Hadoop3.2.0搭建部署
参考文章:
Ubuntu16.04下伪分布式环境搭建之hadoop2.6.0
【Hadoop】在Ubuntu系统下安装Hadoop集群安装
一、设备
3台Ubuntu16.04服务器(master:1;slave:2)
二、准备工作
1.配置hostname、hosts文件(分别修改3台服务器)
①修改主机名
vim /etc/hostname
修改3台机器名分别为master、slave1、slave2
②修改本地hosts文件
vim /etc/hosts
查看确认三台机器IP 地址,可以ping确认网络联通;
将不相关的指向删除,127.0.0.1 localhost删除(目测应该可以不删除),添加以下三项:
192.168.1.107 master
192.168.1.108 slave1
192.168.1.110 slave2
2.创建hadoop账户
$ sudo useradd -m hadoop -s /bin/bash #创建hadoop用户,并使用/bin/bash作为shell
$ sudo passwd hadoop #为hadoop用户设置密码,输入两次
$ sudo adduser hadoop sudo #为hadoop用户增加管理员权限,方便部署
$ su - hadoop #将当前用户切换到hadoop用户
$ sudo apt-get update #更新hadoop用户的apt,方便后续软件安装
sudo apt-get update 可能会报错,参考解决方法
3.ssh免密码登录
简单来说,这一步就是给master控制权限,可以自动的访问控制slave
①开始配置之前,确认自己的设备安装了ssh服务。
dpkg --list|grep ssh #查看ssh安装运行状况
sudo apt-get install openssh-server #如果缺少openssh-server,运行这一行
②接下来在各台机器分别执行以下代码配置免密码登录(本机)
sudo ssh localhost #登陆SSH,或者是ssh master,第一次登陆输入yes
exit #退出登录的ssh localhost
cd ~/.ssh/ #如果没法进入该目录,执行一次sudo ssh localhost
ssh-keygen -t rsa -P "" #生成私钥、公钥,默认存放
cat ./id_rsa.pub >> ./authorized_keys #加入授权
chmod 600 authorized_keys #设置该文件的权限
ssh localhost #或者是ssh master,输入yes,无需密码登陆,可看到如下界面
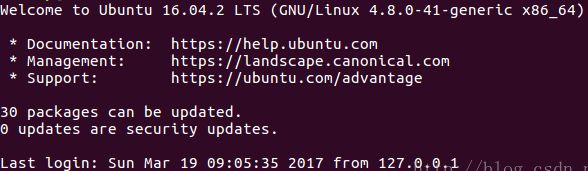
注意:第一次可能需要输入yes确认,如果还是需要密码,则证明本机配置错误,重新检查上面的步骤,包括hosts/hostname的配置,删除已生成的秘钥,重复上述流程(或者自己搜一下解决方法)。
③配置master免密登录slave1/slave2
分别在两个子节点的命令终端执行下面的命令,将上公匙传输到 slave1节点,过程中需要输入 slave1 节点的密码,传输100%以后就是传过去了:
scp ~/.ssh/id_rsa.pub hadoop@slave1:/home/hadoop/
接着在 slave1、slave2节点上,把公钥加入授权:
mkdir ~/.ssh # 如果不存在该文件夹需先创建,若已存在则忽略
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
rm ~/id_rsa.pub # 用完就可以删掉了
正常的话,master就可以登录slave了。
ssh slave1 #可以用来检验是否能成功登陆,exit退出
4.安装JDK
①去Apache官网下载jdk,下载后解压重命名,执行下面的命令:
su hadoop
cd ~
mkdir local
sudo tar -zxvf jdk-8u192-linux-x64.tar.gz -C ../local
②配置环境变量
vi ~/.bashrc
在最后面添加路径(hadoop解压之后也需要配置环境,这里一起给出):
export JAVA_HOME=~/local/jdk1.8.0_192
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
export HADOOP_HOME=~/local/hadoop-3.2.0
export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
接下来执行 source ~/.bashrc 使文件生效,通过查看版本来检查是否配置成功:
java -version
三、安装Hadoop3.2.0
1.解压安装(与jdk差不多)
①下载(测试了一下,清华源的镜像速度最快最稳)
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.2.0/
