ElasticSearch IK中文分词使用详解
一、前言
对于ES IK分词插件在中文检索中非常常用,本人也使用了挺久的。但知识细节一直很碎片化,一直没有做详细的整理。过一段时间用的话,也是依然各种找资料,也因此会降低开发效率。所以在有空的时候好好整理下相关资料。也希望本文对使用 ElasticSearch 和 IK分词插件的开发者有所帮助。希望能少走点弯路。
本文包括前言、IK分词介绍、分词效果对比、自定义词典使用、索引设置和字段设置(Python 创建索引并导入数据)、查询测试(Python 查询)、结论等七个部分。
二、IK分词介绍
IK分词器插件的安装、测试、自定义词典的使用可直接参考。github上的资料:https://github.com/medcl/elasticsearch-analysis-ik
这里注意三点:
1. 注意ElasticSearch和IK插件版本的对应。
2. 在ElasticSearch的配置文件config/elasticsearch.yml中的最后一行添加参数 index.analysis.analyzer.default.type: ik,则设置所有索引的默认分词器为ik分词(也可以不这么做,通过设置mapping来使用ik分词)。
3. 强调下IK分词器的两种分词模式。
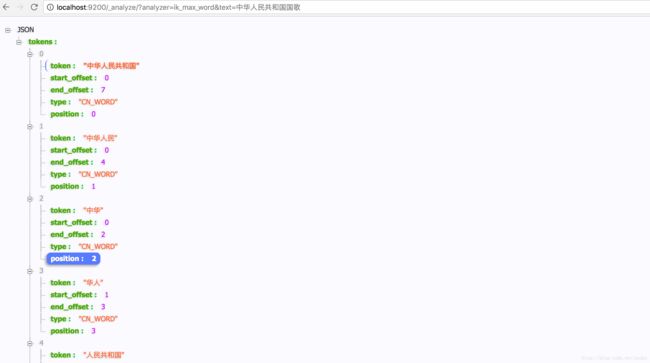
ik_max_word: 会将文本做最细粒度的拆分,比如会将"中华人民共和国国歌"拆分为"中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌",会穷尽各种可能的组合;
ik_smart: 会做最粗粒度的拆分,比如会将"中华人民共和国国歌"拆分为"中华人民共和国,国歌"。
验证 IK 安装成功,并测试两种分词模式:
http://localhost:9200/_analyze/?analyzer=ik_smart&text=中华人民共和国国歌

http://localhost:9200/_analyze/?analyzer=ik_max_word&text=中华人民共和国国歌
三、分词效果对比
基于github上给的资料
1 创建2个索引ik_test和 ik_test_1
curl -XPUT http://localhost:9200/ik_test
curl -XPUT http://localhost:9200/ik_test_1
2 对 ik_test 索引设置mapping
curl -XPOST http://localhost:9200/ik_test/fulltext/_mapping -d'
{
"fulltext": {
"_all": {
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word",
"term_vector": "no",
"store": "false"
},
"properties": {
"content": {
"type": "string",
"store": "no",
"term_vector": "with_positions_offsets",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word",
"include_in_all": "true",
"boost": 8
}
}
}
3 对两个索引插入数据
curl -XPOST http://localhost:9200/ik_test/fulltext/1 -d'
{"content":"美国留给伊拉克的是个烂摊子吗"}
'
curl -XPOST http://localhost:9200/ik_test/fulltext/2 -d'
{"content":"公安部:各地校车将享最高路权"}
'
curl -XPOST http://localhost:9200/ik_test/fulltext/3 -d'
{"content":"中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"}
'
curl -XPOST http://localhost:9200/ik_test/fulltext/4 -d'
{"content":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"}
'
curl -XPOST http://localhost:9200/ik_test_1/fulltext/1 -d'
{"content":"美国留给伊拉克的是个烂摊子吗"}
'
curl -XPOST http://localhost:9200/ik_test_1/fulltext/2 -d'
{"content":"公安部:各地校车将享最高路权"}
'
curl -XPOST http://localhost:9200/ik_test_1/fulltext/3 -d'
{"content":"中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"}
'
curl -XPOST http://localhost:9200/ik_test_1/fulltext/4 -d'
{"content":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"}
'
4 对两个索引分别搜索
curl -XPOST http://localhost:9200/ik_test/fulltext/_search?pretty -d'{
"query" : { "match" : { "content" : "洛杉矶领事馆" }},
"highlight" : {
"pre_tags" : ["", ""],
"post_tags" : [" ", ""],
"fields" : {
"content" : {}
}
}
}'
结果如下:

curl -XPOST http://localhost:9200/ik_test_1/fulltext/_search?pretty -d'{
"query" : { "match" : { "content" : "洛杉矶领事馆" }},
"highlight" : {
"pre_tags" : ["", ""],
"post_tags" : [" ", ""],
"fields" : {
"content" : {}
}
}
}'
结果如下:

四、自定义词典使用
自定义词典使用,按照github上的说明配置词典。在 custom/mydict.dic 文件中增加 “洛杉矶领事馆” 一词,然后重启ES。自定义词典使用参考:https://github.com/medcl/elasticsearch-analysis-ik
使用如下搜索:
curl -XPOST http://localhost:9200/ik_test/fulltext/_search?pretty -d'{
"query" : { "match" : { "content" : "洛杉矶领事馆" }},
"highlight" : {
"pre_tags" : ["", ""],
"post_tags" : [" ", ""],
"fields" : {
"content" : {}
}
}
}'
结果如下:

从结果可见,貌似自定义词典没有起作用。是的、、、这里困扰我很久的,一直以为这功能有问题。后多次测试后发现,继续插入数据的话,对以后的数据是能正确分词的。
在修改自定义词典之后,插入第5条数据,content字段和第4条数据是一样的。
curl -XPOST http://localhost:9200/ik_test/fulltext/5 -d'
{"content":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"}'
然后继续用上述的query 进行搜索。

结果查到 _id =4 和 _id =5 的两条数据,其中 _id =5 就是我们想要的结果,_id =4 按理来说确实是我们想要的结果。但是结果结果却把”洛杉矶领事馆” 切成了两个词语。
猜测和 ES中存储以及match 搜索方式有关。
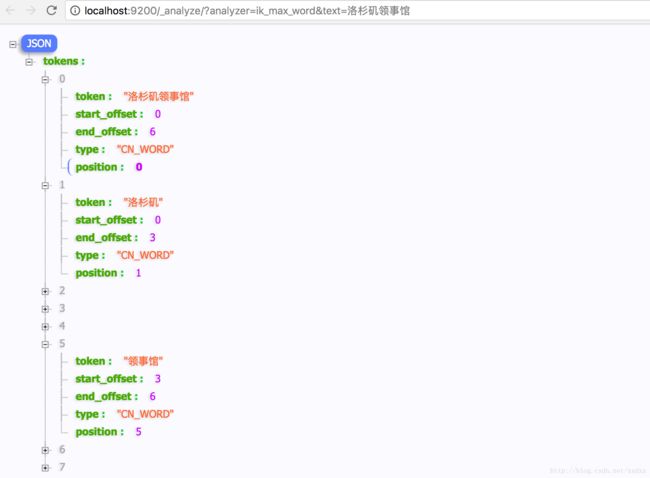
“洛杉矶领事馆” 一词在 _id = 4的文档中存为:“洛杉矶”、“领事馆”、“洛”、“杉”、“矶”、“领事”、“馆” 等7个词语。
“洛杉矶领事馆” 一词在 _id = 5的文档中存为:“洛杉矶领事馆”、“洛杉矶”、“领事馆”、“洛”、“杉”、“矶”、“领事”、“馆” 等8个词语。
分词结果如下:
http://localhost:9200/_analyze/?analyzer=ik_max_word&text=洛杉矶领事馆
还有这里如果用 term 方式进行搜索。
curl -XPOST http://localhost:9200/ik_test/fulltext/_search?pretty -d'{
"query" : { "term" : { "content" : "洛杉矶领事馆" }},
"highlight" : {
"pre_tags" : ["", ""],
"post_tags" : [" ", ""],
"fields" : {
"content" : {}
}
}
}'

