mongodb 副本集的搭建
mongodb 副本集的搭建
mongodb作为非关系型数据库,适合大量存储的应用场景,目前也支持事务,其副本集的分布式思想也符合实际应用场景。因此在这里记录一下mongodb副本集的搭建过程,以及想要提出的问题。
(1)下载并安装mongodb
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 2930ADAE8CAF5059EE73BB4B58712A2291FA4AD5
echo "deb [ arch=amd64,arm64 ] http://mirrors.aliyun.com/mongodb/apt/ubuntu xenial/mongodb-org/3.6 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-3.6.list
sudo apt-get update
sudo apt-get install -y mongodb-org=3.6.2 mongodb-org-server=3.6.2 mongodb-org-shell=3.6.2 mongodb-org-mongos=3.6.2 mongodb-org-tools=3.6.2
mongodb的部署环境是Ubuntu16.04,此时进入mongodb的目录,创建三个文件夹,分别用来存放mongodb的数据、日志、以及配置文件。
(2)测试启动一个mongodb节点
添加配置文件test.conf
dbpath = /home/liujian/mongodb/data
port = 9001
bind_ip = 0.0.0.0
logpath =/home/liujian/mongodb/log/logs.log
smallfiles=true
logappend=true
fork =true
这里主要是配置以下mongodb数据、日志的存放位置,以及对外开放的端口。此时,外界需要连接mongodb节点,可以通过访问ip:9001来做到。如果没有安装图形化的工具Studio 3T,那么可以在命令行界面输入以下内容执行开启数据库并连接
mongod --config /mongodb/conf/test.conf
mongo --host localhost --port 9001
连接数据库后可以尝试输入
show dbs
use MyNewDatebase
db.test.insertOne({name: "hello"})
此时系统会新建一个名叫MyNewDatebase的文档集,并在其中添加一个叫做test的文档,该文档中保存着name:"hello"的键值。
一个mongodb的可用性其实是不高的,不适合应用在实际业务中,当mongodb的服务器挂掉以后,整个系统就崩溃了,那么这个系统的可用性就太差了。为了解决这个问题,那就需要引入多节点部署,mongodb为我们提供了一个叫做mongodb的副本集的结构。
(3)mongodb的副本集
将配置文件中添加
replSet="test"
即该mongo节点属于test集,在启动时,将启动项修改为
mongod --config test.conf -replSet test
此时该节点就会工作在test集下
在这里,我使用了3个节点进行副本集的搭建,首先是pss模式,pss架构如图
一个主节点与两个从节点。首先启动三个节点并连接其中一个节点,输入
var rsconf={
_id:"test",
members:
[ { _id:1, host:'localhost:9003' },
{ _id:2, host:'localhost:9001' },
{_id:3, host:'xxx.xxx.xxx.xxx:9002'}
]
}
或者在primarily处通过rs.add(“ip:port”)来添加节点也是可以的
节点1,2部署在同一台服务器上,而节点3在另外的服务器上。
初始化副本集
rs.initiate(rsconf)
分别连接三个节点,可以发现有两个是secondary,一个是primary,此时还需要再主节点上开启从节点的读功能,在主节点输入
slaveOK();
可以在主节点添加一条字段,看看附属节点能不能读取,如果能够读取则说明部署成功了。
pss架构的副本集,采用了和raft算法类似的一个选举模式,当主节点挂掉之后,会从随机的一个附属节点中选一个作为主节点继续工作。这里引申出节点个数的问题,当一个集群的大多数节点(2N个节点中的N+1个)挂掉之后,这个副本集无法选举出primary节点,从而导致整个副本集只有读的功能,此时N(奇数)个节点的容错与N+1个节点的容错是一致的,因此副本集中节点个数应是奇数个。
不过,在引入PAS模式之后,副本集中节点的个数为偶数个也可以。
(4)PAS副本集
PAS结构引入了一个Arbiter节点作为仲裁者,这个节点只负责投票,其余概不负责,结构如图。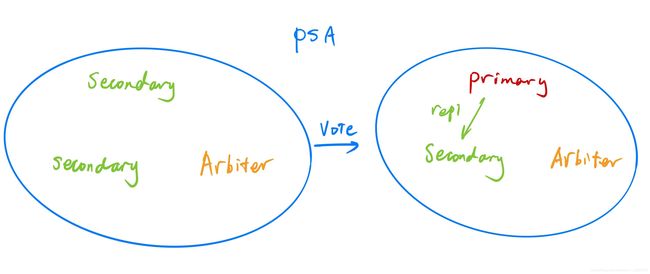
在主节点中,只需通过rs.addArb(“ip:port”)即可将某节点作为仲裁者加入副本集,一个副本集中最好添加一个仲裁者。那么,假如仲裁节点挂掉怎么办?整个副本集是否可以正常地继续选举出主节点呢?答案是可以的。仲裁者相当于是上了一层保险,当大多数数据节点挂点时,副本集仍然可以正常地选出主节点。
当然,分布式的结构都受CAP定理的限制,始终实在AP方面寻找均衡,mongodb的最终一致性就是通过牺牲一部分的一致性来提升它的可用性。并且,数据库服务器实际上大部分操作是读而不是写,因此,只需要少量的primary,多数的secondary也可以适应实际情况。
那么,既然mongodb的主节点不是固定的(这才是正确的思想,否则副本集没有太大的意义),此时不能通过直连的方式去连接primary节点(当主从节点互换时,那么就失去了写功能),那么前端或者web服务器是如何去连接primary节点的?
参考一些资料,做法是客户端添加一个ip池,连接时客户端会自动判断主节点,并建立连接。具体实现,下次我再试试。
(5)需要解决的问题
① 当主节点压力过大时,比如当有N个secondary节点时,主节点要复制数据到所有的secondary上,要如何实现?会不会造成primary的崩溃?
② 主从节点的功能不相同,主节点不仅要负责数据的读写,还要负责从节点数据的复制,因此,主节点服务器的性能应该相对于从节点来说,性能更好,那么我们能把不能做到将主节点限制到那些性能好的服务器上?
③ 因为主从节点的数据都是一致的,当主节点的数据量过多时,这个集群几乎每个节点都不堪重负了。因此mongo通过分片再来细分数据,那么能否做到按照一定业务类型来对服务器进行分片,那么此时,分片后集群的结构是怎么样的,如果需要故障转移怎么办?
参考资料
mongodb搭建
mongodb副本集