Python小白的数据库入门
文章目录
- 前言
- SQL数据库
- 数据库SQL语言入门
- SQL简介
- SQL 的作用
- SQL语句分类
- SQLite 数据库
- SQLite 中的数据类型
- DDL语句
- 创建表
- 删除表
- 修改表
- DML语句
- 添加
- 删除
- 修改
- 查询
- Python中的SQLite
- 操作SQLite
- 游标对象
- SQLite防注入
- 数据库可视化
- 归纳总结
- 欢迎关注我的公众号:编程之路从0到1
前言
可以毫不夸张的说,不懂数据库,不是真正的程序员。纷繁复杂,界面绚丽的程序,最本质的无非都是在操作数据而已。既然有数据,那就肯定需要一个东西去存放并管理这些数据,而数据库就是这么一个软件。
有些人可能没有直接接触过数据库,但我相信大部分人都用过Excel这种表格工具。实际上,它就相当于一个简单的数据库,与之相比,更贴切的可能是 Access数据库。
在学习数据库之前,我们先看看数据库到底长什么样子,得先有感性认识才行
这是MySql数据库

这是Sqlite3数据库

以上两个是主流的关系型数据库,我们观察之后发现,它们与我们熟知的Excel好像也没有什么不同。关系型数据库里面放的都是一张张的表,就如同Excel中的工作簿。就算不熟悉Excel,但每一张表也都是我们从小到大所熟悉的那种表结构,例如课程表、值日表之类的。
与Excel不同的是,数据库提供了快速的、高效的编程接口,可以让我们非常简洁、灵活的以代码去操作这个数据库,例如删除一条数据、新增一条数据、对数据进行排序,就想我们经常对价格、销量、好评排序那样。这些都是Excel无法比拟的。
SQL数据库
所谓数据库,即存储数据的仓库。每一个数据库可以存放若干个数据表,这里的数据表就是我们通常所说的二维表,分为行和列,每一行称为一条记录,每一列称为一个字段。表中的列是固定的,可变的是行。要注意,我们通常需要在列中指定数据的类型,在行中添加数据,即我们每次添加一条记录,就添加一行,而不是添加一列。对数据库的操作可以概括为就是向数据库中添加、删除、修改和查询数据,其中查询功能最为复杂。
先简单了解了一下数据库,接下来学习一下数据库相关的概念。
数据库SQL语言入门
SQL简介
结构化查询语言(Structured Query Language)简称SQL,是一种特殊目的的编程语言,是一种数据库查询和设计语言,用于存取数据以及查询、更新和管理关系数据库系统.
简而言之,SQL就是一种脚本编程语言,是绝大多数数据库的通用语言。没错,刚学会Python,接下来又得学习新的语言……不过,对于非DBD(Database Desktop,数据库维护人员)的开发人员而言,并不需要对SQL语言掌握得太深入,SQL的基本用法实际上是比Python还简单的。
SQL 的作用
- SQL 面向数据库执行查询
- SQL 可在数据库中插入新的记录
- SQL 可更新数据库中的数据
- SQL 可从数据库删除记录
- SQL 可在数据库中创建新表
- SQL 可在数据库中创建视图
SQL语句分类
共分为四种
-
DDL(data definition language)数据定义语言
主要是对数据库中的表以及表中的列等的定义和操作 -
DML(data manipulation language)数据操纵语言
对数据库里的表中数据进行操作的语言 -
DCL(Data Control Language)数据库控制语言
-
TCL(Transaction Control Language)事务控制语言
其中DDL和DML是最常用的语言,是重中之重,其他两种忽略
SQLite 数据库
SQLite 是一款轻型的嵌入式数据库,占用资源及其低,这是它受人青睐的原因之一,在嵌入式设备(如手机)中只需要几百 K 的内存即可。它不仅支持数据库通用的增删改查,还支持事务功能,功能还比较强大。
SQLite 数据库实际上就是一个文件,这个文件的后缀名通常是 .db,database的缩写,它的第一个版本诞生于 2000 年,最近版本为 SQLite3。
除了SQLite数据库,还有其他几种常见的数据库,例如Oracle、SQL Server、MySQL等等
这里我们选取SQLite作为入门来学习数据库,因为它搭建非常简单,极容易上手。与之相比,其他的数据库都需安装,配置,启动服务等等操作。而Python在标准库已经自带了这种数据库。
SQLite 中的数据类型
数据库是存储数据的,它自然会对数据的类型进行划分,SQLite 划分有五种数据类型(不区分大小写)
NULL类型,取值为 NULL,表示没有或者为空INTERGER类型,取值为带符号的整数,即可为负整数REAL类型,取值为浮点数TEXT类型,取值是字符串BLOB类型,是一个二进制的数据块,即字节串,可用于存放纯二进制数据,例如图片
DDL语句
简单说,其实主要就是用来创建表的,当然也可以删除表,或者修改表的定义,比如原表只有三列,现在需要五列,就要修改表的定义
- 概念理解
- 表: 可以理解为我们通常所说的二维表,分为横纵(行列),用于存放数据
- 字段: 就是表中的列名
- 主键: 就是一种特殊的列。每一行数据的主键不能相同,是这一行数据的唯一标识,就像人的身份证号
创建表
create table 表名称(列名1 类型 配置, 列名2 类型 配置, 列名3 类型 配置);
注意,SQL语言是不区分大小写的,create 也可以写成CREATE。另外,每一句SQL语句后面都需要一个;号结尾
示例:
create table contacts (
id integer primary key autoincrement,
name text not null ,
phone text not null default 'unknow');
上面的DDL语句创建了一个叫contacts的表,并且定义了三个列,分别是id、name和phone,并且给每一个列定义了数据类型,分别是integer、text、text,这表明,id只能是一个整数,name和phone只能是字符串。
除了这些,还对每一个列做了一些配置,或者叫约束。
primary key autoincrement 的意思是指将id这个列定义为主键,并且从1开始自动增长,也就是说id这个列不需要人为的手动去插入数据,它会自动增长。
not null 指明这一列不能为空,当你插入数据时,如果不插入name或者phone的值,那么就会报错,无法完成这一次插入。
default 'unknow' default关键字代表设置默认值,这里指定它默认值是字符串'unkonw',当不插入这一列数据时,默认就是这个值。此处写法是有些多余的,它与not null 一起用是没有意义的,因为not null已经指明这一列必须插入,不可能为null,那就不需要默认值了,当然,此处只是为了演示default的用法
特别注意
当Python程序运行建表语句时,如果表已经存在了,再去创建一遍会报错崩溃,因为你的程序第一次运行时执行了一遍建表语句,第2次第3次…去执行,表已经在第1次的时候创建了,这个时候就报错崩溃了。因此通常需要在建表语句中加入一个判断,判断这个表是否存在。
create table if not exists stu_info(
id integer primary key autoincrement,
name text not null,
number text);
如上所示,在建表语句中增加了一个if not exists的判断,每次运行都会先判断,不存在才会执行后面的语句创建
删除表
drop table 表名称;
drop table if exists 表名称;
修改表
/* 修改表名称 */
alter table 原表名 rename to 新表名;
/* 添加新列 */
alter table 表名称 add column 列名1 类型 配置,列名2 类型 配置
示例:
alter table contacts rename to students;
alter table contacts add column email text,qq text not null;
DML语句
对数据库里的表数据进行相应的增、删、改、查的操作。注意,这里是表中的数据,而DDL则是对表的结构进行创建或修改,注意区分
添加
#想要插入的字段和值的顺序要一一对应起来
insert into 表名称 (字段1,字段2,字段3……) values (被插入的值1,值2,值3……)
insert into 表名称 values(值1,值2,值3……)
要注意,使用简略的语句,必须插入全部字段,顺序对应,不能遗漏一个
示例:
insert into stu_info (name,number,age) values("zhangsan","20171220",20);
删除
delete from 表名称 where 字段 = 条件;
# 用于删除表中所有数据,但不删除表
delete from 表名 或者 delete * from 表名
示例:
delete from stu_info where number = "20171221";
修改
update 表名称 set 字段1=值1,字段2=值2,…… where 字段 = 条件;
注意,此处值是你要修改的值,此语句可用来修改满足条件的一行或多行
示例:
update stu_info set name = "zhangsan",age=10 where number = "20171221";
查询
#查询的字段就是你要查询的列名,用*可表示查询全部字段
select 查询的字段 from 表名称 where 字段 = 条件;
#查询整张表的所有数据
select * from 表名称;
示例:
select * from food_types where name = "apple"
多表查询
如果两张表有关系,譬如,一张表是班干部表,记录了所有班干部,另一张表是全体学生表,记录每一个学生的情况,那么显然这两种表是有关系的。因为一个人既可以在学生表中,也可以在班干部表中。如果我们在班干部表中查到了他的学号,那么就可以用这个学号再去全体学生表中查出他的全部信息,包括考试成绩等等这些,这就是所谓的多表查询。
如下例,我们需要查询的是table1中的abc字段的内容,则从table1,table2两张表去查,当满足条件table1中的xxx字段的内容等于table2中的xxx字段的内容时,就返回这些符合条件的数据。
select table1.abc from table1,table2 where table1.xxx=table2.xxx;
或者等价于
select table1.abc from table1 inner join table2 on table1.xxx=table2.xxx;
特别注意
SQL语句中,text类型的字符串常量需要用单引号或者双引号括起来,推荐使用单引号。
例如:
select * from stu_info where name = 'zhangsan'
以上也就是数据库中常说的所谓CRUD操作(create、read、update、delete),分别代表对数据的增删改查。
Python中的SQLite
操作SQLite
操作该数据库的大致步骤就是连接数据库,然后对数据库进行增删改查等操作即可。
操作步骤
- 导入模块
- 连接数据库,返回连接对象
- 调用连接对象的execute()方法,执行SQL语句,进行增删改的操作,如进行了增添或者修改数据的操作,需调用commit()方法提交修改才能生效;execute()方法也可用于执行DDL语句进行创建表的操作
- 调用连接对象的cursor()方法返回游标对象,然后调用游标对象的execute()方法执行查询语句,查询数据库
- 关闭连接对象和游标对象
示例代码:
# 导入模块
import sqlite3
# 连接数据库,返回连接对象
conn = sqlite3.connect("D:/my_test.db")
# 调用连接对象的execute()方法,执行SQL语句
# (此处执行的是DDL语句,创建一个叫students_info的表)
conn.execute("""create table if not exists students_info (
id integer primary key autoincrement,
name text,
age integer,
address text)""")
# 插入一条数据
conn.execute("insert into students_info (name,age,address) values ('Tom',18,'北京东路')")
# 增添或者修改数据只会必须要提交才能生效
conn.commit()
# 调用连接对象的cursor()方法返回游标对象
cursor = conn.cursor()
# 调用游标对象的execute()方法执行查询语句
cursor.execute("select * from students_info")
# 执行了查询语句后,查询的结果会保存到游标对象中,调用游标对象的方法可获取查询结果
# 此处调用fetchall方法返回一个列表,列表中存放的是元组,
# 每一个元组就是数据表中的一行数据
result = cursor.fetchall()
#遍历所有结果,并打印
for row in result:
print(row)
#关闭
cursor.close()
conn.close()
游标对象
调用连接对象的cursor()方法可以得到一个游标对象,那么游标到底是什么呢?其实可以把游标理解为一个指针,如下图:
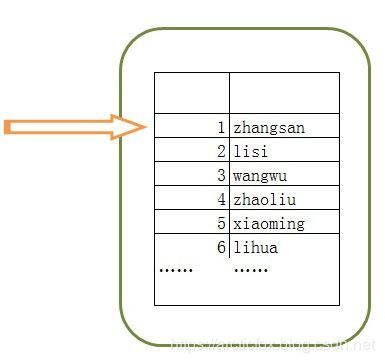
图中的指针就是游标cursor,假设右边的表就是查询到的结果,那么可以调用游标对象的fetchone()方法移动游标指针,每调用一次fetchone()方法就可以将游标指针向下移动一行,第一次调用fetchone()方法时,将游标从默认位置移动到第一行
# 调用游标对象的execute()方法执行查询语句
cursor.execute("select * from students_info")
# 将游标移动到第一行
row = cursor.fetchone()
# 当查询的结果集没有数据时,向下移动游标会返回空,如果不是空,说明有数据
if row !=None:
print(row)
一行一行的手动去移动太太麻烦,可以使用循环
# 将游标移动到第一行
row = cursor.fetchone()
# 如果返回的结果集第一行有数据,进入循环
while row != None:
# 打印第一行结果
print(row)
# 将游标指针向下再移动一行
row = cursor.fetchone()
上面的例子主要讲解了游标的一些概念,通常只有在确定返回的结果只有一条数据(即一行)时,才会使用fetchone()方法,比如按id查询时,因为id是唯一的,查询的结果只可能有一条数据或者为空,不可能有多条,这时使用fetchone方法是非常好的。当返回的结果可能为多条数据时,通常使用fetchall()方法,该方法会返回一个结果列表,遍历这个列表就可得到多条结果。如第一个例子中的用法:
result = cursor.fetchall()
#遍历所有结果,并打印
for row in result:
print(row)
之前的概念中也讲到,实际上执行完查询语句之后,所有的查询结果已经保存到cursor对象中,可以直接遍历cursor对象,与上面的调用fetchall()方法类似,区别就是调用fetchall()方法借助了列表,可以调用一些列表的函数对查询结果进行操作
#调用游标对象的execute()方法执行查询语句
cursor.execute("select * from students_info")
#直接遍历cursor对象,并打印
for row in cursor:
print(row)
SQLite防注入
对于某些特殊符号的数据,直接使用上述方法拼接字符串,可能会造成意想不到的错误,因此,应当使用另一种安全的,可防Sql注入攻击的方式插入数据。
cursor.execute("insert into students_info values (?,?,?)",
('Tom',18,'北京东路'))
这里的?相当于占位符,execute方法的第二个参数是一个元组,元组中的元素会替换掉占位符。注意,这里和字符串拼接是不同的,会进行sql的预编译,可防止SQL注入
数据库可视化
当我们创建生成了数据库之后,使用代码或命令行来查看数据库的内容是不方便的,这时候就需要一个界面软件来打开数据库查看,不同的数据库,有不同的可视化软件,即使同一款数据库,也会有多种可视化工具,对于Sqlite3而言,推荐使用SQLiteStudio软件查看 官网链接
归纳总结
需要注意,sqlite3模块的connect()函数用于连接数据库,其中传入的参数为数据库的路径,如果数据库不存在,则创建数据库,那么该路径就是数据库的保存路径;如果已经存在数据库,则打开数据库,该路径为当前数据的真实路径,路径填写错误,会造成程序崩溃!
Cursor游标对象的几个常用方法:
execute()执行sql语句,通常执行查询语句fetchone()将游标指针向下移动一行,并返回当前行的数据fetchall()从结果中取出所有结果,返回所有结果的列表close()关闭游标
查询返回的一行数据是一个元组,如上面代码中,print(row),其中row是一个元组,通过row[0]、row[1]等访问每一列数据,索引0对应上面代码中的id,索引1对应name,2对应age,以此类推
欢迎关注我的公众号:编程之路从0到1
