') #Train the neural network model.fit(x=X, y=Y, batch_size=1, epochs=3000) print(model.evaluate(X, Y, batch_size=1)) # Output colorizations output = model.predict(X) output = output * 128 canvas = np.zeros((400, 400, 3)) canvas[:,:,0] = X[0][:,:,0] canvas[:,:,1:] = output[0] imsave("img_result.png", lab2rgb(cur)) imsave("img_gray_scale.png", rgb2gray(lab2rgb(cur)))
用FloydHub命令来运行网络:
floyd run --data emilwallner/datasets/colornet/2:data --mode jupyter --tensorboard
5、技术说明
与其他视觉网络不同,它的主要区别在于像素位置的重要性。在着色网络中,图像的分辨率或比例在整个网络中保持不变。而在其他网络中,越靠近最后一层,图像变得越扭曲。
分类网络中的最大池化层增加了信息密度,但也可能导致图像失真。它只对信息进行估值,而未考虑到图像布局。在着色网络中,我们将步幅改为2,每次运算使宽度和高度减半。这样,不但增加了信息密度,也不会使图像扭曲。

两者差异在于上采样层和图像比例保持方面。而分类网络只关心最终的分类正确率,因此随着网络深入,它会不断减小图像的分辨率和质量。
但是,着色网络的图像比例保持不变。这是通过添加空白填充来实现的,否则每个卷积层将削减图像,实现代码为:padding =’same’。
要使图像的分辨率加倍,着色网络使用了上采样层,更多信息见:https://keras.io/layers/convolutional/#upsampling2d。
for filename in os.listdir('/Color_300/Train/'): X.append(img_to_array(load_img('/Color_300/Test'+filename)))
这个for循环首先计算了目录中的所有文件名,然后遍历图像目录,并将图像转换为像素数组,最后将其组合成一个大型矢量。
datagen = ImageDataGenerator( shear_range=0.2, zoom_range=0.2, rotation_range=20, horizontal_flip=True)
在ImageDataGenerator中,我们还修改了图像生成器的参数。这样,图像永远不会相同,以改善学习效果。参数shear_range是指图像向左或向右的倾斜程度,其他参数不需要加以说明。
batch_size = 50 def image_a_b_gen(batch_size): for batch in datagen.flow(Xtrain, batch_size=batch_size): lab_batch = rgb2lab(batch) X_batch = lab_batch[:,:,:,0] Y_batch = lab_batch[:,:,:,1:] / 128 yield (X_batch.reshape(X_batch.shape+(1,)), Y_batch)
我们使用了文件夹Xtrain中的图像,根据之前设置来生成图像。然后我们提取X_batch中的黑白层和两个颜色层的两种颜色。
model.fit_generator(image_a_b_gen(batch_size), steps_per_epoch=1, epochs=1000)
拥有越高性能的GPU,则可以设置越大的batch_size值。根据现有硬件,我们设置了每批次输入50-100张图像。参数steps_per_epoch是通过把训练图像的数量除以批次大小得出的。例如,有100张图像且批次大小为50,则steps_per_epoch值为2。参数epoch决定网络中所有图像的训练次数。在Tesla K80 GPU上,大约需要11小时才能完成对1万张图像的21次训练。
6、训练心得
-
先进行多次小批次实验,再尝试大批次实验。即使经过20-30次实验,我仍然发现很多错误。程序能运行并不意味着它能工作。神经网络中的问题通常比传统编程遇到的Bug更为麻烦。
-
多样化的数据集会使着色效果呈现棕色。如果数据集中图像比较相似,不需要设计很复杂的架构,就可以得到一个良好效果,但是其泛化能力十分糟糕。
-
重视图像形状的统一性。每张图像的分辨率必须是准确的,且在整个网络中保持成比例。开始时,所使用的图像分辨率为300,将它减半三次后分别得到150、75和35.5。因此,就丢失了半个像素,这导致了很多问题,后来才意识到应该使用4、8、16、32、64、256等这种能被2整除的数。
-
创建数据集。请禁用.DS_Store文件,不然会产生很多麻烦;大胆创新,最后我用Chrome控制台脚本和扩展程序来下载文件;备份原始文件并构建清理脚本。
最终版本
最终版本的着色神经网络有四个组成部分。我们将之前的网络拆分成编码器和解码器,在这两者之间还添加了一个融合层。关于分类网络的基本教程,可参考:https://cs231n.github.io/classification/。
Inception resnet v2是目前最强大的分类器之一,使用了120万张图像来训练该网络。我们提取了它的分类层,并将其与编码器的输出进行合并。因此,输入数据传给编码器的同时,也并行传输到resnet v2网络的分类层中。更多信息,请参考原论文:https://github.com/baldassarreFe/deep-koalarization。

信息并行传输示意图
这个网络通过将分类器的学习效果迁移到着色网络上,可更好理解图片中的内容。因此,这样使得网络能够把目标表征与着色方案相匹配。
以下是在一些验证图像上的着色效果,仅使用20张图像来训练网络。

