hive学习6:hive级联求和
说明:
级联求和,不仅hive会使用,其实mysql或者Oracle也会用到的,我这边先用mysql实现下,具体需求如下:
| username | month | times |
| A | 2018-02 | 5 |
| A | 2018-03 | 10 |
| A | 2018-04 | 10 |
| B | 2018-02 | 5 |
| B | 2018-03 | 10 |
| B | 2018-03 | 10 |
| B | 2018-04 | 10 |
| B | 2018-02 | 5 |
| B | 2018-01 | 10 |
| B | 2018-01 | 10 |
| B | 2018-01 | 10 |
| B | 2018-01 | 10 |
| A | 2018-02 | 10 |
| A | 2018-01 | 10 |
| A | 2018-01 | 10 |
上面数据是模拟用户每个月登陆的次数,字段分别是用户名和月份及访问次数
需求是:
统计用户每个月访问的次数,并且级联总数,结果应该是这样的:
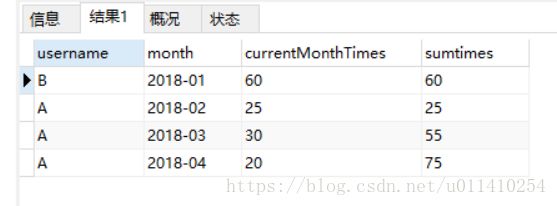
具体做法解析:
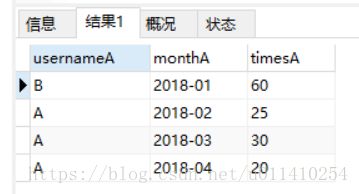
1、先进行分组统计每个月的访问次数即:
select username usernameA,t.`month` monthA, sum(t.times) timesA from test t group by t.month结果:
2、通过上面的结果,可以看到,想要计算级联结果必须是join(如果是多张表必须也是join),这里是单表,所以只能是自己连自己:
select * from (
(select username usernameA,t.`month` monthA, sum(t.times) timesA from test t group by t.month) A
INNER JOIN
(select username usernameB,t.`month` monthB, sum(t.times) timesB from test t group by t.month) B
on A.usernameA = B.usernameB
)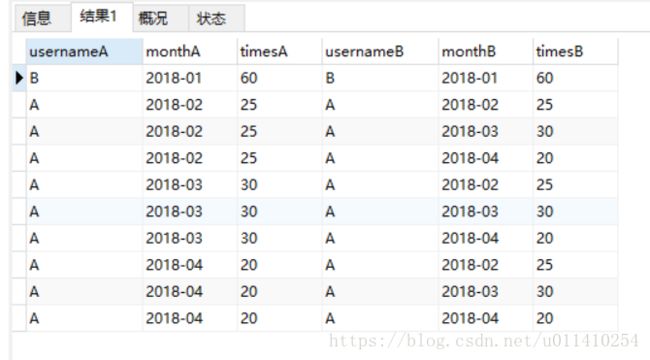
注意monthA这一列,用户A的2018-02这一月份三条数据,如果通monthA进行分组,在求和timesB,这样就离我们想要的结果就更近了,但是在求和前要有个条件,就是在求和时monthB的月份不能不能大于monthA的月份,否则统计就没意义了,,也就不是级联了,思路分析结束.
3、进行级联求和
SELECT MAX(usernameA) username, monthA `month` ,max(timesA) currentMonthTimes, sum(timesB) sumtimes from(
(select username usernameA,t.`month` monthA, sum(t.times) timesA from test t group by t.month) A
INNER JOIN
(select username usernameB,t.`month` monthB, sum(t.times) timesB from test t group by t.month) B
on A.usernameA = B.usernameB
)
where monthB <= monthA GROUP BY monthA 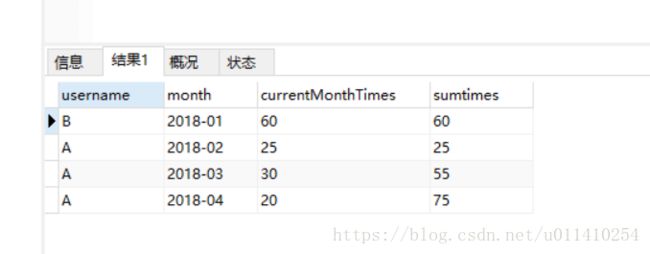
上面的mysql结束,那么hive下实现路径和mysql实现一样,简单看下hive实现,在hive下实现,我多准备了一些数据,请继续往下看:
hive具体实现步骤:
1、把上面的内容放到文件里,上传到hive所在的服务器里
2、创建hive表
0: jdbc:hive2://localhost:10000 (closed)> create table t_visit_times(username string,month string ,times int)
0: jdbc:hive2://localhost:10000 (closed)> row format delimited
0: jdbc:hive2://localhost:10000 (closed)> fields terminated by ',';3、导入数据到t_visit_times表里
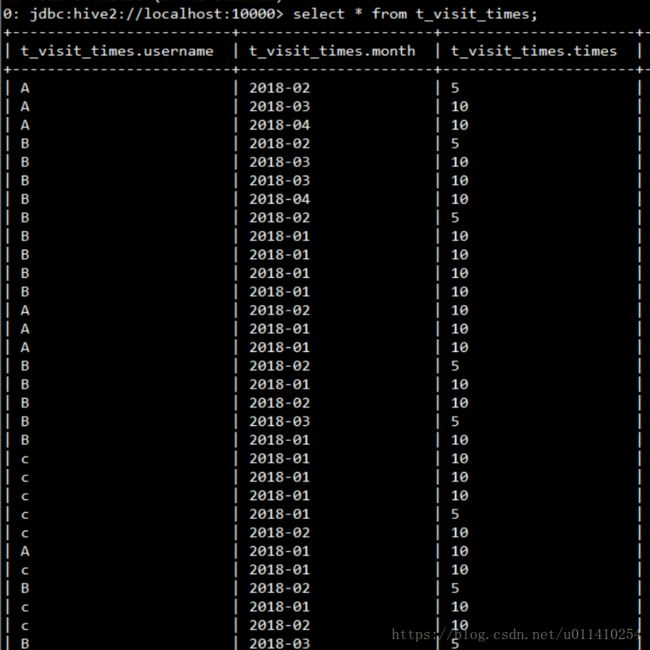
0: jdbc:hive2://localhost:10000> load data local inpath '/home/hadoop/jl.txt' into table t_visit_times;数据内容如下:
4、编写sql
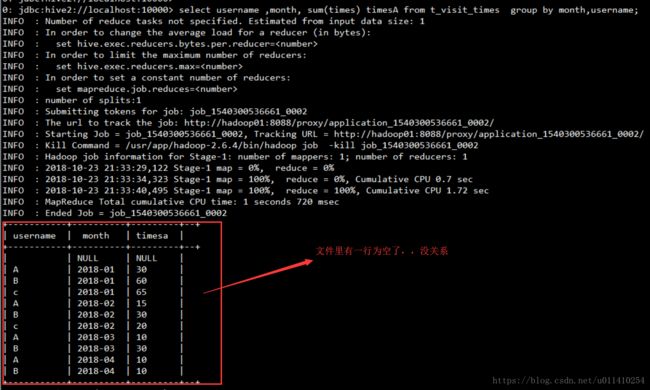
4.1 先计算每个用户每月的访问量总和
0: jdbc:hive2://localhost:10000> select username ,month, sum(times) timesA from t_visit_times group by month,username;结果:
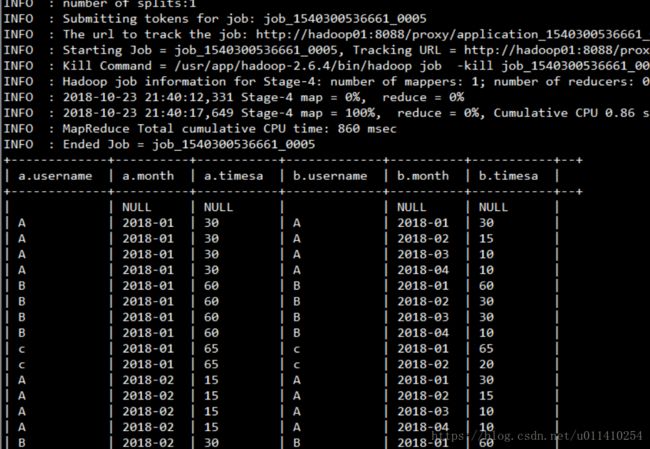
4.2 继续自连join
select a.*,b.* from
( select username ,month, sum(times) timesA from t_visit_times group by month,username) a
inner join
( select username ,month, sum(times) timesA from t_visit_times group by month,username) b
on a.username = b.username结果:
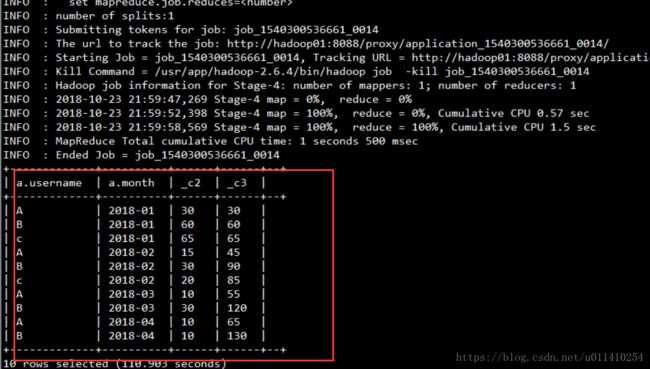
4.3级联
0: jdbc:hive2://localhost:10000> select a.username, a.month,max(a.timesA), sum(b.timesB) from
0: jdbc:hive2://localhost:10000> ( select username ,month, sum(times) timesA from t_visit_times group by month,username) a
0: jdbc:hive2://localhost:10000> inner join
0: jdbc:hive2://localhost:10000> ( select username ,month, sum(times) timesB from t_visit_times group by month,username) b
0: jdbc:hive2://localhost:10000> on a.username = b.username where b.month <= a.month group by a.month,a.username
0: jdbc:hive2://localhost:10000> order by a.month,a.username;结果:执行上面的sql跑的有点久,需要跑5个mr任务,,,
到此结束,和mysql差不多