Azkaban的使用
Azkaban
1.Azkaban是什么
- zkaban是一套简单的任务调度服务,整体包括三部分webserver、dbserver、executorserver。
- Azkaban是linkin的开源项目,开发语言为Java。
- Azkaban是由Linkedin开源的一个批量工作流任务调度器。用于在一个工作流内以一个特定的顺序运行一组工作和流程。
- Azkaban定义了一种KV文件格式来建立任务之间的依赖关系,并提供一个易于使用的web用户界面维护和跟踪你的工作流。
2.Azkaban的典型的应用的场景
- 典型的应用一
实际当中经常有这些场景:每天有一个大任务,这个大任务可以分成A,B,C,D四个小任务,A,B任务之间没有依赖关系,C任务依赖A,B任务的结果,D任务依赖C任务的结果。一般的做法是,开两个终端同时执行A,B,两个都执行完了再执行C,最后再执行D。这样的话,整个的执行过程都需要人工参加,并且得盯着各任务的进度。但是我们的很多任务都是在深更半夜执行的,通过写脚本设置crontab执行。其实,整个过程类似于一个有向无环图(DAG)。每个子任务相当于大任务中的一个流,任务的起点可以从没有度的节点开始执行,任何没有通路的节点之间可以同时执行,比如上述的A,B。总结起来的话,我们需要的就是一个工作流的调度器,而azkaban就是能解决上述问题的一个调度器。
hadoop实际使用案例
例如,我们可能有这样一个需求,某个业务系统每天产生 20G 原始数据,我们每天都要对其进行处理,处理步骤如下所示:
1、 通过 Hadoop 先将原始数据同步到 HDFS 上;
2、 借助 MapReduce 计算框架对原始数据进行清洗转换,生成的数据以分区表的形式存储到多张 Hive 表中;
3、 需要对 Hive 中多个表的数据进行 JOIN 处理,得到一个明细数据 Hive 大表;
4、 将明细数据进行各种统计分析,得到结果报表信息;
5、 需要将统计分析得到的结果数据同步到业务系统中,供业务调用使用。
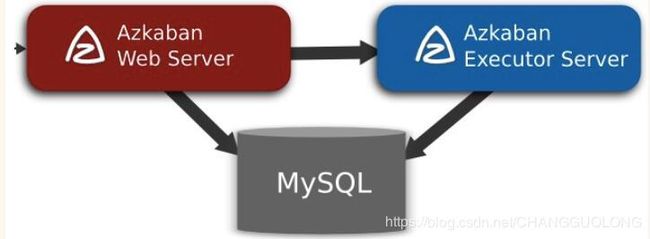
3.Azkaban的架构
Azkaban是一种类似于Oozie的工作流控制引擎,可以用来解决多个Hadoop(或Spark等)离线计算任务之间的依赖关系问题。也可以用其代替crontab来对周期性任务进行调度,并且更为直观,可靠,同时提供了美观的可视化管理界面。
Azkaban由三部分构成:
1、Relational Database(Mysql)
azkaban将大多数状态信息都存于MySQL中,Azkaban Web Server 和 Azkaban Executor Server也需要访问DB。
2、Azkaban Web Server
提供了Web UI,是azkaban的主要管理者,包括 project 的管理,认证,调度,对工作流执行过程的监控等。
3、Azkaban Executor Server
调度工作流和任务,纪录工作流活任务的日志,之所以将AzkabanWebServer和AzkabanExecutorServer分开,主要是因为在某个任务流失败后,可以更方便的将重新执行。而且也更有利于Azkaban系统的升级
4.Azkaban的使用
- 登录
Azkaban需要启动执行器和web端执行命令如下:
azkaban-web-start.sh
azkaban-executor-start.sh
启动完成后,在浏览器(建议使用谷歌浏览器)中输入 https://IP:8443,即可访问 azkaban 服务了。
在登录中输入刚才新的户用名及密码,点击 login。
注意这里的登录名和密码的配置是在/home/hadoop/apps/azkaban/azkaban-web-2.5.0/conf/azkaban-users.xml中进行配置的

登录之后就可以进行相关的操作了
5.实战案例
5.1单job运行
-
创建以个.job文件,在job文件中写如下指令
#single_job.job------------------//这里的名字和文件的名字相同
type=command-------------- //类型是运行指令
command=echo single_job running------------//指令的内容是打印single_job running -
将single_job文件压缩成.zip文件(注意single_job.job必须在压缩文件的根目录下)

-
上传到web端
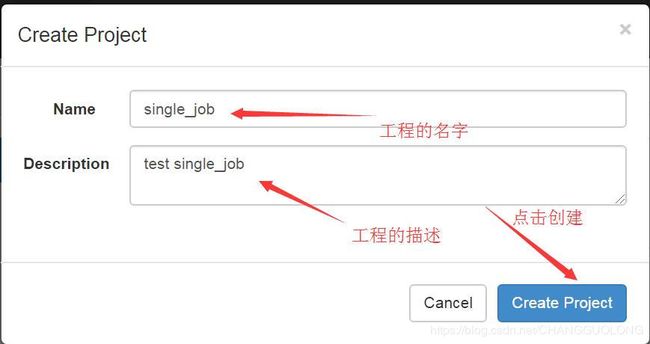
- 创建工程
-

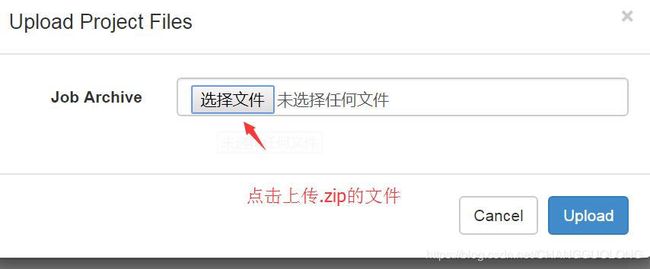
- 上传文件

- 上传文件
- 执行任务

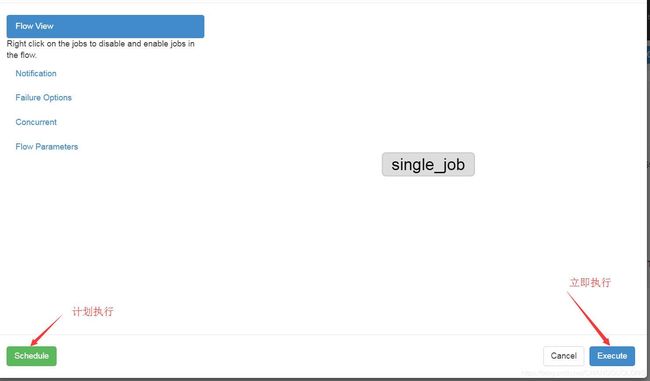
-执行立即执行

- 查看日志
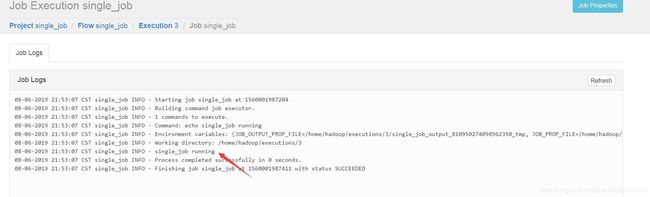
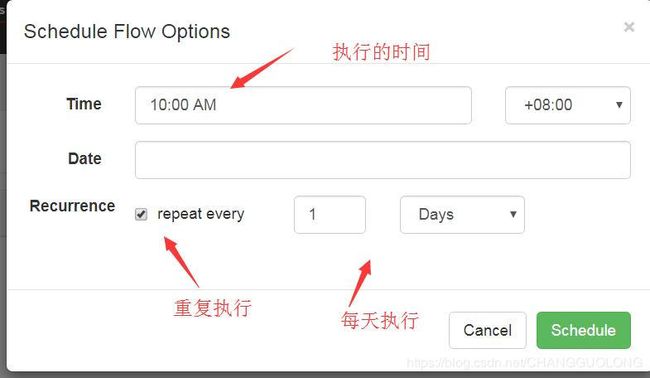
也可以执行计划执行


