深入理解 Hive ACID 事务表
Apache Hive 0.13 版本引入了事务特性,能够在 Hive 表上实现 ACID 语义,包括 INSERT/UPDATE/DELETE/MERGE 语句、增量数据抽取等。Hive 3.0 又对该特性进行了优化,包括改进了底层的文件组织方式,减少了对表结构的限制,以及支持条件下推和向量化查询。Hive 事务表的介绍和使用方法可以参考 Hive Wiki 和 各类教程,本文将重点讲述 Hive 事务表是如何在 HDFS 上存储的,及其读写过程是怎样的。
文件结构
插入数据
CREATE TABLE employee (id int, name string, salary int)
STORED AS ORC TBLPROPERTIES ('transactional' = 'true');
INSERT INTO employee VALUES
(1, 'Jerry', 5000),
(2, 'Tom', 8000),
(3, 'Kate', 6000);
INSERT 语句会在一个事务中运行。它会创建名为 delta 的目录,存放事务的信息和表的数据。
/user/hive/warehouse/employee/delta_0000001_0000001_0000
/user/hive/warehouse/employee/delta_0000001_0000001_0000/_orc_acid_version
/user/hive/warehouse/employee/delta_0000001_0000001_0000/bucket_00000
目录名称的格式为 delta_minWID_maxWID_stmtID,即 delta 前缀、写事务的 ID 范围、以及语句 ID。具体来说:
- 所有 INSERT 语句都会创建
delta目录。UPDATE 语句也会创建delta目录,但会先创建一个delete目录,即先删除、后插入。delete目录的前缀是 delete_delta; - Hive 会为所有的事务生成一个全局唯一的 ID,包括读操作和写操作。针对写事务(INSERT、DELETE 等),Hive 还会创建一个写事务 ID(Write ID),该 ID 在表范围内唯一。写事务 ID 会编码到
delta和delete目录的名称中; - 语句 ID(Statement ID)则是当一个事务中有多条写入语句时使用的,用作唯一标识。
再看文件内容,_orc_acid_version 的内容是 2,即当前 ACID 版本号是 2。它和版本 1 的主要区别是 UPDATE 语句采用了 split-update 特性,即上文提到的先删除、后插入。这个特性能够使 ACID 表支持条件下推等功能,具体可以查看 HIVE-14035。bucket_00000 文件则是写入的数据内容。由于这张表没有分区和分桶,所以只有这一个文件。事务表都以 ORC 格式存储的,我们可以使用 orc-tools 来查看文件的内容:
$ orc-tools data bucket_00000
{"operation":0,"originalTransaction":1,"bucket":536870912,"rowId":0,"currentTransaction":1,"row":{"id":1,"name":"Jerry","salary":5000}}
{"operation":0,"originalTransaction":1,"bucket":536870912,"rowId":1,"currentTransaction":1,"row":{"id":2,"name":"Tom","salary":8000}}
{"operation":0,"originalTransaction":1,"bucket":536870912,"rowId":2,"currentTransaction":1,"row":{"id":3,"name":"Kate","salary":6000}}
输出内容被格式化为了一行行的 JSON 字符串,我们可以看到具体数据是在 row 这个键中的,其它键则是 Hive 用来实现事务特性所使用的,具体含义为:
operation0 表示插入,1 表示更新,2 表示删除。由于使用了 split-update,UPDATE 是不会出现的;originalTransaction是该条记录的原始写事务 ID。对于 INSERT 操作,该值和currentTransaction是一致的。对于 DELETE,则是该条记录第一次插入时的写事务 ID;bucket是一个 32 位整型,由BucketCodec编码,各个二进制位的含义为:- 1-3 位:编码版本,当前是
001; - 4 位:保留;
- 5-16 位:分桶 ID,由 0 开始。分桶 ID 是由 CLUSTERED BY 子句所指定的字段、以及分桶的数量决定的。该值和
bucket_N中的 N 一致; - 17-20 位:保留;
- 21-32 位:语句 ID;
- 举例来说,整型
536936448的二进制格式为00100000000000010000000000000000,即它是按版本 1 的格式编码的,分桶 ID 为 1;
- 1-3 位:编码版本,当前是
rowId是一个自增的唯一 ID,在写事务和分桶的组合中唯一;currentTransaction当前的写事务 ID;row具体数据。对于 DELETE 语句,则为null。
我们可以注意到,文件中的数据会按 (originalTransaction, bucket, rowId) 进行排序,这点对后面的读取操作非常关键。
这些信息还可以通过 row__id 这个虚拟列进行查看:
SELECT row__id, id, name, salary FROM employee;
输出结果为:
{"writeid":1,"bucketid":536870912,"rowid":0} 1 Jerry 5000
{"writeid":1,"bucketid":536870912,"rowid":1} 2 Tom 8000
{"writeid":1,"bucketid":536870912,"rowid":2} 3 Kate 6000
增量数据抽取 API V2
Hive 3.0 还改进了先前的 增量抽取 API,通过这个 API,用户或第三方工具(Flume 等)就可以利用 ACID 特性持续不断地向 Hive 表写入数据了。这一操作同样会生成 delta 目录,但更新和删除操作不再支持。
StreamingConnection connection = HiveStreamingConnection.newBuilder().connect();
connection.beginTransaction();
connection.write("11,val11,Asia,China".getBytes());
connection.write("12,val12,Asia,India".getBytes());
connection.commitTransaction();
connection.close();
更新数据
UPDATE employee SET salary = 7000 WHERE id = 2;
这条语句会先查询出所有符合条件的记录,获取它们的 row__id 信息,然后分别创建 delete 和 delta 目录:
/user/hive/warehouse/employee/delta_0000001_0000001_0000/bucket_00000
/user/hive/warehouse/employee/delete_delta_0000002_0000002_0000/bucket_00000
/user/hive/warehouse/employee/delta_0000002_0000002_0000/bucket_00000
delete_delta_0000002_0000002_0000/bucket_00000 包含了删除的记录:
{"operation":2,"originalTransaction":1,"bucket":536870912,"rowId":1,"currentTransaction":2,"row":null}
delta_0000002_0000002_0000/bucket_00000 包含更新后的数据:
{"operation":0,"originalTransaction":2,"bucket":536870912,"rowId":0,"currentTransaction":2,"row":{"id":2,"name":"Tom","salary":7000}}
DELETE 语句的工作方式类似,同样是先查询,后生成 delete 目录。
合并表
MERGE 语句和 MySQL 的 INSERT ON UPDATE 功能类似,它可以将来源表的数据合并到目标表中:
CREATE TABLE employee_update (id int, name string, salary int);
INSERT INTO employee_update VALUES
(2, 'Tom', 7000),
(4, 'Mary', 9000);
MERGE INTO employee AS a
USING employee_update AS b ON a.id = b.id
WHEN MATCHED THEN UPDATE SET salary = b.salary
WHEN NOT MATCHED THEN INSERT VALUES (b.id, b.name, b.salary);
