30分钟概览Spark分布式计算引擎
本文主要帮助初学者快速了解Spark,不会面面俱到,但核心一定点到。
详细内容可参考Spark入门教程-1
Spark是继Hadoop之后的下一代分布式内存计算引擎,于2009年诞生于加州大学伯克利分校AMPLab实验室,现在主要由Databricks公司进行维护(公司创始员工均来自AMPLab),根据本人自2014学习Spark的理解,从下面几个方面介绍。
1、为什么出现Spark?
2、Spark核心是什么?
3、Spark怎么进行分布式计算?
4、Spark在互联网公司的实践应用?
1、为什么出现Spark?
肯定是比Hadoop的MR计算要好,好在如下方面:
- 高效
- 多框架整合
1)为什么高效?
- 相对于Hadoop的MR计算,Spark支持DAG,能缓存中间数据,减少数据落盘次数;
- 使用多线程启动task,更轻量,任务启动快。计算速度理论上有10-100倍提升。(根据个人工作验证,计算效率相对Hadoop至少是3倍以上)
- 高度抽象API,代码比MR少2-5倍甚至更多,开发效率高
2)为什么多框架整合?
相对于过去使用Hadoop + Hive + Mahout + Storm 解决批处理、SQL查询和实时处理和机器学习场景的大数据平台架构,其最大的问题在于不同框架语言不同,整合复杂,同时也需要更多维护成本。
而使用Spark在Spark core的批处理基础上,建立了Spark Sql、Spark Streaming,Spark Mllib,Spark GraphX来解决实时计算,机器学习和图计算场景,方便将不同组件功能进行整合,同时维护成本小。
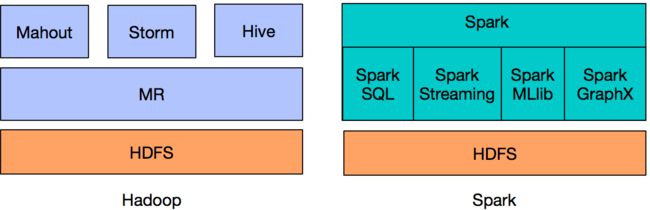
上图就体现了Spark的One Stack Rule All的设计目标。
###2、Spark核心是什么?###
核心是RDD(Resilient Distributed Datasets),即弹性分布式数据集。
它是对数据的高度抽象概念,弹性可理解为数据存储弹性,可内存,可磁盘; 分布式可理解为数据分布在不同节点。
RDD是分布式数据的逻辑抽象,物理数据存储在不同的节点上,但对用户透明,用户不需要知道数据实际存在哪台机器。RDD包含的内容下图所示:

-
只读分区集合:这保证了RDD的一致性,在计算过程中更安全可靠,此外RDD可能包含多个分区,数据分布在不同分区中,这些分区可能在不同的机器上。
-
对数据的计算函数:RDD包含了对所表示数据的计算函数,也就是得到这个RDD所要经过的计算。
-
计算数据的位置:对用户而言不需要知道数据在哪里,这些信息隐含在RDD的结构中。
-
分区器:对数据分区依赖的分区算法,如hash分区器
-
依赖的RDD信息:该RDD可能依赖的父RDD信息,用于失败重算或计算的DAG划分。
####1 ) RDD的计算分为transformation和action两类。
- transformation有 flatMap、map、union、reduceByKey等。
- action有count、collect、saveAsTextFile等表示输出的操作。
RDD的计算是lazy的,transformation算子不会引发计算,只是逻辑操作,action算子才会引发实际的计算。
####2)RDD算子的宽窄依赖
下图解释什么是宽依赖,什么是窄依赖
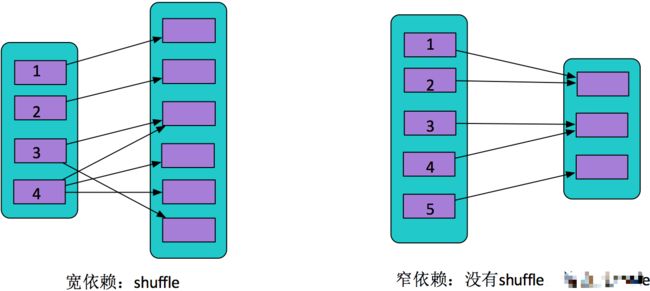
