30分钟概览Spark Streaming 实时计算
本文主要介绍四个问题:
- 什么是Spark Streaming实时计算?
- Spark实时计算原理流程是什么?
- Spark 2.X下一代实时计算框架Structured Streaming
- Spark Streaming相对其他实时计算框架该如何技术选型?
本文主要针对初学者,如果有不明白的概念可了解之前的博客内容。
1、什么是Spark Streaming?
与其他大数据框架Storm、Flink一样,Spark Streaming是基于Spark Core基础之上用于处理实时计算业务的框架。其实现就是把输入的流数据进行按时间切分,切分的数据块用离线批处理的方式进行并行计算处理,原理如下图。
(什么是Spark Core ?Spark Core就是基于RDD数据抽象用于数据并行处理的基础组件,详细可参考 Spark 核心API开发 了解RDD算子)
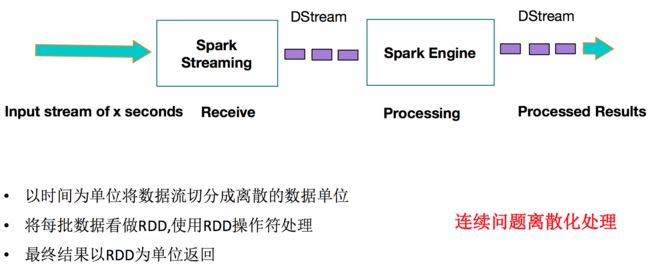
输入的数据流经过Spark Streaming的receiver,数据切分为DStream(类似RDD,DStream是Spark Streaming中流数据的逻辑抽象),然后DStream被Spark Core的离线计算引擎执行并行处理。
简言之,Spark Streaming就是把数据按时间切分,然后按传统离线处理的方式计算。从计算流程角度看就是多了对数据收集和按时间节分。
2、Spark实时计算原理流程是什么?
下面将从更细粒度架构角度看Spark Streaming的执行原理,这里先回顾一下Spark框架执行流程。
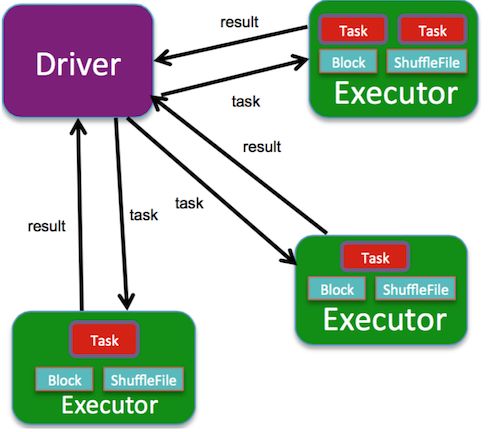
Spark计算平台有两个重要角色,Driver和executor,不论是Standlone模式还是Yarn模式,都是Driver充当Application的master角色,负责任务执行计划生成和任务分发及调度;executor充当worker角色,负责实际执行任务的task,计算的结果返回Driver。
下图是Driver和Ececutor的执行流程。
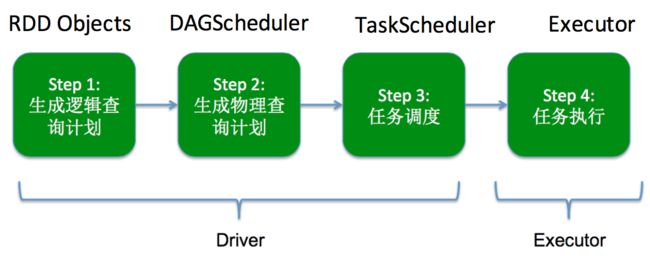
Driver负责生成逻辑查询计划、物理查询计划和把任务派发给executor,executor接受任务后进行处理,离线计算也是按这个流程进行。
下面看Spark Streaming实时计算的执行流程。
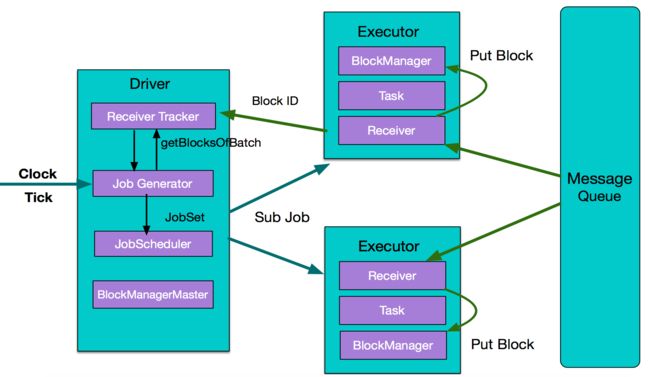
从整体上看,实时计算与离线计算一样,主要组件是Driver和Executor的。不同的是多了数据采集和数据按时间分片过程,数据采集依赖外部数据源,这里用MessageQueue表示,数据分片则依靠内部一个时钟Clock,按batch interval来定时对数据分片,然后把每一个batch interval内的数据提交处理。
Executor从MessageQueue获取数据并交给BlockManager管理,然后把元数据信息BlockID返给driver的Receiver Tracker,driver端的Job Jenerator对一个batch的数据生成JobSet,最后把作业执行计划传递给executor处理。
##3、Spark 2.X下一代实时计算框架Structured Streaming
####1)为什么产生下一代Structured Streaming?
