spring data solr 基础
目录
solr介绍
中文分析器
IK Analyzer(solr后台引入分析器,不是java项目)
扩展词典
停用字典里
域的配置
自定义域(自己的项目)
复制域
动态域
spring data solr
@Field注解
创建测试类
添加数据
删除数据
查询数据
分页查询(表达式查询)
条件查询
数据库的数据的导入solr
动态域的导入
搜索案例
高亮显示搜索内容
前台的处理(angularJS问题)
前言
ElasticSearch基础 https://blog.csdn.net/yzj17025693/article/details/89636313
ElasticSearch和solr都是搜索引擎框架
其中spring data solr又是对solr的封装
lucene基础 https://blog.csdn.net/yzj17025693/article/details/89607341#field(域)的分类
spring data solr 进阶 https://blog.csdn.net/yzj17025693/article/details/90453043
solr介绍

在windows下安装solr


solr管理后台

选择 核心 collection1
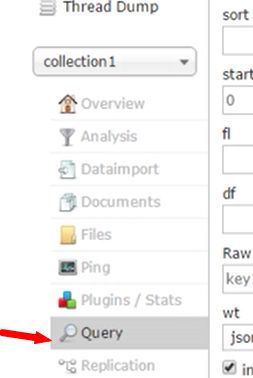
点击execute
q是查询的语句,*.*代表查询所有,右边是查询的结果,冒号: 前面的*代表域,冒号后面的*代表表达式
关于表达式可以百度查询

中文分析器
如果学过elesticsearch的知道如果使用中文搜索,就必须要中文分析器(分词器)
默认的分析器会对中文进行逐字拆分,很名称不是我们想要的,因为 程序员 和 程序 肯定都是不可分的词语

IK Analyzer(solr后台引入分析器,不是java项目)

1 是停用词词典
2 是扩展词典
3 配置文件

扩展词典
主要是写一些自定义的词,因为有些词是网络用语和指定名称,并不是常用的词,所以分析器识别不出来
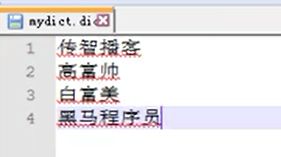
停用字典里
主要是以语气词为主,因为语气词对搜索没有意义,还有一些国家禁用词汇也可以在里面添加

配置文件里主要是进行词典的配置
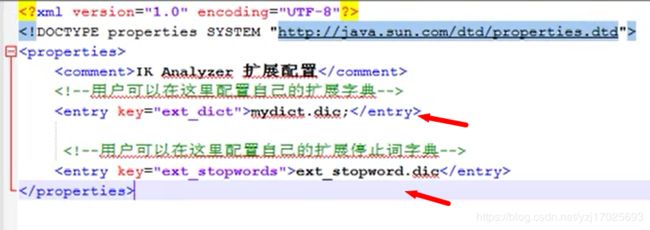
solr后台引入分析器
![]()

指定刚刚我们引入的分析器,name是text_ik进行分词
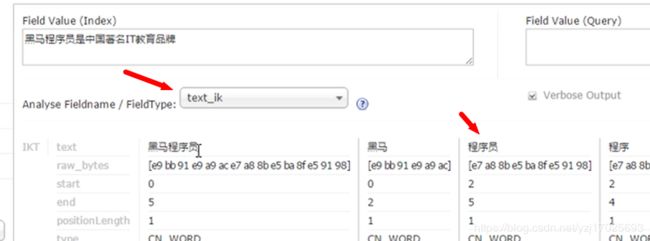
域的配置

在sechmax.xml已经有很多域了,这是solr框架自带的,相当于数据库的字段
lucene基础 https://blog.csdn.net/yzj17025693/article/details/89607341 里有这些属性的说明

自定义域(自己的项目)
type必须是sechma.xml里
商品的名称和商家的名称都需要使用分词器
而图片地址,不需要索引,因为我们不会搜索图片地址,只需要储存,因为搜索出来的商品需要显示图片
而平台,需要索引和储存,我们可能会根据商家查询,并且获取商家的信息,所以就需要存储
而存储是否,如果存储,那么可以通过document.get方法取出来,但是如果不存在,那么就不能通过get方法取出
但是可以通过QueryTerm查询出来,并不影响查询

复制域
普通的域是不关联的,所以我们多条件查询,也就是同时查询名称和平台,这时候就需要一个一个域找,需要写很多判断
这时候就很麻烦了,使用了复制域,可以把我们写的域给整合成一个域,做查询的时候,只需要查询这个域即可
这个域stored是不存储的,只做索引,因为只查询
multivalued代表多值,做复制域的时候需要配这个,也就是一个域里可以有多个数值

动态域
我们存一个域,而这个域名是不固定的,因为如果是手机,域名是机身内存
如果是平板电视,域名是电视屏幕尺寸


在sechma.xml里配置dynamicField

spring data solr
这里我们直接讲解spring data solr 而不讲解solrj
maven依赖

添加applicationContext.-solr.xml ,使用solr模版

@Field注解
之前我们在sechma.xml里设置了域,这里我们使用注解方式对应solr的域

创建测试类
添加数据
saveBean可以保存实体类,记得还需要commit
修改和删除的方法都是saveBean,这时候如果id变了,就会增加,id没变就是修改

这时候后台就会显示数据

删除数据

查询数据

分页查询(表达式查询)
如果不设置分页条件,那么就是查询全部, *:* 如果冒号前面指定了一个了域,那么只查询那一个域的数据


条件查询
只需要在Query里添加Criteria即可

数据库的数据的导入solr
导入配置文件


导入代码
其实不需要遍历出来,直接保持即可

直接保存list,而list里的实体类需要加上@Field注解

动态域的导入
把这样的数据导入到solr里

所以域名是不确定的

先用fastJson把源字段spec转换成json,然后复制到specMap中
我们在这个字段上用了Dynamic 那么自动会获取json的key用来填充星号

搜索案例
接口的编写
如果只传一个关键词,比如说 苹果 ,那么这个接口没问题
但是后面还有什么分类,规格,假如我们搜索了苹果后,下面的选项有水果和手机
这时候我们点击手机,就应该要继续查询,所以这个接口应该修改

可以把接受的值和返回值都改成Map,这个比较通用,需要的时候从map里取值即可

实现类
第1
Criteria里是域名称
is 是匹配查询,为什么不用包含,因为Criteria里已经进行了分词,所以里面的字符串是一段一段的(之前就已经把数据库的数据导入进来了)
使用is后,会使用分词的算法进行匹配
第2 把集合的数据封装到rows里,方便前端直接回显

控制层直接返回数据给前台即可

前台的处理
controller层

绑定数据

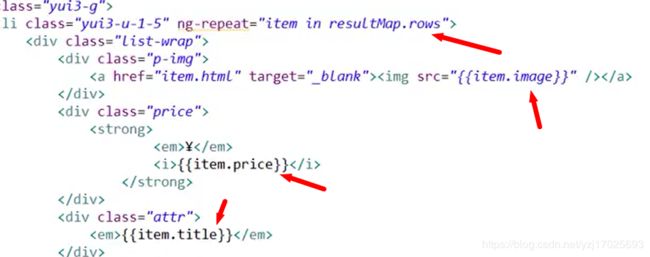
高亮显示搜索内容
simpleHighlightQuery有点东西,传入Criteria的时候,会把我们的关键词存起来,当我们查询的时候,会给它加上后缀
返回的内容加上标签即可,这个在elesticsearch里也讲解了

这个item_title在数据库里是 商品名,平拍,规格之类的组合,存到solr里也是类似的
addField只是指定这个域的内容需要高亮,并不是给整个title加上前缀和后缀

下面其实只是获取域里的值,然后设置到title里,高亮在上面就已经搞好了
第1 getHighlights 获取的是高亮域的个数,我们上面只指定了一个,就是item_title
第2 这个注解掉的循环,是因为可能有多域,而getSnipplet(获取片段),是因为可能有多值,所以还是返回了一个集合
但这不是重点,重点是让搜索的内容高亮显示
第3 getHighlights.get(0) 是因为我们现在只想高亮标题,getSnipplet.get(0)是因为我们目前一个域一个值
,因为我们的标题在一起就组合在一起,生成一串字符串,所以不组合,那么这个就可能要循环了
然后setTitle里面获取的是 带有高亮字段的标题
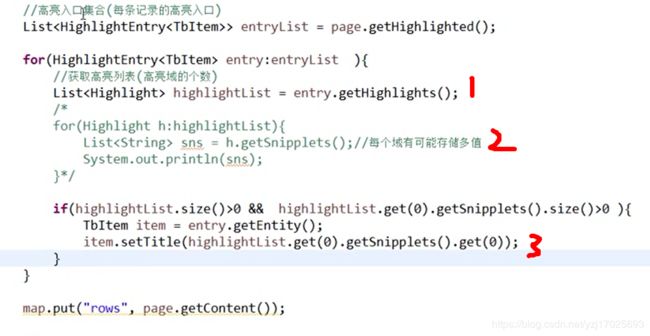
前台的处理(angularJS问题)
如果前台是用的angularJS显示,也就是{{item.title}},那么可能不会显示内容
因为可能会有html攻击,防止有人把一些内容内嵌到html里,请求给后台就出问题了