结果只搜到了_id =5的文档。因此,这里验证了我的两个猜测:
- match 和 term 的搜索方式不同。参考:http://www.cnblogs.com/yjf512/p/4897294.html
- ES底层存储有关:不然的话用term搜索,应该把 _id =4 和_id=5全部搜索出来,这里之所以 _id=4没有搜出来是因为 _id=4 的底层在ES中的存储不包含“洛杉矶领事馆” 这整体一词。
五、索引设置和字段设置
这里主要是mapping得设置,可以使用IK给的 mapping 格式:
{
"fulltext": {
"_all": {
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word",
"term_vector": "no",
"store": "false"
},
"properties": {
"content": {
"type": "string",
"store": "no",
"term_vector": "with_positions_offsets",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word",
"include_in_all": "true",
"boost": 8
}
}
}
}
以上参数不详细说明,可参考:https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-params.html
关于_all字段的介绍,可参考:http://blog.csdn.net/jiao_fuyou/article/details/49800969
我使用的mapping和插入数据代码如下,这里设置不使用 _all字段搜索:
# -*- coding: utf-8 -*-
import elasticsearch
class ElasticSearchClient(object):
@staticmethod
def get_es_servers():
es_servers = [{
"host": "localhost",
"port": "9200"
}]
es_client = elasticsearch.Elasticsearch(hosts=es_servers)
return es_client
class LoadElasticSearch(object):
def __init__(self):
self.index = "hz"
self.doc_type = "text"
self.es_client = ElasticSearchClient.get_es_servers()
self.set_mapping()
def set_mapping(self):
"""
设置mapping
"""
chinese_field_config = {
"type": "string",
"store": "no",
"term_vector": "with_positions_offsets",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word",
"include_in_all": "true",
"boost": 8
}
mapping = {
self.doc_type: {
"_all": {"enabled": False},
"properties": {
"document_id": {
"type": "integer"
},
"content": chinese_field_config
}
}
}
if not self.es_client.indices.exists(index=self.index):
# 创建Index和mapping
self.es_client.indices.create(index=self.index, ignore=400)
self.es_client.indices.put_mapping(index=self.index, doc_type=self.doc_type, body=mapping)
def add_date(self, row_obj):
"""
单条插入ES
"""
_id = row_obj.get("_id", 1)
row_obj.pop("_id")
self.es_client.index(index=self.index, doc_type=self.doc_type, body=row_obj, id=_id)
if __name__ == '__main__':
content_ls = [
u"美国留给伊拉克的是个烂摊子吗",
u"公安部:各地校车将享最高路权",
u"中韩渔警冲突调查:韩警平均每天扣1艘中国渔船",
u"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"
]
load_es = LoadElasticSearch()
# 插入单条数据测试
for index, content in enumerate(content_ls):
write_obj = {
"_id": index,
"document_id": index,
"content": content
}
load_es.add_date(write_obj)
六、查询测试
# -*- coding: utf-8 -*-
import elasticsearch
class ElasticSearchClient(object):
@staticmethod
def get_es_servers():
es_servers = [{
"host": "localhost",
"port": "9200"
}]
es_client = elasticsearch.Elasticsearch(hosts=es_servers)
return es_client
class SearchData(object):
index = 'hz'
doc_type = 'text'
@classmethod
def search(cls, field, query, search_offset, search_size):
# 设置查询条件
es_search_options = cls.set_search_optional(field, query)
# 发起检索。
es_result = cls.get_search_result(es_search_options, search_offset, search_size)
# 对每个结果, 进行封装。得到最终结果
final_result = cls.get_highlight_result_list(es_result, field)
return final_result
@classmethod
def get_highlight_result_list(cls, es_result, field):
result_items = es_result['hits']['hits']
final_result = []
for item in result_items:
item['_source'][field] = item['highlight'][field][0]
final_result.append(item['_source'])
return final_result
@classmethod
def get_search_result(cls, es_search_options, search_offset, search_size):
es_result = ElasticSearchClient.get_es_servers().search(
index=cls.index,
doc_type=cls.doc_type,
body=es_search_options,
from_=search_offset,
size=search_size
)
return es_result
@classmethod
def set_search_optional(cls, field, query):
es_search_options = {
"query": {
"match": {
field: {
"query": query,
"slop": 10
}
}
},
"highlight": {
"fields": {
"*": {
"require_field_match": True,
}
}
}
}
return es_search_options
if __name__ == '__main__':
final_results = SearchData().search("content", "中国", 0, 30)
for obj in final_results:
for k, v in obj.items():
print k, ":", v
print "======="
输出结果:

七、结论
到此为止,ik分词相关的操作,都已经介绍完了。其他还有可能会使用到的功能就是基于IK的中文同义词处理的。参考这篇文章:http://blog.csdn.net/xsdxs/article/details/52806499 即可。
文中也实现了,搜索相关的功能。不过更加详细的内容,此文先不介绍了,下篇文章会对ElasticSearch 的搜索进行讲解和实现。
感谢阅读!