加速python代码运行
文章目录
- 一、Numba
- 1.1 加速python的for循环
- 1.2 numpy运算
- 二、Cython
- 三、Pandarallel
- 示例一:df.apply—df.applymap
- 示例二:df.groupby.apply—df.groupby.rolling.apply
- 示例三:Series.map—Series.apply—Series.rolling.apply
- 四、Dask
- 4.1 简单入门:
- 五、Rapids
前言:在处理数字、字符等操作时尽量使用Numpy,Scipy和Pandas等这些已经高度优化过的库。在数据存储时尽量使用csv,tsv等格式而不是xls/xlsx。
一、Numba
Python 虽然写起来代码量要远少于如 C++,Java,但运行速度又不如它们,因此也有了各种提升 Python 速度的方法技巧,当我们对 Numpy 数组进行基本的数组计算,比如加法、乘法和平方, Numpy 都会自动在内部向量化,这也是它可以比原生 Python 代码有更好性能的原因。
Numba 是一个可以将 Python 代码转换为优化过的机器代码的编译库。用 Numba 库进行加速比较耗时的循环操作以及 Numpy 操作。通过这种转换,对于数值算法的运行速度可以提升到接近 C 语言代码的速度。
更多详情:http://numba.pydata.org/numba-doc/latest/index.html
Anaconda自带了该函数。
python安装:pip install numba
使用方法:
from numba import jit
接着在函数前面增加一行代码,采用装饰器
@jit(nopython=True)
1.1 加速python的for循环
示例如下:
import time
import numpy as np
from numba import jit
@jit(nopython=True)
def insertion_sort_numpy(arr):
for i in range(len(arr)):
cursor = arr[i]
pos = i
while pos > 0 and arr[pos-1] > cursor:
arr[pos] = arr[pos-1]
pos = pos-1
arr[pos] = cursor
return arr
# 插入排序算法
def insertion_sort(arr):
for i in range(len(arr)):
cursor = arr[i]
pos = i
while pos > 0 and arr[pos-1] > cursor:
arr[pos] = arr[pos-1]
pos = pos-1
arr[pos] = cursor
return arr
if __name__ == '__main__':
list_of_numbers = np.random.randint(1,10000,10000)
t1 = time.time()
result1 = insertion_sort(list_of_numbers)
t2 = time.time()
result2 = insertion_sort_numpy(list_of_numbers)
t3 = time.time()
run_time1 = t2 - t1
run_time2 = t3 - t2
print('tatol time1={}'.format(run_time1))
print('tatol time2={}'.format(run_time2))
'''
tatol time1=19.880768060684204
tatol time2=0.22452545166015625
'''
在使用numba 时代码中不能有第三方计算函数,尽量使用纯python代码,否则编译报错。
1.2 numpy运算
这里采用的是 vectorize 装饰器,它有两个数参数,第一个参数是指定需要进行操作的 numpy 数组的数据类型,这是必须添加的,因为 numba 需要将代码转换为最佳版本的机器代码,以便提升速度;
- 第二个参数是 target ,它有以下三个可选数值,表示如何运行函数:
-
cpu:运行在单线程的 CPU 上
parallel:运行在多核、多线程的 CPU
cuda:运行在 GPU 上
import time
import numpy as np
from numba import vectorize, int64
num_loops = 50
img1 = np.ones((1000, 1000), np.int64) * 5
img2 = np.ones((1000, 1000), np.int64) * 10
img3 = np.ones((1000, 1000), np.int64) * 15
def add_arrays(img1, img2, img3):
return np.square(img1+img2+img3)
@vectorize([int64(int64,int64,int64)], target='parallel')
def add_arrays_numba(img1, img2, img3):
return np.square(img1+img2+img3)
t1 = time.time()
for _ in range(num_loops):
result1 = add_arrays(img1, img2, img3)
t2 = time.time()
for _ in range(num_loops):
result2 = add_arrays_numba(img1, img2, img3)
t3 = time.time()
run_time1 = t2 - t1
run_time2 = t3 - t2
print('tatol time1={}'.format(run_time1))