大多数图像的着色效果不好,但是由于验证集中有2500张图像,我设法找到了一些良好的着色图像。在更多图像上进行训练可以获得更为稳定的结果,但是大部分都呈现棕色色调。这两个链接贴出了运行试验的完整列表,包括验证图像(https://www.floydhub.com/emilwallner/projects/color) (https://www.floydhub.com/emilwallner/projects/color_full)。
本文的神经网络设计参考了这篇论文(https://github.com/baldassarreFe/deep-koalarization/blob/master/report.pdf),以及我在Keras中的一些理解。
注意:在下面代码中,我把Keras的序列模型变换成相应的函数调用。
# Get images
X = []
for filename in os.listdir('/data/images/Train/'):
X.append(img_to_array(load_img('/data/images/Train/'+filename)))
X = np.array(X, dtype=float)
Xtrain = 1.0/255*X
#Load weights
inception = InceptionResNetV2(weights=None, include_top=True)
inception.load_weights('/data/inception_resnet_v2_weights_tf_dim_ordering_tf_kernels.h5')
inception.graph = tf.get_default_graph()
embed_input = Input(shape=(1000,))
#Encoder
encoder_input = Input(shape=(256, 256, 1,))
encoder_output = Conv2D(64, (3,3), activation='relu', padding='same', strides=2)(encoder_input)
encoder_output = Conv2D(128, (3,3), activation='relu', padding='same')(encoder_output)
encoder_output = Conv2D(128, (3,3), activation='relu', padding='same', strides=2)(encoder_output)
encoder_output = Conv2D(256, (3,3), activation='relu', padding='same')(encoder_output)
encoder_output = Conv2D(256, (3,3), activation='relu', padding='same', strides=2)(encoder_output)
encoder_output = Conv2D(512, (3,3), activation='relu', padding='same')(encoder_output)
encoder_output = Conv2D(512, (3,3), activation='relu', padding='same')(encoder_output)
encoder_output = Conv2D(256, (3,3), activation='relu', padding='same')(encoder_output)
#Fusion
fusion_output = RepeatVector(32 * 32)(embed_input)
fusion_output = Reshape(([32, 32, 1000]))(fusion_output)
fusion_output = concatenate([encoder_output, fusion_output], axis=3)
fusion_output = Conv2D(256, (1, 1), activation='relu', padding='same')(fusion_output)
#Decoder
decoder_output = Conv2D(128, (3,3), activation='relu', padding='same')(fusion_output)
decoder_output = UpSampling2D((2, 2))(decoder_output)
decoder_output = Conv2D(64, (3,3), activation='relu', padding='same')(decoder_output)
decoder_output = UpSampling2D((2, 2))(decoder_output)
decoder_output = Conv2D(32, (3,3), activation='relu', padding='same')(decoder_output)
decoder_output = Conv2D(16, (3,3), activation='relu', padding='same')(decoder_output)
decoder_output = Conv2D(2, (3, 3), activation='tanh', padding='same')(decoder_output)
decoder_output = UpSampling2D((2, 2))(decoder_output)
model = Model(inputs=[encoder_input, embed_input], outputs=decoder_output)
#Create embedding
def create_inception_embedding(grayscaled_rgb):
grayscaled_rgb_resized = []
for i in grayscaled_rgb:
i = resize(i, (299, 299, 3), mode='constant')
grayscaled_rgb_resized.append(i)
grayscaled_rgb_resized = np.array(grayscaled_rgb_resized)
grayscaled_rgb_resized = preprocess_input(grayscaled_rgb_resized)
with inception.graph.as_default():
embed = inception.predict(grayscaled_rgb_resized)
return embed
# Image transformer
datagen = ImageDataGenerator(
shear_range=0.4,
zoom_range=0.4,
rotation_range=40,
horizontal_flip=True)
#Generate training data
batch_size = 20
def image_a_b_gen(batch_size):
for batch in datagen.flow(Xtrain, batch_size=batch_size):
grayscaled_rgb = gray2rgb(rgb2gray(batch))
embed = create_inception_embedding(grayscaled_rgb)
lab_batch = rgb2lab(batch)
X_batch = lab_batch[:,:,:,0]
X_batch = X_batch.reshape(X_batch.shape+(1,))
Y_batch = lab_batch[:,:,:,1:] / 128
yield ([X_batch, create_inception_embedding(grayscaled_rgb)], Y_batch)
#Train model
tensorboard = TensorBoard(log_dir="/output")
model.compile(optimizer='adam', loss='mse')
model.fit_generator(image_a_b_gen(batch_size), callbacks=[tensorboard], epochs=1000, steps_per_epoch=20)
#Make a prediction on the unseen images
color_me = []
for filename in os.listdir('../Test/'):
color_me.append(img_to_array(load_img('../Test/'+filename)))
color_me = np.array(color_me, dtype=float)
color_me = 1.0/255*color_me
color_me = gray2rgb(rgb2gray(color_me))
color_me_embed = create_inception_embedding(color_me)
color_me = rgb2lab(color_me)[:,:,:,0]
color_me = color_me.reshape(color_me.shape+(1,))
# Test model
output = model.predict([color_me, color_me_embed])
output = output * 128
# Output colorizations
for i in range(len(output)):
cur = np.zeros((256, 256, 3))
cur[:,:,0] = color_me[i][:,:,0]
cur[:,:,1:] = output[i]
imsave("result/img_"+str(i)+".png", lab2rgb(cur))用FloydHub命令来运行最终版本神经网络:
floyd run --data emilwallner/datasets/colornet/2:data --mode jupyter --tensorboard技术说明
当你要实现模型连接或模型融合时,Keras的函数调用功能是最佳选择。

模型融合层
首先,要下载inception resnet v2网络并加载权重。由于要并行使用两个模型,因此必须指定当前要使用哪个模型。这个可通过Keras的后端Tensorflow来完成。
inception = InceptionResNetV2(weights=None, include_top=True)
inception.load_weights('/data/inception_resnet_v2_weights_tf_dim_ordering_tf_kernels.h5')
inception.graph = tf.get_default_graph()批处理方法中使用了调整后的图像,把它们变成黑白图像,并在inception resnet模型上运行。
grayscaled_rgb = gray2rgb(rgb2gray(batch))
embed = create_inception_embedding(grayscaled_rgb)首先,要调整图像分辨率以适应inception模型;然后根据模型,使用预处理程序来规范化像素和颜色值;最后,在inception网络上运行并提取模型最后一层的权重。
def create_inception_embedding(grayscaled_rgb):
grayscaled_rgb_resized = []
for i in grayscaled_rgb:
i = resize(i, (299, 299, 3), mode='constant')
grayscaled_rgb_resized.append(i)
grayscaled_rgb_resized = np.array(grayscaled_rgb_resized)
grayscaled_rgb_resized = preprocess_input(grayscaled_rgb_resized)