这条语句会更新 Tom 的薪资字段,并插入一条 Mary 的新记录。多条 WHEN 子句会被视为不同的语句,有各自的语句 ID(Statement ID)。INSERT 子句会创建 delta_0000002_0000002_0000 文件,内容是 Mary 的数据;UPDATE 语句则会创建 delete_delta_0000002_0000002_0001 和 delta_0000002_0000002_0001 两个文件,删除并新增 Tom 的数据。
/user/hive/warehouse/employee/delta_0000001_0000001_0000
/user/hive/warehouse/employee/delta_0000002_0000002_0000
/user/hive/warehouse/employee/delete_delta_0000002_0000002_0001
/user/hive/warehouse/employee/delta_0000002_0000002_0001
压缩
随着写操作的积累,表中的 delta 和 delete 文件会越来越多。事务表的读取过程中需要合并所有文件,数量一多势必会影响效率。此外,小文件对 HDFS 这样的文件系统也是不够友好的。因此,Hive 引入了压缩(Compaction)的概念,分为 Minor 和 Major 两类。
Minor Compaction 会将所有的 delta 文件压缩为一个文件,delete 也压缩为一个。压缩后的结果文件名中会包含写事务 ID 范围,同时省略掉语句 ID。压缩过程是在 Hive Metastore 中运行的,会根据一定阈值自动触发。我们也可以使用如下语句人工触发:
ALTER TABLE employee COMPACT 'minor';
以上文中的 MERGE 语句的结果举例,在运行了一次 Minor Compaction 后,文件目录结构将变为:
/user/hive/warehouse/employee/delete_delta_0000001_0000002
/user/hive/warehouse/employee/delta_0000001_0000002
在 delta_0000001_0000002/bucket_00000 文件中,数据会被排序和合并起来,因此文件中将包含两行 Tom 的数据。Minor Compaction 不会删除任何数据。
Major Compaction 则会将所有文件合并为一个文件,以 base_N 的形式命名,其中 N 表示最新的写事务 ID。已删除的数据将在这个过程中被剔除。row__id 则按原样保留。
/user/hive/warehouse/employee/base_0000002
需要注意的是,在 Minor 或 Major Compaction 执行之后,原来的文件不会被立刻删除。这是因为删除的动作是在另一个名为 Cleaner 的线程中执行的。因此,表中可能同时存在不同事务 ID 的文件组合,这在读取过程中需要做特殊处理。
读取过程
我们可以看到 ACID 事务表中会包含三类文件,分别是 base、delta、以及 delete。文件中的每一行数据都会以 row__id 作为标识并排序。从 ACID 事务表中读取数据就是对这些文件进行合并,从而得到最新事务的结果。这一过程是在 OrcInputFormat 和 OrcRawRecordMerger 类中实现的,本质上是一个合并排序的算法。
以下列文件为例,产生这些文件的操作为:插入三条记录,进行一次 Major Compaction,然后更新两条记录。1-0-0-1 是对 originalTransaction - bucketId - rowId - currentTransaction 的缩写。
+----------+ +----------+ +----------+
| base_1 | | delete_2 | | delta_2 |
+----------+ +----------+ +----------+
| 1-0-0-1 | | 1-0-1-2 | | 2-0-0-2 |
| 1-0-1-1 | | 1-0-2-2 | | 2-0-1-2 |
| 1-0-2-1 | +----------+ +----------+
+----------+
合并过程为:
- 对所有数据行按照 (
originalTransaction,bucketId,rowId) 正序排列,(currentTransaction) 倒序排列,即:1-0-0-11-0-1-21-0-1-1- …
2-0-1-2
- 获取第一条记录;
- 如果当前记录的
row__id和上条数据一样,则跳过; - 如果当前记录的操作类型为 DELETE,也跳过;
- 通过以上两条规则,对于
1-0-1-2和1-0-1-1,这条记录会被跳过;
- 通过以上两条规则,对于
- 如果没有跳过,记录将被输出给下游;
- 重复以上过程。
合并过程是流式的,即 Hive 会将所有文件打开,预读第一条记录,并将 row__id 信息存入到 ReaderKey 类型中。该类型实现了 Comparable 接口,因此可以按照上述规则自定义排序:
public class RecordIdentifier implements WritableComparable<RecordIdentifier> {
private long writeId;
private int bucketId;
private long rowId;
protected int compareToInternal(RecordIdentifier other) {
if (other == null) { return -1; }
if (writeId != other.writeId) { return writeId < other.writeId ? -1 : 1; }
if (bucketId != other.bucketId) { return bucketId < other.bucketId ? - 1 : 1; }
if (rowId != other.rowId) { return rowId < other.rowId ? -1 : 1; }
return 0;
}
}
public class ReaderKey extends RecordIdentifier {
private long currentWriteId;
private boolean isDeleteEvent = false;
public int compareTo(RecordIdentifier other) {
int sup = compareToInternal(other);
if (sup == 0) {
if (other.getClass() == ReaderKey.class) {
ReaderKey oth = (ReaderKey) other;
if (currentWriteId != oth.currentWriteId) { return currentWriteId < oth.currentWriteId ? +1 : -1; }
if (isDeleteEvent != oth.isDeleteEvent) { return isDeleteEvent ? -1 : +1; }
} else {
return -1;
}
}
return sup;
}
}
然后,ReaderKey 会和文件句柄一起存入到 TreeMap 结构中。根据该结构的特性,我们每次获取第一个元素时就能得到排序后的结果,并读取数据了。
public class OrcRawRecordMerger {
private TreeMap<ReaderKey, ReaderPair> readers = new TreeMap<>();
public boolean next(RecordIdentifier recordIdentifier, OrcStruct prev) {
Map.Entry<ReaderKey, ReaderPair> entry = readers.pollFirstEntry();
}
}
选择文件
上文中提到,事务表目录中会同时存在多个事务的快照文件,因此 Hive 首先要选择出反映了最新事务结果的文件集合,然后再进行合并。举例来说,下列文件是一系列操作后的结果:两次插入,一次 Minor Compaction,一次 Major Compaction,一次删除。
delta_0000001_0000001_0000
delta_0000002_0000002_0000
delta_0000001_0000002
base_0000002
delete_delta_0000003_0000003_0000
过滤过程为:
- 从 Hive Metastore 中获取所有成功提交的写事务 ID 列表;
- 从文件名中解析出文件类型、写事务 ID 范围、以及语句 ID;
- 选取写事务 ID 最大且合法的那个
base目录,如果存在的话; - 对
delta和delete文件进行排序:minWID较小的优先;- 如果
minWID相等,则maxWID较大的优先; - 如果都相等,则按
stmtID排序;没有stmtID的会排在前面;
- 将
base文件中的写事务 ID 作为当前 ID,循环过滤所有delta文件:- 如果
maxWID大于当前 ID,则保留这个文件,并以此更新当前 ID; - 如果 ID 范围相同,也会保留这个文件;
- 重复上述步骤。
- 如果
过滤过程中还会处理一些特别的情况,如没有 base 文件,有多条语句,包含原始文件(即不含 row__id 信息的文件,一般是通过 LOAD DATA 导入的),以及 ACID 版本 1 格式的文件等。具体可以参考 AcidUtils#getAcidState 方法。
并行执行
在 Map-Reduce 模式下运行 Hive 时,多个 Mapper 是并行执行的,这就需要将 delta 文件按一定的规则组织好。简单来说,base 和 delta 文件会被分配到不同的分片(Split)中,但所有分片都需要能够读取所有的 delete 文件,从而根据它们忽略掉已删除的记录。
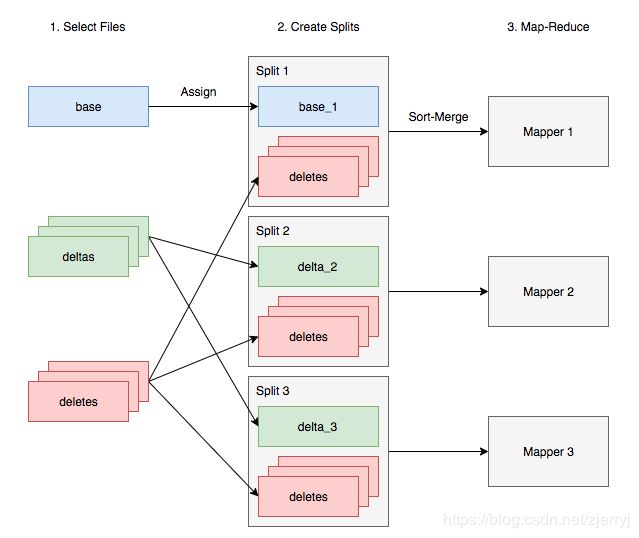
向量化查询
当 向量化查询 特性开启时,Hive 会尝试将所有的 delete 文件读入内存,并维护一个特定的数据结构,能够快速地对数据进行过滤。如果内存放不下,则会像上文提到的过程一样,逐步读取 delete 文件,使用合并排序的算法进行过滤。
public class VectorizedOrcAcidRowBatchReader {
private final DeleteEventRegistry deleteEventRegistry;
protected static interface DeleteEventRegistry {
public void findDeletedRecords(ColumnVector[] cols, int size, BitSet selectedBitSet);
}
static class ColumnizedDeleteEventRegistry implements DeleteEventRegistry {}
static class SortMergedDeleteEventRegistry implements DeleteEventRegistry {}
public boolean next(NullWritable key, VectorizedRowBatch value) {
BitSet selectedBitSet = new BitSet(vectorizedRowBatchBase.size);
this.deleteEventRegistry.findDeletedRecords(innerRecordIdColumnVector,
vectorizedRowBatchBase.size, selectedBitSet);
for (int setBitIndex = selectedBitSet.nextSetBit(0), selectedItr = 0;
setBitIndex >= 0;
setBitIndex = selectedBitSet.nextSetBit(setBitIndex+1), ++selectedItr) {
value.selected[selectedItr] = setBitIndex;
}
}
}
事务管理
为了实现 ACID 事务机制,Hive 还引入了新的事务管理器 DbTxnManager,它能够在查询计划中分辨出 ACID 事务表,联系 Hive Metastore 打开新的事务,完成后提交事务。它也同时实现了过去的读写锁机制,用来支持非事务表的情形。
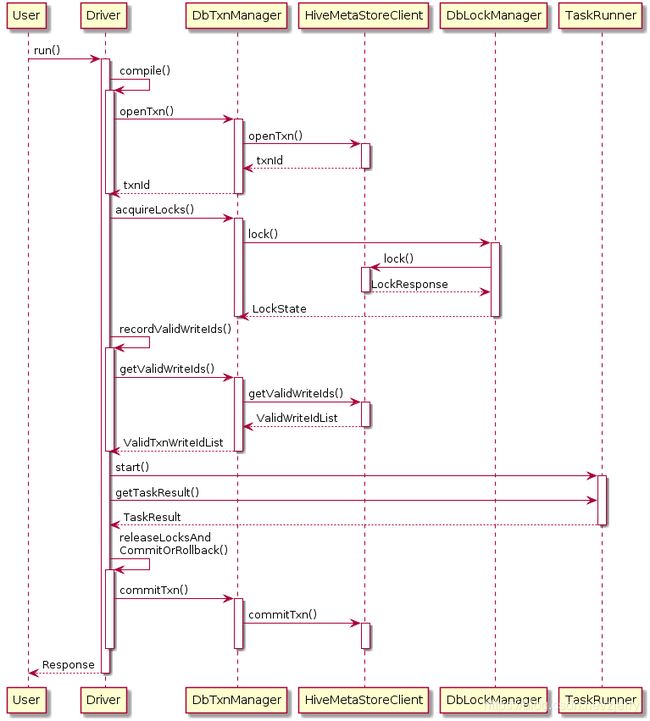
Hive Metastore 负责分配新的事务 ID。这一过程是在一个数据库事务中完成的,从而避免多个 Metastore 实例冲突的情况。
abstract class TxnHandler {
private List<Long> openTxns(Connection dbConn, Statement stmt, OpenTxnRequest rqst) {
String s = sqlGenerator.addForUpdateClause("select ntxn_next from NEXT_TXN_ID");
s = "update NEXT_TXN_ID set ntxn_next = " + (first + numTxns);
for (long i = first; i < first + numTxns; i++) {
txnIds.add(i);
rows.add(i + "," + quoteChar(TXN_OPEN) + "," + now + "," + now + ","
+ quoteString(rqst.getUser()) + "," + quoteString(rqst.getHostname()) + "," + txnType.getValue());
}
List<String> queries = sqlGenerator.createInsertValuesStmt(
"TXNS (txn_id, txn_state, txn_started, txn_last_heartbeat, txn_user, txn_host, txn_type)", rows);
}
}
参考资料
- Hive Transactions
- Transactional Operations in Apache Hive
- ORCFile ACID Support