我的解压到了local/hadoop-3.2.0
②配置环境变量(参考JDK配置)
这里需要注意的是:在hadoop-env.sh中需要再次将java_home等选项加入,否则可能会出现java_home找不到而无法启动节点的情况:
#这一行:export HADOOP_OS_TYPE=${HADOOP_OS_TYPE:-$(uname -s)}的下面:
export JAVA_HOME=~/local/jdk1.8.0_192
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/native"
③验证:hadoop version
2.环境配置
主要的配置文件在目录/home/hadoop/local/hadoop-3.2.0中,可以ls一下,查看对应文件,需要修改的主要有5个文件:
workers(旧版本的slaves)
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
要修改这些文件,因为权限问题可能需要切换到root,具体各文件配置如下:
①vim workers
此文件记录的是将要作为 Datanode 节点的名字,将 slave1、slave2 主机名字加入进去,如果想让 master 节点作为 Namenode 的同时也作为 Datanode,可以保留 master(我这里保留了)。
master
slave1
slave2
②vim core-siite.xml
fs.defaultFS
hdfs://master:9000
hadoop.tmp.dir
/home/hadoop/local/hadoop-3.2.0/tmp
Abase for other temporary directories.
③vim hdfs-site.xml
dfs.namenode.secondary.http-address
master:50090
dfs.replication
2 #一般是3,这里因为slave节点的个数为2,就设置为2
dfs.namenode.name.dir
/home/hadoop/local/hadoop-3.2.0/tmp/dfs/name
dfs.datanode.data.dir
/home/hadoop/local/hadoop-3.2.0/tmp/dfs/data
④vim mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
master:10020
mapreduce.jobhistory.webapp.address
master:19888
⑤vim yarn-site.xml
yarn.resourcemanager.hostname
master
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.resource.memory-mb
131072
yarn.nodemanager.resource.cpu-vcores
32
yarn.scheduler.maximum-allocation-vcores
64
3.配置完毕之后,将hadoop配置复制到slave中
这一步,也可以直接在各节点重复上述步骤,我在做的时候就是一起做的(比较麻烦,建议直接复制),具体步骤如下:
①在 master 节点执行:
cd ~/local
sudo rm -r ./hadoop/tmp # 删除 Hadoop 临时文件
sudo rm -r ./hadoop/logs/* # 删除日志文件
tar -zcf ~/hadoop.master.tar.gz ./hadoop # 先压缩再复制
cd ~ #跳转到有压缩包的路径下
scp ./hadoop.master.tar.gz slave1:/home/hadoop #发送到slave1节点,对其他salve节点也要执行这一步
②在剩余 salve 节点上执行(以slave1为例):
sudo rm -r /usr/local/hadoop # 删掉旧的(如果存在)
sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local
sudo chown -R hadoop /usr/local/hadoop
备注:上述命令直接拷贝自雪原那么远参考文章,基本未做修改(请自行校验)
四、启动Hadoop
hdfs namenode -format # 首次运行需要执行初始化,之后不需要
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
jps #查看各个节点的启动进程
参考输出:
master: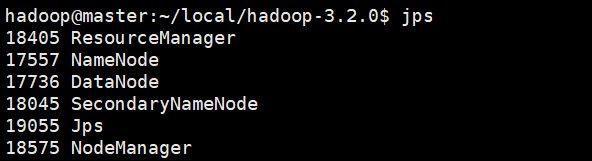
slave:
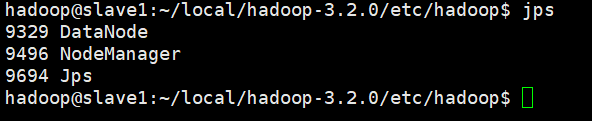
到这里,基本就部署完毕了。可以再浏览器打开http://master:50070/查看集群状态。