python数据可视化:使用dash给博客制作一个dashboard
项目部署在:https://ffzs-blog-dashboard.herokuapp.com/
项目代码在:https://github.com/ffzs/dash_blog_dashboard
1.dashboard
仪表板通常提供与特定目标或业务流程相关的关键绩效指标(KPI)的概览。另一方面,“仪表板”具有“进度报告”或“报告”的另一个名称。
“仪表板”通常显示在网页上,该网页链接到允许报告不断更新的数据库。例如,制造仪表板可以显示与生产率相关的数字,例如制造的零件数量,或每小时失败的质量检查的数量。同样,人力资源仪表板可能会显示与员工招聘,保留和组成相关的数字,例如,或平均天数或每次招聘成本。
2.功能确定
写之前先确定一些要实现的功能:
2.1. 博客基本数据跟踪

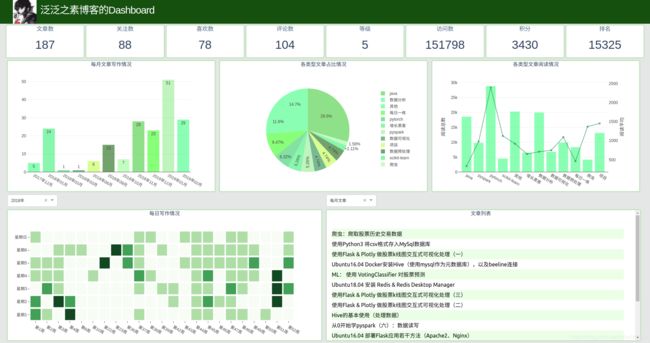
上图中的博客中的数据进行实时跟踪,且1分钟一刷新一次(之前用10秒,ip被封了。。。。),将这些数据横向放在一个row里,博客名称和头像放在页头。
实现效果如下:

2.2. 图表确定
2.2.1 展示每月写作情况的柱状图
其实就是博客上下面的数据:
2.2.2 展示不同类型文章的饼图
这里我对我文章类型重新划分了类型,博客上划分的有点乱,而且我确定了每篇文章只有一个类型, 具体代码如下:
def get_type(title):
the_type = '其他'
article_types = ['项目', 'pytorch', 'flask', 'scikit-learn', 'pyspark', '数据预处理', '每日一练', '数据分析', '爬虫',
'数据可视化', 'java', '增长黑客']
for article_type in article_types:
if article_type in title:
the_type = article_type
break
return the_type
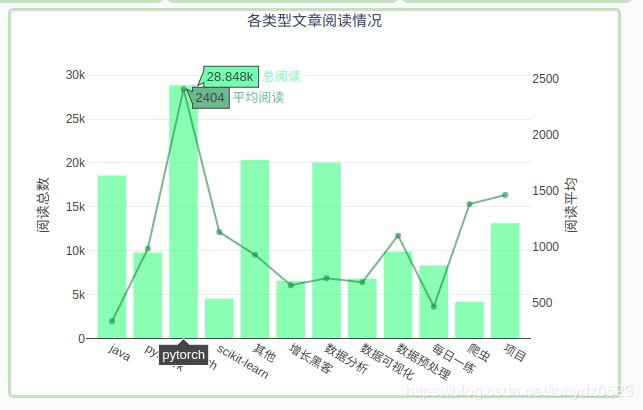
2.2.3 各类文章的总/平均阅读情况
文章的阅读情况是作者比较关系的数据,这里用柱状图展示没类文章总的阅读数,用折线图展示没类文章平均阅读情况:
2.2.4 用热图展示每日写作情况
通过颜色的深浅表示当天发布文章的数量, 通过下拉菜单选择年份:
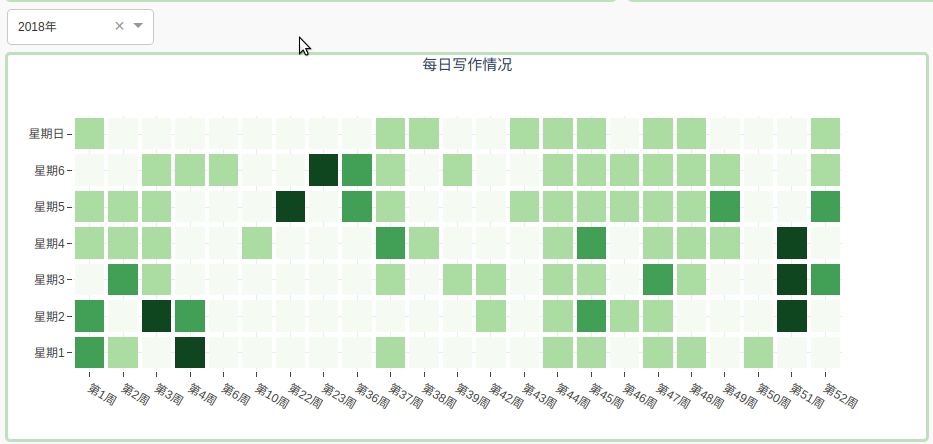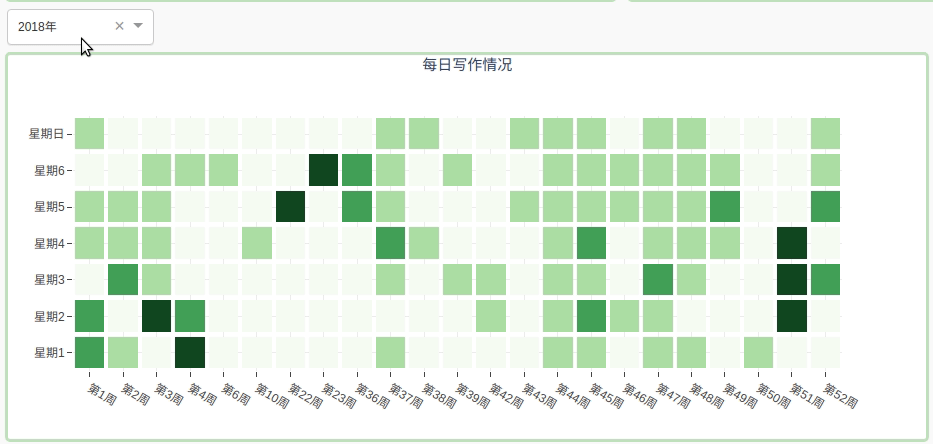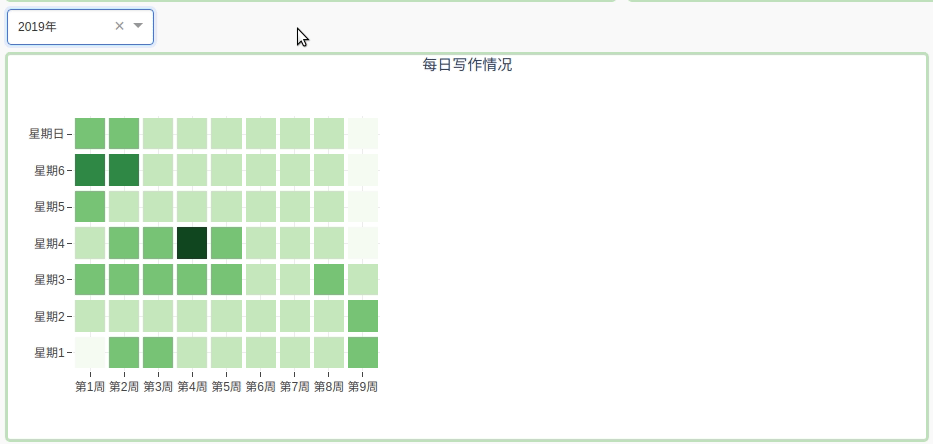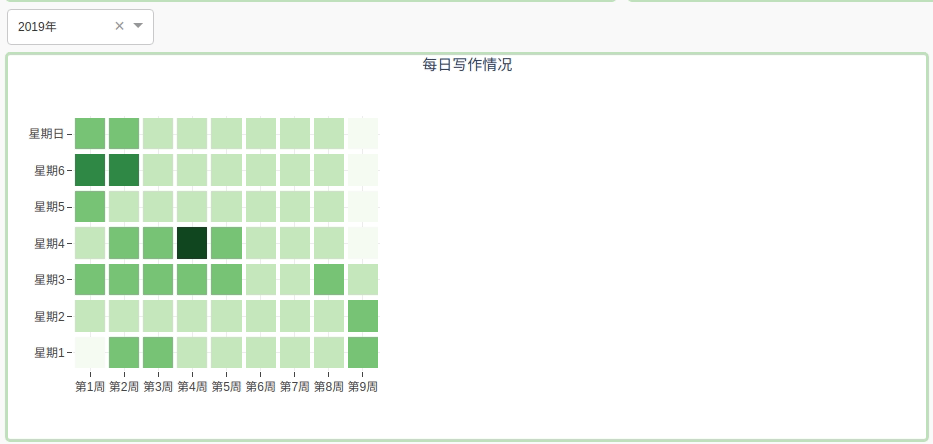
这个图是不是看着很眼熟。。

其实就是模仿gayhub的样式。
2.2.5 文章列表
显示文章的标题,点击跳转到相应网页,关联图片,通过点击图表对文章显示做选择:

2.2.6 色调选择
为啥用绿色?有如下几个原因:
- 春天快来了,万物复苏,动物们又到了交。。。。。反正就是有生机
- 模仿github的热图样式
- 要想生活过得去。。。
请原谅我的不正经[滑稽]
3 数据获取
数据获取主要分两个部分:基本数据获取(1分钟刷新一次),文章数据获取(1小时刷新一次)
3.1 基本数据获取
博客没有api,只能自己爬取,注意不要访问频率太高,会封ip
代码如下:
def get_info():
headers = {
'User-Agent': 'Mozilla/5.0 (MSIE 10.0; Windows NT 6.1; Trident/5.0)',
'referer': 'https: // passport.csdn.net / login',
}
url = random.choice(blog_list)
try:
resp = requests.get(url, headers=headers)
now = dt.datetime.now().strftime("%Y-%m-%d %X")
soup = BeautifulSoup(resp.text, 'lxml')
head_img = soup.find('div', class_='avatar-box d-flex justify-content-center flex-column').find('a').find('img')['src']
author_name = soup.find('div', class_='user-info d-flex justify-content-center flex-column').get_text(strip=True)
row1_nums = soup.find('div', class_='data-info d-flex item-tiling').find_all('span', class_='count')
row2_nums = soup.find('div', class_='grade-box clearfix').find_all('dd')
rank = soup.find('div', class_='grade-box clearfix').find_all('dl')[-1]['title']
info = {
'date': now,
'head_img': head_img,
'author_name': author_name,
'article_num': int(row1_nums[0].get_text()),
'fans_num': int(row1_nums[1].get_text()),
'like_num': int(row1_nums[2].get_text()),
'comment_num': int(row1_nums[3].get_text()),
'level': int(row2_nums[0].find('a')['title'][0]),
'visit_num': int(row2_nums[1]['title']),
'score': int(row2_nums[2]['title']),
'rank': int(rank),
}
df_info = pd.DataFrame([info.values()], columns=info.keys())
return df_info
except Exception as e:
print(e)
3.2 博客文章获取
获取博客的所有文章的相关数据,并存储到sqlite中,代码如下:
def get_blog():
headers = {
'User-Agent': 'Mozilla/5.0 (MSIE 10.0; Windows NT 6.1; Trident/5.0)',
'referer': 'https: // passport.csdn.net / login',
}
base_url = 'https://blog.csdn.net/tonydz0523/article/list/'
resp = requests.get(base_url+"1", headers=headers, timeout=3)
max_page = int(re.findall(r'var listTotal = (\d+) ;', resp.text)[0])//20+2 # 在js中获取文章数
df = pd.DataFrame(columns=['url', 'title', 'date', 'read_num', 'comment_num', 'type'])
count = 0
for i in range(1, max_page):
url = base_url + str(i)
resp = requests.get(url, headers=headers)
soup = BeautifulSoup(resp.text, 'lxml')
articles = soup.find("div", class_='article-list').find_all('div', class_='article-item-box csdn-tracking-statistics')
for article in articles[1:]:
a_url = article.find('h4').find('a')['href']
title = article.find('h4').find('a').get_text(strip=True)[1:]
issuing_time = article.find('span', class_="date").get_text(strip=True)
num_list = article.find_all('span', class_="num")
read_num = num_list[0].get_text(strip=True)
comment_num = num_list[1].get_text(strip=True)
the_type = get_type(title)
df.loc[count] = [a_url, title, issuing_time, int(read_num), int(comment_num), the_type]
count += 1
time.sleep(random.choice([1, 1.1, 1.3]))
return df
df_article = get_blog()
df_article.to_sql('blogs', con=engine, if_exists='replace', index=True)
获取数据的没有难点,获取页数可以在js代码中找
4 数据交互
如想使用交互是的显示数据,那么就需要使数据在前后段进行传输,dash使用react.js创建了很多相关表单组件,通过配合后端的callback函数进行数据的更新
Dash组件
dash提供了许多使用react.js编写的组件,这样方便了前后端的交互,详细见:https://dash.plot.ly/dash-core-components
本例主要使用了:
Interval:固定时间刷新页面数据Dropdown:下拉菜单样式的表单Graph:用于展示使用plotly绘制的图表
Callback函数
Callback函数是有数据前后端传输的功能,通过Input和Output中id与项目layout中id进行关联,一个Callback可以有很多输入,但是只能有一个输出。
看下面代码:
@app.callback(Output('heatmap', 'figure'),
[Input("dropdown1", "value"), Input('river', 'n_intervals')])
def get_heatmap(value, n):
df = get_df()
grouped_by_year = df.groupby('year')
data = grouped_by_year.get_group(value)
cross = pd.crosstab(data['weekday'], data['week'])
cross.sort_index(inplace=True)
trace = go.Heatmap(
x=['第{}周'.format(i) for i in cross.columns],
y=["星期{}".format(i+1) if i != 6 else "星期日" for i in cross.index],
z=cross.values,
colorscale="Greens",
reversescale=True,
xgap=4,
ygap=5,
showscale=False
)
layout = go.Layout(
# width=len(cross.columns)*33+100,
# height=335,
margin=dict(l=50, r=40, t=30, b=50),
xaxis=dict(
showgrid=False
),
yaxis=dict(
showgrid=False
)
)
return go.Figure(data=[trace], layout=layout)
上面代码会将使用plotly绘制的heatmap图像返回到app.layout中的id为heatmap的地方,返回的形式是什么?Output('heatmap', 'figure')的第二个参数figure。
这里Input传入了两个参数[Input("dropdown1", "value"), Input('river', 'n_intervals')]一个是下拉表单的value,另一个是intterval的计数值,这两个值传递到get_heatmap(value, n):中。一旦Input数据发生变化变回触发回调,对Output数据进行更改。
- Callback函数还要另外一种使用
State用于暂时保留状态,等有Input触发 - 第二个参数本例中是
figure,它是根据返回的内容而定,跟网页元素相关就是children,或者也可以是html.A中的src
html布局
在dash的layout中使用html语言的组件进行网页结构的布局。
head = html.Div([
html.Div(html.Img(src=info['head_img'][0], height="100%"), style={"float": "left", "height": "100%"}),
html.Span("{}博客的Dashboard".format(info['author_name'][0]), className='app-title'),
], className="row header")
上面代码中可见:
html.Div:就是对应创建了一个style:就是使用style更改风格className:用以关联css
css载入
网络css:
external_css = [
"https://stackpath.bootstrapcdn.com/bootstrap/4.1.3/css/bootstrap.min.css",
"https://cdnjs.cloudflare.com/ajax/libs/skeleton/2.0.4/skeleton.min.css",
]
for css in external_css:
app.css.append_css({"external_url": css})
通过上面方法载入,也可用过html.Link。
本地css:
放到项目根目录的assets文件夹中,则会自动载入。
title修改
dash的title等模板是默认的,可以通过下面方法进行修改:
app.index_string = '''
{%metas%}
泛泛之素的Dashboard
{%favicon%}
{%css%}
{%app_entry%}
'''
favicon修改就是将该格式图片放到,assets文件夹中即可。
数据缓存
多次使用的数据可以进行缓存,有两种模式:
- 写入redis
- 写入本地文件
具体见官网:https://dash.plot.ly/sharing-data-between-callbacks
因为要部署在heroku,本例使用的写到本地:
from flask_caching import Cache
cache = Cache(app.server, config={
'CACHE_TYPE': 'filesystem',
'CACHE_DIR': 'cache-directory'
})
@cache.memoize(timeout=3590)
def get_df():
df = pd.read_sql('blogs', con=engine)
df['date_day'] = df['date'].apply(lambda x: x.split(' ')[0]).astype('datetime64[ns]')
df['date_month'] = df['date'].apply(lambda x: x[:7].split('-')[0] + "年" + x[:7].split('-')[-1] + "月")
df['weekday'] = df['date_day'].dt.weekday
df['year'] = df['date_day'].dt.year
df['month'] = df['date_day'].dt.month
df['week'] = df['date_day'].dt.week
return df
timeout是缓存时间,时间一到自动释放缓存
运行
使用app.run_server(debug=True, threaded=True, port=7777)运行,因为后端使用flask,基本跟flask相同,这里可以更改port,host
等。
注:jupyter不能使用debug模式,使用会报错
5 部署
本例部署在heroku上,部署方法可以看我之前写的文章 https://blog.csdn.net/tonydz0523/article/details/82707569
也可以见官网:https://dash.plot.ly/deployment
如果heroku无法访问的话,也可部署在云主机等,也可以和你的其他flask应用部署在一起,部署方式同flask一样。