Linux--shell中字符串的截取
1.在linux中字符串的截取我们可以用一个命令叫做cut,cut主要截取方法有三种
1)字节(bytes),用选项-b ,使用方法cut -b/c/f
2)字符(characters),用选项-c
3)域(fields),用选项-f
2.以字节定位
1)当我们想获取某一字节时
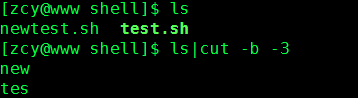
-b后面可以设定要提取哪一个字节,其实-b和3之间没有空格也是可以的,但推荐有空格:)
2)如果“字节”定位中,我想提取第3,第4、第5和第7个字节,怎么破?

-b支持形如3-5的写法,而且多个定位之间用逗号隔开就ok了。但有一点要注意,cut命令如果使用了-b选项,那么执行此命令时,cut会先把-b后面所有的定位进行从小到大排序,然后再提取。可不能颠倒定位的顺序哦。
3)其他还有什么情况呢?
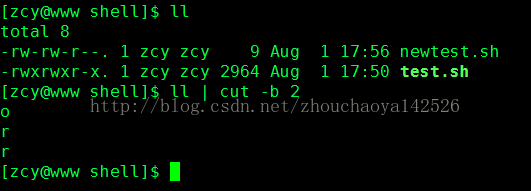
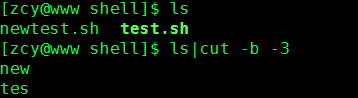
-3表示从第一个字节到第三个字节,而3-表示从第三个字节到行尾。如果你细心,你可以看到这两种情况下,都包括了第三个字节“c”。
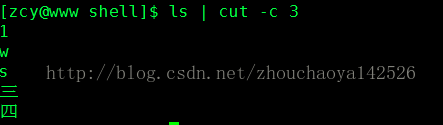
如果我执行ls|cut -b -3,3-,你觉得会如何呢?答案是输出整行。

4)接下来再看个例子

当我们以-b形式输出汉字形式的文件时,显示乱码了这是怎么回事?而-b只会傻傻的以字节(8位二进制位)来计算,输出就是乱码。
当遇到多字节字符时,可以使用-n选项,-n用于告诉cut不要将多字节字符拆开。例子如下:
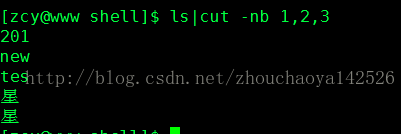
4. 域是怎么回事呢?
为什么会有“域”的提取呢,因为刚才提到的-b和-c只能在固定格式的文档中提取信息,而对于非固定格式的信息则束手无策。这时候“域”就派上用场了。
(下面的讲解内容是在假设你对/etc/passwd文件的内容和组织形式比较了解的情况下进行的。)
如果你观察过/etc/passwd文件,你会发现,它并不像who的输出信息那样具有固定格式,而是比较零散的排放。但是,冒号在这个文件的每一行中都起到了非常重要的作用,冒号用来隔开每一个项。
我们很幸运,cut命令提供了这样的提取方式,具体的说就是设置“间隔符”,再设置“提取第几个域”,就OK了!
以/etc/passwd的前五行内容为例:

用-d来设置间隔符为冒号,然后用-f来设置我要取的是第一个域,再按回车,所有的用户名就都列出来了。
在设定-f时,也可以使用例如3-5或者4-类似的格式:

5.如果遇到空格和制表符时,怎么分辨??
有时候制表符确实很难辨认,有一个方法可以看出一段空格到底是由若干个空格组成的还是由一个制表符组成的。

看到了吧,如果是制表符(TAB),那么会显示为\t符号,如果是空格,就会原样显示。
通过此方法即可以判断制表符和空格了。
5.我想将ps和cut命令配合使用时,怎么总是在最后两行出现重复现象?
这个问题的具体描述是如下这样的。
当cut和ps配合时:
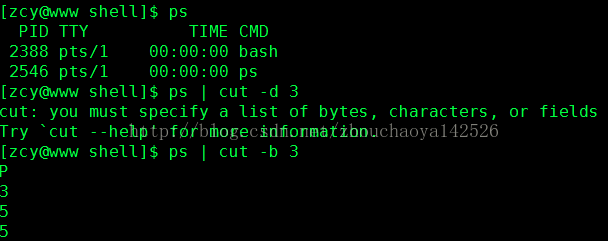
我们可以看到有两个5,为什么呢?
其实这个问题是这样的,ps|cut会自身创建一个进程,所以当ps时也会提取出这个进程,然后通过管道输出到cut,所以cut截取后,就多出了一行,之所以会重复上一行内容,是由于我们恰巧取到了和上一行内容相同的字符而已。
你测试下执行ps和ps|cat就知道原因了!
7.cut有哪些缺陷和不足?
很明显就是在处理多空格时。
如果文件里面的某些域是由若干个空格来间隔的,那么用cut就有点麻烦了,因为cut只擅长处理“以一个字符间隔”的文本内容
在shell中遇到字符串问题,首先考虑的是grep ,sed ,awk , cut
串截取中用简单方法就能做到的事情 ${}
1)shell中的单引号比双引号的区别:单引号关闭所有有特殊作用的字符,而双引号只要求shell忽略大多数,具体的说,就是①美元符号②反引号③反斜杠,这3种特殊字符不被忽略
(2)求字符串长度 —– (1)expr {#x}
(3)求字符串子串 —– pos位置,len可省略
(4)字符串替换 —– {x//a/b}用b替换所有的a
(5)字符串首尾截取—– {x##*/}去掉所有/左边的字符,也可用其它匹配代替*/{x#/}只去掉第一次出现/左边所有的字符。顺序为从左到右.{x%%/*}去掉所有/右边的字符,{x%/}去掉第一次出现/右边的字符,顺序为从右到左.
6)Shell数组定义 a=(1 2 3 4),不能有空格,比如a =(1 2 3 4)和a=(1 2 3 4)都是不允许的。
(7)数组长度: {#a[@]}
或者{#a[*]} ;全部数组
{a[@]}或
{a[*]}返回1 2 3 4
(8)数组元素的长度 {#a[i]},i为下标,和其它语言一样,从0开始,
数组元素{a[i]}
(9)Shell 变量,在Shell中有三种变量:系统变量,环境变量,用户变量
系统变量:
$# 传递到脚本的参数个数;
$$脚本运行的当前进程id;
$?最后命令的退出状态,0表成功;
$!上一个命令的PID ;
$@ 以”参数1” “参数2” … 形式保存所有参数 ;
0表示脚本名称
用户变量:用set命令查看
环境变量:用setenv查看