社区投稿 | DBLE和Mycat跨分片查询结果不一致案例分析
本文目录
一、背景
二、DBLE 项目介绍
三、环境准备
1.测试架构
2.测试软件版本
3.表结构
4.分片规则配置
schema配置
rule配置
四、比对开始
1.准备测试数据
2.执行跨节点join查询
3.执行计划
DBLE
Mycat
五、总结
1.背景
某一零售业后端使用了分布式中间件+ MySQL 数据库作为后端存储。但是因为历史问题存在两种分布式中间件,分别是 Mycat 和 DBLE ,共用一组后端 MySQL实例。分片规则以及后端数据完全一致。最近碰到了一个比较有意思的场景,财务结算单来往明细和业务来往单据的关联查询。一条跨节点 join 查询在 DBLE、Mycat 的查询得到的结果不一致。究竟谁对谁错?
2.DBLE 项目介绍
DBLE 是企业级开源分布式中间件,江湖人送外号 “MyCat Plus”;以其简单稳定,持续维护,良好的社区环境和广大的群众基础得到了社区的大力支持;
DBLE官方网站:
https://opensource.actionsky.com
可以详细了解DBLE的背景和应用场景,本文不涉及到的细节都可在官方文档获得更细节都信息;对于刚了解到同学,可以以本文为快速入门基础
DBLE 官方项目:
https://github.com/actiontech/dble
如对源码有兴趣或者需要定制的功能的可以通过源码编译安装
DBLE 下载地址:
https://github.com/actiontech/dble/releases
DBLE 官方社区交流群:669663113
3.环境准备
在虚拟机搭建类似架构,模拟场景,比较 Mycat-DBLE 在跨节点 join 上的异同点。
3.1测试架构
测试环境架构比较简单,DBLE 与 Mycat 共用数据库。

3.2测试软件版本
| 软件名称 |
软件版本 |
端口 |
管理端口 |
| dble |
dble-2.18.10.1-cb392c3-20181106093917 |
3309 |
3310 |
| mycat |
mycat-1.6-RELEASE-20161028204710 |
8066 |
9066 |
| MySQL |
5.7.21-log |
3306 |
无 |
3.3表结构
▽ 结算单来往明细表
CREATE TABLE `t_bl_detail` (
`unit_num` int(11) DEFAULT NULL,
`tenantid` int(11) DEFAULT NULL,
`detail_num` int(11) DEFAULT NULL,
`balance_date` datetime DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
▽ 业务来往单据表
CREATE TABLE `t_bl_super_detail` (
`unit_num` int(11) DEFAULT NULL,
`sup_id` int(11) DEFAULT NULL,
`tenantid` int(11) DEFAULT NULL,
`bl_unit_num` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
3.4分片规则配置
配置表t_bl_detail、t_bl_super_detail,使用取模算法,数据分布在db1-db4四个database中。
-
3.41schema配置
▽ DBLE - schema 配置
select user()
select user()
▽ Mycat - schema 配置
select user()
select user()
-
3.42rule 配置
▽ DBLE - rule 配置
unit_num
mod4DB
4
1
▽ Mycat - rule 配置
id
mod4DB
4
4.比对开始
4.1准备测试数据
登录任意一台中间件写入测试数据:
insert into t_bl_detail values(1,3,123443,'2019-01-01 00:00:00');
insert into t_bl_detail values(2,3,3423524,'2019-01-01 00:00:00');
insert into t_bl_detail values(3,3,245245,'2019-01-01 00:00:00');
insert into t_bl_detail values(4,4,356356,'2019-01-01 00:00:00');
insert into t_bl_super_detail values(1,10342,3,2);
insert into t_bl_super_detail values(2,12355,3,2);
insert into t_bl_super_detail values(3,62542,3,3);
insert into t_bl_super_detail values(4,74235,4,1);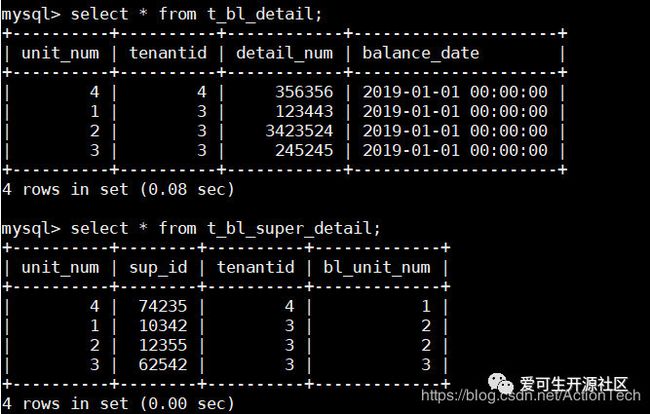
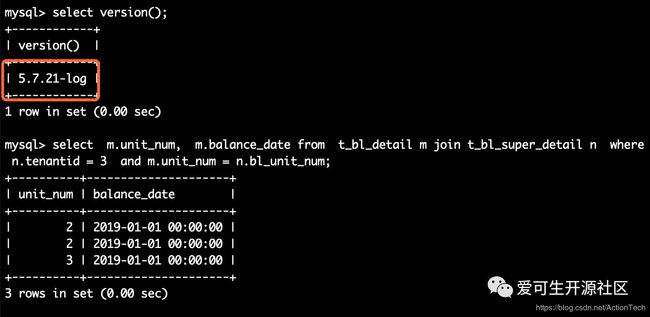
4.2执行跨节点 join 查询
select
m.unit_num,
m.balance_date
from
t_bl_detail m
join t_bl_super_detail n
where
n.tenantid = 3
and m.unit_num = n.bl_unit_num;
在通过中间件之前,现在 MySQL 中执行一遍看下结果,作为预期结果供后续案例使用。
分别通过 DBLE、Mycat 执行跨节点 join 语句。
▽ DBLE 执行跨节点 join 语句

▽ Mycat 执行跨节点 join 语句

可看到相同的查询语句,DBLE 执行结果符合预期,Mycat 执行结果缺失。数据差异在于 DBLE 查询结果相较于 Mycat 多了跨节点的结果。虽然 Mycat 执行跨节点 join 不报错,但是查询结果却和预期不一致。
4.3执行计划
只从结果上判断并没有办法知道是什么原因导致了 Mycat 结果缺失,查看查询计划,比较两者差异。
-
4.31DBLE
通过 DBLE 的执行计划可看出,DBLE 内部分别对结算明细表、业务单据表做了各自的数据查询,将查询结果在中间层做了merge。最后获得跨节点 join 的结果。

-
4.32Mycat
Mycat 对于跨节点 join 的处理则相对暴力,直接将查询语句下发到各个节点,最后将结果进行汇总,如果表连接涉及到跨节点。则跨节点的数据无法进行 join。

5.总结
Mycat 是一款非常优秀的分布式中间件,但是在某些细节方面处理的不尽人意。在跨节点关联查询场景下,Mycat 采取的策略是直接将语句透传到各个节点上,将获取到的结果整合后返回,得到的结果集和预期结果有出入,缺失了跨节点关联的数据。
DBLE 处理跨节点的关联查询是先获取到关联需要的数据,提取到中间件进行融合,得到关联查询的结果并返回。得到的结果集符合预期,与 MySQL 执行结果一致。可见 DBLE 在跨节点关联查询方面做了优化,能够提供准确的查询结果。
