MobileNetV2最详细讲解
MobileNetV1(以下简称:V1)过后,我们就要讨论讨论MobileNetV2(以下简称:V2)了。为了能更好地讨论V2,我们首先再回顾一下V1:
回顾MobileNet V1
V1核心思想是采用 深度可分离卷积 操作。在相同的权值参数数量的情况下,相较标准卷积操作,可以减少数倍的计算量,从而达到提升网络运算速度的目的。
V1的block如下图所示:
首先利用3×3的深度可分离卷积提取特征,然后利用1×1的卷积来扩张通道。用这样的block堆叠起来的MobileNetV1既能减少不小的参数量、计算量,提高网络运算速度,又能的得到一个接近于标准卷积的还不错的结果,看起来是很美好的。
但是!
有人在实际使用的时候, 发现深度卷积部分的卷积核比较容易训废掉:训完之后发现深度卷积训出来的卷积核有不少是空的: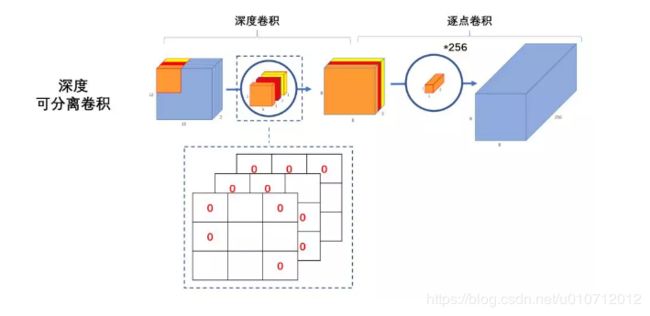
这是为什么?
作者认为这是ReLU这个浓眉大眼的激活函数的锅。
ReLU做了些啥?
V2的论文中,作者也有这样的一个解释。
这是将低维流形的ReLU变换embedded到高维空间中的的例子。

我们在这里抛弃掉流形这个概念,通俗理解一下。
假设在2维空间有一组由m个点组成的螺旋线Xm数据(如input),利用随机矩阵T映射到n维空间上并进行ReLU运算,即

其中,Xm被随机矩阵T映射到了n维空间:

再利用随机矩阵T的逆矩阵 T − 1 T^{-1} T−1,将y映射回2维空间当中:

换句话说,就是对一个n维空间中的一个“东西”做ReLU运算,然后(利用T的逆矩阵T-1恢复)对比ReLU之后的结果与Input的结果相差有多大。
可以看到:

当n = 2,3时,与Input相比有很大一部分的信息已经丢失了。而当n = 15到30,还是有相当多的地方被保留了下来。
也就是说,对低维度做ReLU运算,很容易造成信息的丢失。而在高维度进行ReLU运算的话,信息的丢失则会很少。
这就解释了为什么深度卷积的卷积核有不少是空。发现了问题,我们就能更好地解决问题。针对这个问题,可以这样解决:既然是ReLU导致的信息损耗,将ReLU替换成线性激活函数。
Linear bottleneck
我们当然不能把所有的激活层都换成线性的啊,所以我们就悄咪咪的把最后的那个ReLU6换成Linear。(至于为什么换最后一个ReLU6而不换第一个和第二个ReLU6,看到后面就知道了。)

作者将这个部分称之为linear bottleneck。对,就是论文名中的那个linear bottleneck。
Expansion layer
现在还有个问题是,深度卷积本身没有改变通道的能力,来的是多少通道输出就是多少通道。如果来的通道很少的话,DW深度卷积只能在低维度上工作,这样效果并不会很好,所以我们要“扩张”通道。既然我们已经知道PW逐点卷积也就是1×1卷积可以用来升维和降维,那就可以在DW深度卷积之前使用PW卷积进行升维(升维倍数为t,t=6),再在一个更高维的空间中进行卷积操作来提取特征:

也就是说,不管输入通道数是多少,经过第一个PW逐点卷积升维之后,深度卷积都是在相对的更高6倍维度上进行工作。
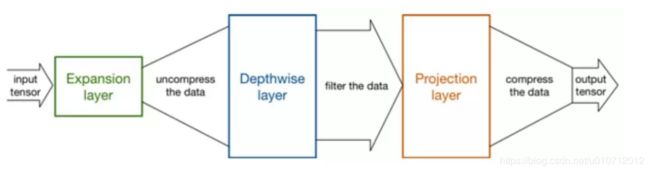
Inverted residuals
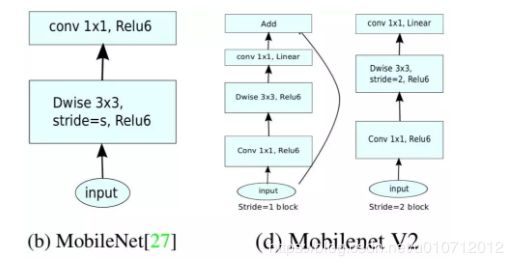
回顾V1的网络结构,我们发现V1很像是一个直筒型的VGG网络。我们想像Resnet一样复用我们的特征,所以我们引入了shortcut结构,这样V2的block就是如下图形式:
对比一下V1和V2:
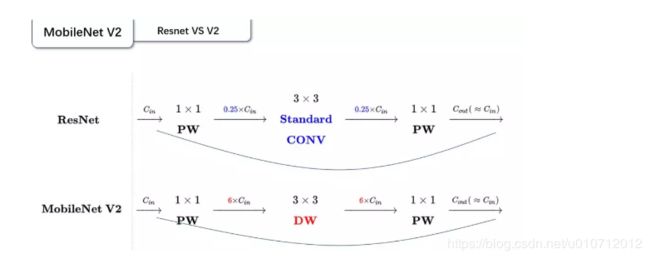
可以发现,都采用了 1×1 -> 3 ×3 -> 1 × 1 的模式,以及都使用Shortcut结构。但是不同点呢:
ResNet 先降维 (0.25倍)、卷积、再升维。
MobileNetV2 则是 先升维 (6倍)、卷积、再降维。
刚好V2的block刚好与Resnet的block相反,作者将其命名为Inverted residuals。就是论文名中的Inverted residuals。
V2的block
至此,V2的最大的创新点就结束了,我们再总结一下V2的block:
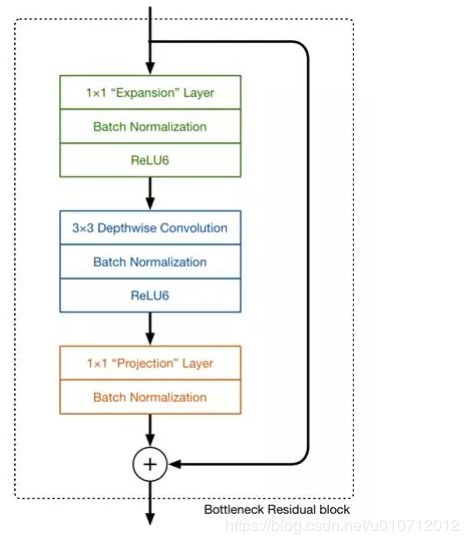
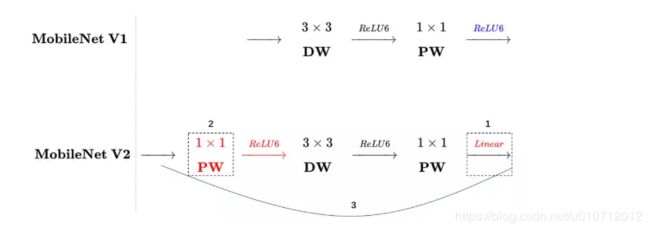
我们将V1和V2的block进行一下对比:
左边是v1的block,没有Shortcut并且带最后的ReLU6。
右边是v2的加入了1×1升维,引入Shortcut并且去掉了最后的ReLU,改为Linear。步长为1时,先进行1×1卷积升维,再进行深度卷积提取特征,再通过Linear的逐点卷积降维。将input与output相加,形成残差结构。步长为2时,因为input与output的尺寸不符,因此不添加shortcut结构,其余均一致。
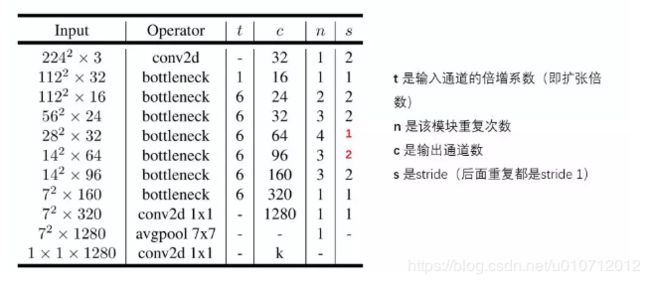
V2的网络结构
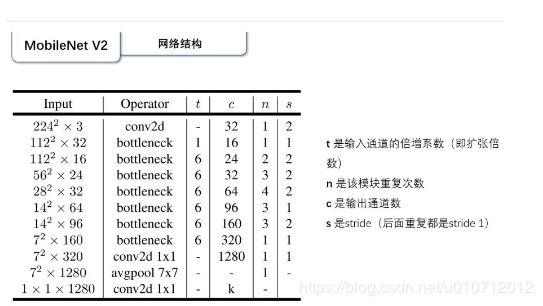
28×28×32那一层的步长为2的话,输出应该是14×14,应该是一处错误。按照作者论文里的说法,自己修改了一下:
实验结果
Image Classification

图像分类的实验,主要是在以上的网络上进行的,ShuffleNet是V1的版本使用了分组卷积和shuffling, 也使用了类似的残差结构(c)中的(b)。
结果如下:
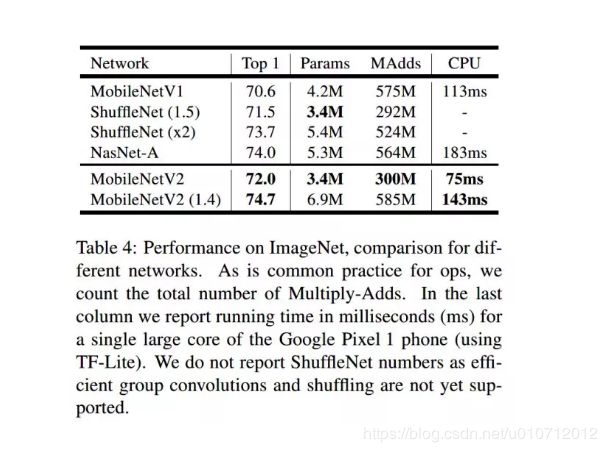
Object Detection
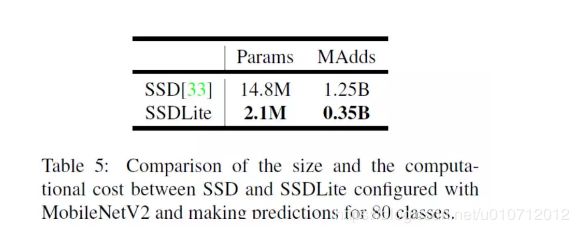
SSDLite
目标检测方面,作者首先提出了SSDLite。就是对SSD结构做了修改,将SSD的预测层中所有标准卷积替换为深度可分离卷积。作者说这样参数量和计算成本大大降低,计算更高效。SSD与SSDLite对比:
应用在物体检测任务上,V1与常用检测网络的对比:

可以看到,基于MobileNetV2的SSDLite在COCO数据集上超过了YOLOv2,并且大小小10倍速度快20倍。
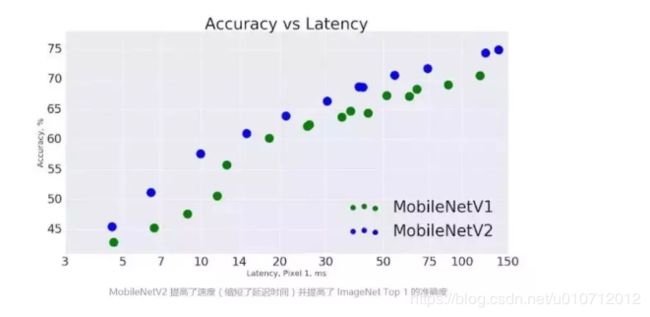
V1 VS V2

可以看到,虽然V2的层数比V1的要多很多,但是FLOPs,参数以及CPU耗时都是比V1要好的。
V1V2在google Pixel 1手机上在Image Classification任务的对比:
但是貌似实际上都是用的mobilenetv1的多。。。
https://github.com/dmlc/gluon-cv/blob/master/gluoncv/model_zoo/mobilenet.py