目前的Spark Streaming计算逻辑是把数据按时间划分为DStream,当前问题在于:
- 框架自身只能根据Batch time单元进行数据处理,很难处理基于event time(即时间戳)的数据,很难处理延迟,乱序的数据
- 流式和批量处理的API还是不完全一致,两种使用场景中,程序代码还是需要一定的转换
- 端到端的数据容错保障逻辑需要用户自己小心构建,难以处理增量更新和持久化存储等一致性问题
基于以上问题,提出了下一代Structure Streaming
####2) Structure Streaming是什么?
将数据抽象为DataFrame,即无边界的表,通过将数据源映射为一张无界长度的表,通过表的计算,输出结果映射为另一张表。这样以结构化的方式去操作流式数据,简化了实时计算过程,同时还复用了其Catalyst引擎来优化SQL操作。此外还能支持增量计算和基于event time的计算。
下图为Structure Streaming逻辑数据结构图:
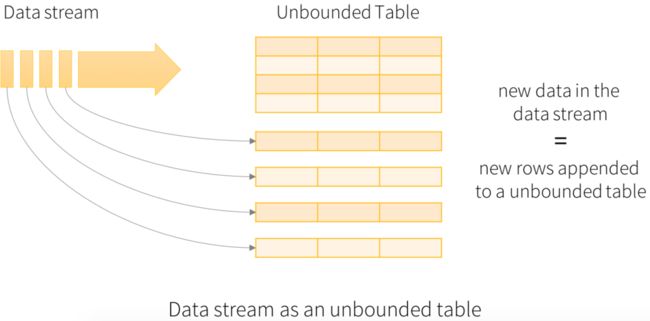
输入的实时数据根据先后作为row添加到一张无界表中。
这里以wordcount为例的计算过程如下图:
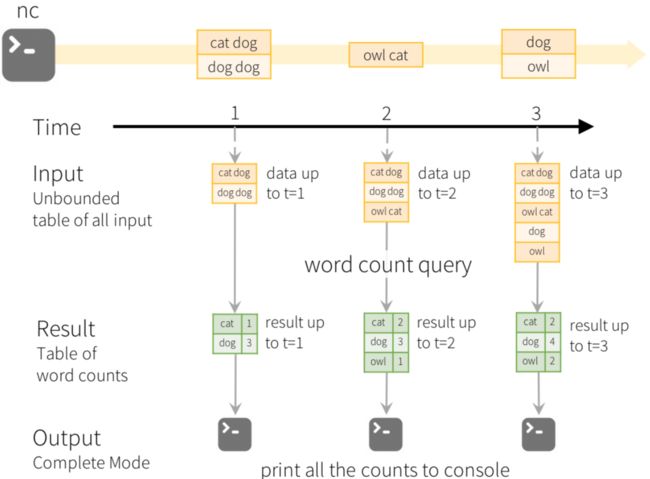
图中Time横轴是时间轴,随着时间,在1、2、3秒分别输入数据,进入wordcount算法计算聚合,输出结果。更对关于Structure Streaming可以参考官网。
##4、相对其他实时计算框架该如何技术选型?
一张图介绍:
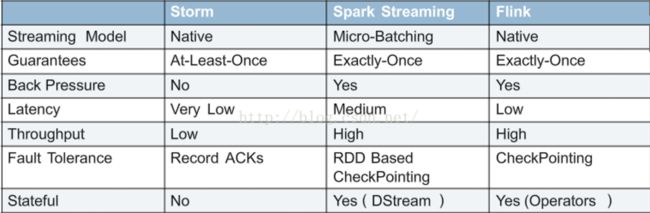
这里只介绍最主流的,也是国内在技术选型中考虑最多的三种。
从延迟看:Storm和Flink原生支持流计算,对每条记录处理,毫秒级延迟,是真正的实时计算,对延迟要求较高的应用建议选择这两种。Spark Streaming的延迟是秒级。
从容错看 :Spark Streaming和Flink都支持最高的exactly-once容错级别,Storm会有记录重复计算的可能
从吞吐量看 :Spark Streaming是小批处理,故吞吐量会相对更大。
从成熟度看: Storm最成熟,Spark其次,Flink处于仍处于发展中,这三个项目都有公司生产使用,但毕竟开源项目,项目越不成熟,往往越要求公司大数据平台研发水平。
从整合性看:Storm与SQL、机器学习和图计算的结合复杂性最高;而Spark和Flink都有生态圈内对应的SQL、机器学习和图计算,与这些项目结合更容易。
公司可以根据需求进行技术选型。
####参考资料:
Spark 2.0 Structured Streaming 分析
Structure Streaming官网资料
文章会同步到公众号,关注公众号,交流更方便: