java爬虫-0022,模拟登录
项目地址:https://github.com/wenrongyao/java_crawler
基本原理:用户输入登录信息=>登录成功,服务器将登录成功的信息发送的前台,通常存在cookie中=>后续请求带上登录成功的cookie信息,在服务器即视为登录成功
基本步骤:通过谷歌的开发者工具,抓取登录包=>分析出登录需要传递的数据(sublime全局搜索的妙用)=>请求服务器=>获取返回报文的cookie字段(比较登录前后的cookie可以知道需要带上什么cookie)=>带上cookie做后续请求。
1、通过谷歌开发者工具获取登录信息
1.1 勾选preserve log,可以保证登录请求不会被登录成功请求刷掉。

1.2 获取登录登信息

通过上面的分析,我们可以得知请求的地址和类型,还有请求参数,我们只需要拼凑出我们请求数据即可。其中参数的具体含义(猜想)
souce:不知道具体含义,不过似乎不会改变,
form_email :邮箱地址
form_password:密码
captcha-solution: 验证码
captcha-id:看不出来
2、分析请求数据
分析请求数据是模拟登录中最难的一部分,这边有一个小技巧:先保存登录页面的网页信息,利用sublime全局搜索关键字,具体如下:
2.1 在登录界面右键->下载(网页全部)
2.2 查看刚刚下载的html文件,找到登录表单部分。(推荐使用sublime,一来可以美化,二来可以全局搜索)

由此可以知道每个字段的具体含义
source :index_nav 多次实验,该参数不会变
form_email :邮箱地址
form_password:密码
captcha-solution: 验证码(可以调用百度ocr接口识别,不过识别率好像有点低)
上述四个字段都容易解决,关键是最后一个参数,每次都会改变,应该是一个token,token的长生一般有两种方式:1)服务器产生,前台获取;2)前端通过js生成
正确的处理思路:破解别人的token生成算法(大神除外),而是找到人家加密的代码直接使用,方便快捷。
2.3 sublime全局搜索
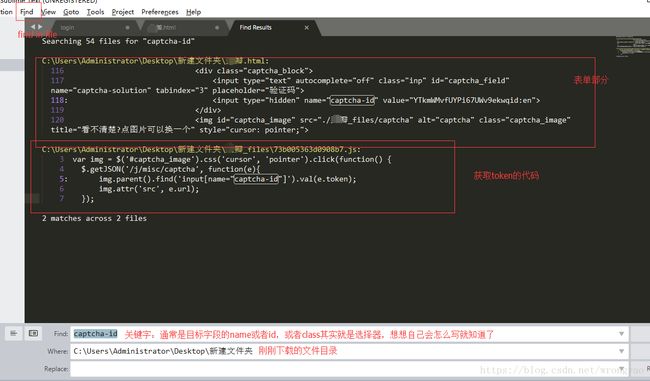
由此可知captcha-id每次回去访问https://www.douban.com//j/misc/captcha
访问报文如下
{"url":"\/\/www.douban.com\/misc\/captcha?id=WfQ1k5feHvtxDfVjz1Ztyg7m:en&size=s","token":"WfQ1k5feHvtxDfVjz1Ztyg7m:en","r":false}
看到这个应该就清楚了,其中url是验证码图片的地址,token 就是令牌
到此为止就分析完了请求的参数,这边算是比较简单,只要一个令牌,通常名称和密码都会通过算法加密,一般是js,但是js会被加载到前台,所以只要通过sublime全局搜索一般就能定位到加密部分。通过node.js本地运行js代码可以验证。
注:上述是在重复登录多次之后才会要求输验证码和token,如果第一次登录是不需要的。那样就更简单了

3、登录获取响应头数据
/**
* 第二个爬虫程序,模拟登录
*/
@Test
public void crawlerClient_02() {
String url = "https://www.douban.com/accounts/login";
Map headerParams = new HashMap<>();
headerParams.put(P.REQUEST.USER_AGENT, P.USER_AGENT);
String requestParamsStr = "请求数据";
Map requestParams = new HashMap<>();
requestParams.put(P.REQUEST.REQUEST_PARAMS, requestParamsStr);
requestParams.put(P.REQUEST.CONTENT_TYPE, P.REQUEST.CONTENT_TYPE_FROM_URLENCODEED);
Map resMap = Request.post(url, headerParams, requestParams);
// 获取请求头
Header[] headers = (Header[]) resMap.get(P.REQUEST.HEADERS);
for(Header header : headers){
System.out.println(header.getName() + ":" + header.getValue());
}
} 响应的报文头,其中set-cookie包含了登录信息,其实这就已经登录成功了

4、比较未登录页面和登录页面的cookie信息,
cookie格式化工具:http://www.jsons.cn/cssforamt/

登录后cookie比未登录cookie多一个dbc12,而这个dbc12会在登录的请求返回,所以我们在未登录cookie的基础上带上这个字段
5、获取需要登录的页面信息
/**
* 第三个爬虫程序,模拟登录后获取需要登录的数据
*/
@Test
public void crawlerClient_03() {
String url = "https://www.douban.com";
Map headerParams = new HashMap<>();
headerParams.put(P.REQUEST.USER_AGENT, P.USER_AGENT);
headerParams.put(P.REQUEST.COOKIE, P.COOKIE + "dbcl2=\"185440808:yJ+PWhiBL6w\"");
Map resMap = Request.get(url, headerParams);
System.out.println(resMap.get(P.REQUEST.RES_BODY));
} 效果如下:这就是某瓣的登录后的主页