print('tatol time2={}'.format(run_time2))
'''
tatol time1=0.760728120803833
tatol time2=0.16445159912109375
'''
二、Cython
以下示例运行在win10中,环境visual studio 2015,Anaconda3
Cython是一个静态编译器,可以为您优化代码。加载cypthonmagic扩展并使用cython标记使用cython编译代码。
官方文档:http://docs.cython.org/en/latest/
Cpython的安装:pip install Cython
示例:在test文件夹下新建factorial_python.py,factorial_cython.pyx,setup.py,test.py四个文件。
factorial_python.py
def test(x):
y = 1
for i in range(1, x+1):
y *= i
return y
factorial_cython.pyx
在cython代码中,使用cpdef定义函数,并使用cdef申明变量类型。
cpdef int test(int x):
cdef int y = 1
cdef int i
for i in range(1, x+1):
y *= i
return y
setup.py
from distutils.core import setup
from Cython.Build import cythonize
setup(ext_modules = cythonize('factorial_cython.pyx'))
=================================上下代码同效==================================
from distutils.core import setup
from distutils.extension import Extension
from Cython.Distutils import build_ext
filename = 'factorial_cython' # 源文件名
full_filename = 'factorial_cython.pyx' # 包含后缀的源文件名
setup(
cmdclass = {'build_ext': build_ext},
ext_modules = [Extension(filename, [full_filename])] # 配置需要cython编译的源文件
)
test.py
import factorial_python
import factorial_cython
import time
number = 100000
t1 = time.time()
factorial_python.test(number)
t2 = time.time()
factorial_cython.test(number)
t3 = time.time()
print("Python time = {}".format(t2-t1))
print("Cython time = {}".format(t3-t2))
编译:在test文件夹下打开终端运行:python setup.py build_ext --inplace
删除:rm factorial_cython.pyx
测试:python test.py。
编译截图:
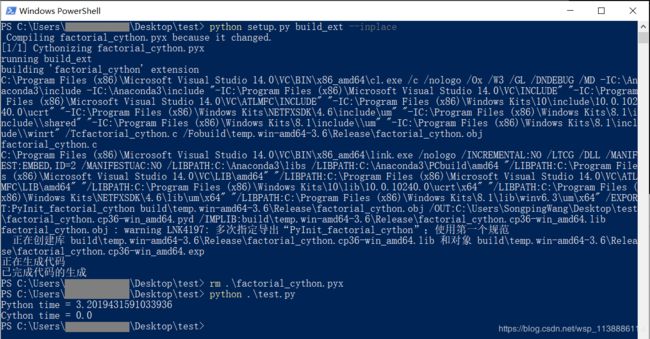
运行后目录截图:

三、Pandarallel
Linux或macOS(目前不支持Windows)
$ pip install pandarallel -U [--user]
from pandarallel import pandarallel
pandarallel.initialize() # 初始化
采用4个可选参数:
shm_size_mb:->int 共享内存的大小,以MB为单位。默认2 GB。nb_workers:->int 多进程数量。默认情况下,它设置为操作系统所见的内核数。(int)progress_bar:-> bool 将其True显示以显示进度条。verbose:-> int 详细程度。> 1显示所有日志,-1仅显示初始化日志-<1不显示日志(int)
警告:进度条是实验性功能。这会导致相当大的性能损失。不适用于DataFrameGroupy.parallel_apply。
一个4核超线程CPU将向操作系统显示8个CPU,但实际上只有4个物理计算单元。
使用df pandas DataFrame,series pandas系列,func应用/映射函数。args1,args2一些参数和col_name列名
| 没有并行化 | 通过并行化 |
|---|---|
df.apply(func) |
df.parallel_apply(func) |
df.applymap(func) |
df.parallel_applymap(func) |
df.groupby(args).apply(func) |
df.groupby(args).parallel_apply(func) |
df.groupby(args1).col_name.rolling(args2).apply(func) |
df.groupby(args1).col_name.rolling(args2).parallel_apply(func) |
series.map(func) |
series.parallel_map(func) |
series.apply(func) |
series.parallel_apply(func) |
series.rolling(args).apply(func) |
series.rolling(args).parallel_apply(func) |
以下代码测试环境:CPU:i5-8300H,内存:16GB,系统:ubuntu16.04桌面版
示例一:df.apply—df.applymap
import pandas as pd
import numpy as np
from pandarallel import pandarallel
pandarallel.initialize(nb_workers=4)
DataFrame.apply
df_size = int(4e6) # df_size= 4000000
df = pd.DataFrame(dict(a=np.random.randint(1, 8, df_size),b=np.random.rand(df_size)))
def func(x):
return (x.a**2) + (x.b**2)
t1 = time.time()
res = df.apply(func, axis=1)
t2 = time.time()
res_parallel = df.parallel_apply(func, axis=1)
t3 = time.time()
print('apply Cost time is: ',t2-t1)
print('parallel_apply Cost time is: ',t3-t2)
res.equals(res_parallel)
'''
apply Cost time is: 68.55161595344543
parallel_apply Cost time is: 17.804867267608643
True
'''
DataFrame.applymap
df_size = int(1e7)
df = pd.DataFrame(dict(a=np.random.randint(1, 8, df_size),b=np.random.rand(df_size)))
def func(x):
return (x**3) - (x**3)
t1 = time.time()
res = df.applymap(func)
t2 = time.time()
res_parallel = df.parallel_applymap(func)
t3 = time.time()
print('apply Cost time is: ',t2-t1)
print('parallel_apply Cost time is: ',t3-t2)
res.equals(res_parallel)
'''
apply Cost time is: 12.214251041412354
parallel_apply Cost time is: 3.4679696559906006
True
'''
示例二:df.groupby.apply—df.groupby.rolling.apply
DataFrame.groupby.apply
以下代码均省略:t1、t2、t3 的计时代码及输出,格式同上。
df_size = int(1e6)
df = pd.DataFrame(dict(a=np.random.randint(1, 300, df_size),b=np.random.rand(df_size)))
def func(x):
return x.iloc[0] + x.iloc[1] ** 2+ x.iloc[2] ** 3+ x.iloc[3] ** 4
res = df.groupby('a').b.rolling(4).apply(func, raw=False)
res_parallel = df.groupby('a').b.rolling(4).parallel_apply(func, raw=False)
'''
apply Cost time is: 70.49054002761841
parallel_apply Cost time is: 28.876832008361816
True
'''
示例三:Series.map—Series.apply—Series.rolling.apply
Series.map
df_size = int(5e7)
df = pd.DataFrame(dict(a=np.random.rand(df_size) + 1))
def func(x):
return np.log10(np.sqrt(np.exp(x**2)))
res = df.a.map(func)
res_parallel = df.a.parallel_map(func)
'''
apply Cost time is: 141.98869800567627
parallel_apply Cost time is: 38.93494367599487
True
'''
Series.apply
df_size = int(3.5e7)
df = pd.DataFrame(dict(a=np.random.rand(df_size) + 1))
def func(x, power, bias=0):
return np.log10(np.sqrt(np.exp(x**power))) + bias
res = df.a.apply(func, args=(2,), bias=3)
res_parallel = df.a.parallel_apply(func, args=(2,), bias=3)
'''
apply Cost time is: 70.49054002761841
parallel_apply Cost time is: 28.876832008361816
True
'''
Series.rolling.apply
df_size = int(1e6)
df = pd.DataFrame(dict(a=np.random.randint(1, 8, df_size),
b=list(range(df_size))))
def func(x):
return x.iloc[0] + x.iloc[1] ** 2+ x.iloc[2] ** 3+ x.iloc[3] ** 4