图中左边是宽依赖,父RDD的4号分区数据划分到子RDD的多个分区(一分区对多分区),这就表明有shuffle过程,父分区数据经过shuffle过程的hash分区器(也可自定义分区器)划分到子RDD。
那图中右边为什么是窄依赖?父RDD的每个分区的数据直接到子RDD的对应一个分区(一分区对一分区),例如1号到5号分区的数据都只进入到子RDD的一个分区,这个过程没有shuffle。Spark中Stage的划分就是通过shuffle来划分。
(shuffle可理解为数据的从原分区打乱重组到新的分区)
当明白了Spark分布式计算核心就是RDD之后,下面看Spark如何实现分布式计算。
###3、怎么进行分布式计算?###
当初我学习Spark,也是一知半解,当理解RDD的内涵,才理解Spark分布式计算过程。
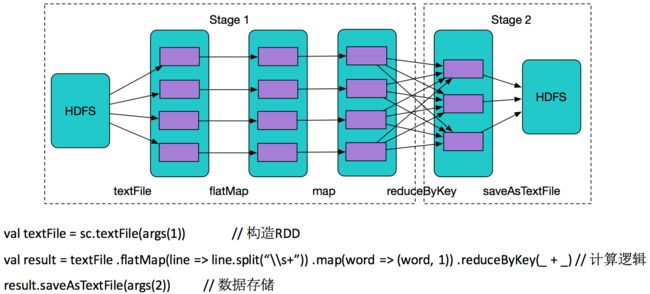
上图是一个Spark的wordcount例子,根据上述stage划分原则,这个job划分为2个stage,有三行,分别是数据读取、计算和存储过程。
仅看代码,用户根本体会不到数据在背后是并行计算。从图中能看出数据分布在不同分区(也可以理解不同机器上),数据经过flapMap、map和reduceByKey算子在不同RDD的分区中流转。(这些算子就是上面所说对RDD进行计算的函数)
下图从更高角度看:
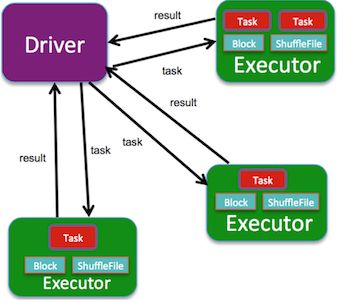
Spark的运行架构由Driver(可理解为master)和Executor(可理解为worker或slave)组成,Driver负责把用户代码进行DAG切分,划分为不同的Stage,然后把每个Stage对应的task调度提交到Executor进行计算,这样Executor就并行执行同一个Stage的task。
(这里Driver和Executor进程一般分布在不同机器上)
这里有人可能不理解Stage和task,下图就是Spark的作业划分层次:
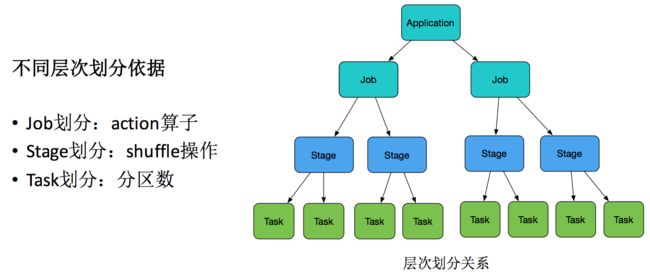
Application就是用户submit提交的整体代码,代码中又有很多action操作,action算子把Application划分为多个job,job根据宽依赖划分为不同Stage,Stage内划分为许多(数量由分区决定,一个分区的数据由一个task计算)功能相同的task,然后这些task提交给Executor进行计算执行,把结果返回给Driver汇总或存储。
这体现了 Driver端总规划–Executor端分计算–结果最后汇总回Driver 的思想,也就是分布式计算的思想。
###4、Spark在互联网公司的实践应用###
根据个人工作经历,BAT大公司都直接或间接使用Spark(说间接是可能自主研发分布式计算引擎,但参考Spark设计思想)。中小公司大多已经采用Spark,并逐渐从MR计算迁移到Spark计算。
- Spark在生产上可以通过zeppelin提供adhoc(即席查询)服务。
- Spark Sql可以替代Hive的ETL工作,但需要对generic UDF和UDAF进行重写。
- 可以基于Spark搭建特征工程平台和机器学习平台
- Spark Streaming实时计算延迟是秒级,支持exactly-once要求的数据消费,可以做实时ETL,也可以结合Spark MLlib处理来做实时机器学习。Spark的下一代Structured Streaming的使用更简单。
以上就是30分钟Spark概览内容,有兴趣可继续了解30分钟概览Spark Streaming 实时计算。
新文章会同步到公众号,关注公众号,交流更方便: