1.WAV文件格式分析
仿真中读出的wav文件信息如下Fs=4.41kHz,nBits = 16 bit/sample
%% 读取音频文件
[wav_data, Fs, nBits, opt] = wavread('s001.wav');
wav_data = wav_data';
sound(wav_data,Fs);
在Windows环境下,大部分的多媒体文件都依循着一种结构来存放信息,这种结构称为"资源互换文件格式"(Resources lnterchange File Format),简称RIFF。例如声音的WAV文件、视频的AVI文件等等均是由此结构衍生出来的。RIFF可以看做是一种树状结构,其基本构成单位为chunk,犹如树状结构中的节点,每个chunk由"辨别码"、"数据大小"及"数据"所组成。
RIFF(标识符) | 数据大小 | 格式类型(WAVE) | fmt | sizeof(PCMWAVEFORMAT)
| PCMWAVEFORMAT | data | 声音数据大小 | 声音数据
WAVE文件是非常简单的一种RIFF文件,它的格式类型为"WAVE"。RIFF块包含两个子块,这两个子块的ID分别是"fmt"和"data",其中"fmt"子块由结构PCMWAVEFORMAT所组成,其子块的大小就是sizeofof(PCMWAVEFORMAT),数据组成就是PCMWAVEFORMAT结构中的数据。
//PCMWAVEFORMAT
Typedef struct
...{
WAVEFORMAT wf; /波形格式;
WORD wBitsPerSample; //WAVE文件的采样大小;
} PCMWAVEFORMAT;
//WAVEFORMAT结构定义如下:
typedef struct
...{
WORD wFormatag; //编码格式,包括WAVE_FORMAT_PCM,WAVEFORMAT_ADPCM等
WORD nChannls; //声道数,单声道为1,双声道为2;
DWORD nSamplesPerSec; //采样频率;
DWORD nAvgBytesperSec; //每秒的数据量;
WORD nBlockAlign; //块对齐;
} WAVEFORMAT;
总结起来就是说wave文件自己在文件头部保存了很多格式,包括声道数目,采样频率,每秒的数据量,快对齐,编码格式等等,因此在matlab中读出音频文件就直接读出了该文件的各种信息...
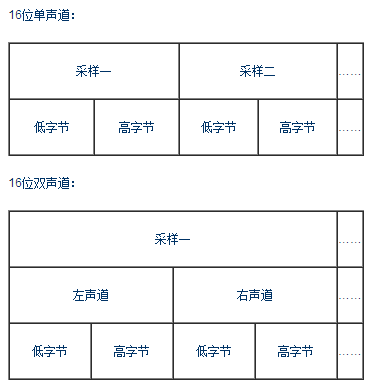
"data"子块包含WAVE文件的数字化波形声音数据,其存放格式依赖于"fmt"子块中wFormatTag成员指定的格式种类,在多声道WAVE文件中,样本是交替出现的。如16bit的单声道WAVE文件和双声道WAVE文件的数据采样格式分别如图所示:
2.预加重高频
说语音信号的预处理。预处理包括预加重和加窗分帧。
预加重,其目的是为了对语音的高频部分进行加重,去除口唇辐射的影响,增加语音的高频分辨,使得低频部分到高频部分的频谱平稳,使得低频到高频的信噪比是一样的。
一般是通过传递函数是一阶FIR高通数字滤波器来实现。设第n时刻的语音采样值为x(n),经过预加重处理后的结果是y(n)=x(n)-ax(n-1),其中a为预加重系数,一般是0.9~1.0之间,通常取0.98。
预加重的实现:
matlab:y=filter([1 -1],[1 -0.98],x);
加窗分帧。语音信号是一种随时间而变化的信号,主要分为浊音和清音两大类。浊音的基因周期、清浊音信号幅度和声道参数等都随时间而缓慢变化。可以近似认为在一小段时间里语音信号近似不变,即语音信号具有短时平稳性。之所以具有短时平稳性,我们就可以把语音信号分成一些短段来进行处理。一般每秒的帧数是33~100帧。一般帧之间都有重叠,大多数是50%。帧长一般是10ms到30ms。常见的窗函数主要有矩形窗、汉明窗(hamming)、汉宁窗(hanning)等。
%% 短时傅里叶变换 选取5-50ms 在这里选择30ms
frame_time = 15e-3;
frame_N = floor(frame_time * Fs);
window = frame_N;
noverlap = floor(window/2);
nfft = window;
x = wav_data(1.2*Fs:2*Fs);
[S,F,T,P] = spectrogram(x,window,noverlap,nfft,Fs);
figure(1)
surf(T,F./1000,10*log10(P),'edgecolor','none'); axis tight;
view(0,90);
xlabel('Time (Seconds)'); ylabel('kHz');
%% 预加重高频
pre_a = -0.9975;
h = [1 pre_a];
y = filter(h,1,x);
y = x;
%figure(2)
%freqz(h(1),h(2));
figure(3)
[S,F,T,P] = spectrogram(y,window,noverlap,nfft,Fs);
surf(T,F./1000,10*log10(P),'edgecolor','none'); axis tight;
view(0,90);
xlabel('Time (Seconds)'); ylabel('kHz');
3.OLA算法
音频最初默认按50%重叠进行分段来做短时傅里叶变换,如果要加快语速,就要把加多重叠部分..
function y_ola = ola(input,frame_N,frame_prelag,scale)
frame_num = floor(length(input)/frame_prelag)-1;
frame = zeros(frame_num,frame_N);
myhamming = zeros(1,frame_N);
for i = 0:frame_N-1
myhamming(i+1) = 0.5*(1.0-cos(2.0*pi*i/(frame_N-1)));
end
for i = 1:frame_num
% frame(i,:) = input((i-1)*frame_prelag+1:(i-1)*frame_prelag+frame_N).*hamming(frame_N)';
frame(i,:) = input((i-1)*frame_prelag+1:(i-1)*frame_prelag+frame_N).*myhamming;
end
frame_postlag = floor(scale*frame_prelag);
y_ola = zeros(1,floor(length(input)*scale));
for i = 1:frame_num-1
y_ola((i-1)*frame_postlag+1:(i-1)*frame_postlag+frame_N) = ...
y_ola((i-1)*frame_postlag+1:(i-1)*frame_postlag+frame_N) ...
+ frame(i,:);
end
extra = length(y_ola((frame_num-1)*frame_postlag+1:end));
if extra<=frame_N
y_ola((frame_num-1)*frame_postlag+1:end) = ...
frame(frame_num,1:length(y_ola((frame_num-1)*frame_postlag+1:end)));
else
y_ola((frame_num-1)*frame_postlag+1:(frame_num-1)*frame_postlag+frame_N) = ...
y_ola((frame_num-1)*frame_postlag+1:(frame_num-1)*frame_postlag+frame_N) ...
+ frame(frame_num,:);
end