res = df.b.rolling(4).apply(func, raw=False)
res_parallel = df.b.rolling(4).parallel_apply(func, raw=False)
'''
apply Cost time is: 56.041351079940796
parallel_apply Cost time is: 14.701149225234985
True
'''
pandarallel 不支持匿名函数
from pandarallel import pandarallel
from math import sin
pandarallel.initialize()
# FORBIDDEN
# df.parallel_apply(lambdax: sin(x**2), axis=1)
# ALLOWED
def func(x):
return sin(x**2)
df.parallel_apply(func, axis=1)
https://arrow.apache.org/docs/python/plasma.html #using-arrow-and-pandas-with-plasma
警告
1、进度条是一项实验性功能。这可能导致相当大的性能损失。parallel_apply不能用于DataFrameGroupy.parallel_apply。
2、并行化是有条件的(实现新进程,通过共享内存发送数据等等),所以只有当并行化的计算量足够高时,并行化才有效。
3、应用的函数不应该是lambda函数。
四、Dask
官网:https://docs.dask.org/en/latest/
Github:https://github.com/dask/dask
Dask是一个并行计算库,能在集群中进行分布式计算,能以一种更方便简洁的方式处理大数据量,与Spark这些大数据处理框架相比较,Dask更轻。Dask更侧重与其他框架,如:Numpy,Pandas,Scikit-learning相结合,从而使其能更加方便进行分布式并行计算。
Dask三种最基本的数据结构:Arrays、Dataframes以及Bags
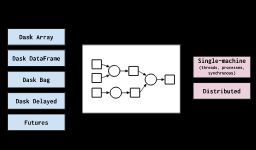
- Dask两部分组成:
-
动态任务调度针对计算进行了优化。这类似于 Airflow,Luigi,Celery或Make,但已针对交互式计算工作负载进行了优化。
“大数据”集合(如并行数组,数据帧和列表)将诸如NumPy,Pandas或Python迭代器之类的通用接口扩展到内存或分布式环境。这些并行集合在动态任务计划程序之上运行。
达斯克强调以下优点:熟悉:提供并行的NumPy数组和Pandas DataFrame对象
灵活:提供任务计划界面,以实现更多自定义工作负载并与其他项目集成。
Native:在纯Python中启用分布式计算并可以访问PyData堆栈。
快速:以低开销,低延迟和快速数值算法所需的最少序列化操作
扩大规模:在具有1000个核心的集群上弹性运行
缩小:在单个过程中轻松设置并在笔记本电脑上运行
响应式:在设计时考虑了交互式计算,它提供了快速的反馈和诊断功能,以帮助人类
4.1 简单入门:
Dask 模仿 DataFrame、NumPy 详情文档
================= DataFrame ========|========== Dask DataFrame ================
import pandas as pd import dask.dataframe as dd
df = pd.read_csv('2015-01-01.csv') df = dd.read_csv('2015-*-*.csv')
df.groupby(df.user_id).value.mean() df.groupby(df.user_id).value.mean().compute()
================= NumPy ============|============ Dask NumPy ================
import numpy as np import dask.array as da
f = h5py.File('myfile.hdf5') f = h5py.File('myfile.hdf5')
x = np.array(f['/small-data']) x = da.from_array(f['/big-data'],
chunks=(1000, 1000))
x - x.mean(axis=1) x - x.mean(axis=1).compute()
Dask Bag模仿了迭代器,Toolz和PySpark详情文档
import dask.bag as db
b = db.read_text('2015-*-*.json.gz').map(json.loads)
b.pluck('name').frequencies().topk(10, lambda pair: pair[1]).compute()
Dask延迟的模仿循环和包装自定义代码详情文档
from dask import delayed
L = []
for fn in filenames: # 用于循环以建立计算
data = delayed(load)(fn) # 延迟执行功能
L.append(delayed(process)(data)) # 在变量之间建立连接
result = delayed(summarize)(L)
result.compute()
数据结构:https://blog.csdn.net/jack_jmsking/article/details/91433854
使用查看:https://blog.csdn.net/qq_14959801/article/details/80878007
五、Rapids
待续
https://blog.csdn.net/sunhf_csdn/article/details/83538591