with inception.graph.as_default():
embed = inception.predict(grayscaled_rgb_resized)
return embed再讲下生成器。对于每个批次,我们按照下列格式生成20张图像,在Tesla K80 GPU上大约要运行一个小时。基于该模型,每批次最多可输入50张图像,且不产生内存溢出。
yield ([X_batch, create_inception_embedding(grayscaled_rgb)], Y_batch)
代码23这与本项目中着色模型的格式相匹配。
model = Model(inputs=[encoder_input, embed_input], outputs=decoder_output)encoder_input会输入到编码器模型中;接着,编码器模型的输出会与融合层中的embed_input相融合;然后,这个融合输出会作为解码器模型的输入;最终,解码器模型会输出预测结果decode_output。
fusion_output = RepeatVector(32 * 32)(embed_input)
fusion_output = Reshape(([32, 32, 1000]))(fusion_output)
fusion_output = concatenate([fusion_output, encoder_output], axis=3)
fusion_output = Conv2D(256, (1, 1), activation='relu')(fusion_output)在融合层中,首先将1000类输出层乘以1024(即32×32),这样就从inception模型的最后一层得到了1024行数据;接着,把2D重构成3D得到一个具有1000个类别对象的32x32网格;然后,将它与编码器模型的输出相连;最后,应用一个带有254个1X1内核的卷积网络,得到了融合层的最终输出。
一些思考
1.不要逃避难懂的术语。我花了三天时间去搜索在Keras该如何实现“融合层”。因为这听起来很复杂,我不想面对这个问题,而是试图找到现成代码。
2.多在网上请教他人。在Keras论坛中,我提出的问题没人回答,同时Stack Overflow删除了我的提问。但是,通过分解成小问题去请教他人,这迫使我进一步理解问题,并更快解决问题。
3.多发邮件请教。虽然论坛可能没人回应,人们关心你能否直接与他们联系。在Skype上与你不认识的研究人员一起探讨问题,这听起来很有趣。
4.在解决“融合层”问题之前,我决定构建出所有组件。以下是分解融合层的几个实验(https://www.floydhub.com/emilwallner/projects/color/24/code/Experiments/transfer-learning-examples)。
5.我以为某些代码能够起作用,但是在犹豫是否要运行。虽然我知道核心逻辑是行得通的,但我不认为它会奏效。经过一阵纠结,我还是选择运行。运行完模型的第一行代码后,就开始报错;四天后,一共产生几百个报错,我也做了数千个Google搜索,模型依旧停留在“Epoch 1/22”。
下一步计划
图像着色是一个极其有趣的问题。这既是一个科学问题,也是一个艺术问题。我写下这篇文章,希望你能从中有所启发,以加快在图像着色方面的研究。以下是一些建议:
1.微调另一个预训练好的模型;
2.使用不同的数据集;
3.添加更多图片来提高网络的正确率;
4.在RGB颜色空间中构建一个放大器。构建一个与着色网络类似的模型,将深色调的着色图像作为输入,它能微调颜色以输出合适的着色图像;
5.进行加权分类;
6.应用一个分类神经网络作为损失函数。网络中错误分类的图片有一个相应误差,探究每个像素对该误差的贡献度。
7.应用到视频中。不要太担心着色效果,而是要关注如何使图像切换保持协调。你也可以通过平铺多张小图像来处理大型图像。
当然,你也可以尝试用我贴在FloydHub上的三种着色神经网络,来给你的黑白图像着色。
1.对于Alpha版本,只需将你的图片分辨率调成400x400像素,把名称改为woman.jpg,并替换原有文件。
2.对于Beta版本和最终版本,在你运行FloydHub命令之前,要将你的图片放入Test文件夹。当Notebook运行时,你也可以通过命令行直接上传到Test文件夹。要注意,这些图像的分辨率必须是256x256像素。此外,你也可以上传彩色测试图像集,因为这个网络会自动把它们转换为黑白图像。
相关链接
1.Alpha版本机器人的Jupyter Notebook代码:
https://www.floydhub.com/emilwallner/projects/color/43/code/Alpha-version/alpha_version.ipynb
2.三个版本实现代码 - Floydhub传送门:
https://www.floydhub.com/emilwallner/projects/color/43/code
3.三个版本实现代码 - Github传送门:
https://github.com/emilwallner/Coloring-greyscale-images-in-Keras
4.所有实验代码:
https://www.floydhub.com/emilwallner/projects/color/jobs
5.作者Twitter:emilwallner
https://twitter.com/EmilWallner
6.教程原文:
https://blog.floydhub.com/colorizing-b&w-photos-with-neural-networks/
编辑:王璇
校对:谭佳瑶
为保证发文质量、树立口碑,数据派现设立“错别字基金”,鼓励读者积极纠错。
若您在阅读文章过程中发现任何错误,请在文末留言,或到后台反馈,经小编确认后,数据派将向检举读者发8.8元红包。
同一位读者指出同一篇文章多处错误,奖金不变。不同读者指出同一处错误,奖励第一位读者。
感谢一直以来您的关注和支持,希望您能够监督数据派产出更加高质的内容。