执行完成
5.2command多job工作流
现在有这样一个需求:job3需要等job1和job2执行完成之后再执行
- 创建3个job文件
#stepone.job
type=command
command=echo stepone runing
#stepone.job
type=command
command=echo steptwo runing
#stepone.job
type=command
dependencies=stepone,steptwo //设置依赖
command=echo stepthree runing
之后压缩
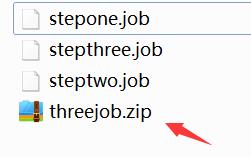
创建工程兵上传文件
之后进行性执行
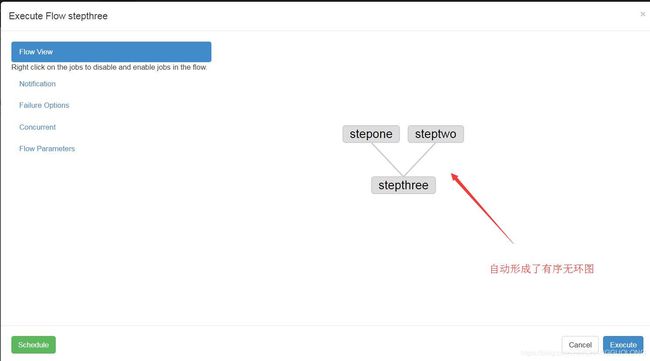

按照依赖的顺序进行了执行的操作
5.3操作hdfs
对hdfs的操作和上边的操作一致,主要就是写上一个脚本执行
比如在hdfs上创建一个目录
#hdfs.job
type=command
command=hadoop fs -mkdir -p /azkaban/testhdfs
5.4mapreduce 任务
编写一个mapreduce的wordcount的程序
public class WordCount {
static class MyMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
Text mk = new Text();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context)
throws IOException, InterruptedException {
String[] value_str = value.toString().split("\\.");
for (String str : value_str) {
mk.set(str);
context.write(mk, NullWritable.get());
}
}
}
static class MyReducer extends Reducer<Text, NullWritable, Text, IntWritable> {
IntWritable rv = new IntWritable();
@Override
protected void reduce(Text key, Iterable<NullWritable> values,
Reducer<Text, NullWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
int sum = 0;
for (NullWritable nullWritable : values) {
sum++;
}
rv.set(sum);
context.write(key, rv);
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
String inpath=args[0];
String outpath=args[1];
System.setProperty("HADOOP_USER_NAME", "hadoop");
// 加载配置文件
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://高可用的组号/");
//创建job
Job job = Job.getInstance(conf);
//设置主类
job.setJarByClass(WordCount.class);
//指定map和reducer
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
// 代表的最终输出
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置参数0是输入的路径
FileInputFormat.setInputPaths(job, new Path(inpath));
//设置参数1是输出的路径
Path out = new Path(outpath);
FileSystem fs = FileSystem.get(conf);
if (fs.exists(out)) {
fs.delete(out, true);
}
FileOutputFormat.setOutputPath(job, out);
job.waitForCompletion(true);
}
}
将工程打成jar包
创建一个job的文件.文件中运行jar包指令
#wordcount.job
type=command
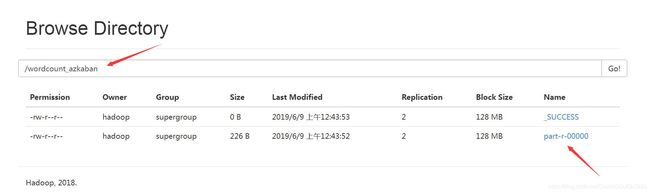
command=hadoop jar Azkaban_wordCount-0.0.1-SNAPSHOT.jar com.chang.wordCount.WordCount /share/wordcount /wordcount_azkaban
下边对这条指令进行解释
hadoop jar jar包名称 jar包中执行的类的全限定名 参数1 参数2
将jar包和.job文件压缩,
在web端创建工程兵上传文件,之后运行

5.5hive任务的执行
执行批量的hql语句完成指定的操作
- 先创建一个.sql文件,将所有的hql语句写到内部,注意这些语句应该先在本地运行成功
hive.sql
create database azkaban_test;
use azkaban_test;
create table wordcount(word string,count int)
row format delimited fields terminated by "\t";
load data inpath "/wordcount_azkaban" into table wordcount;
create table newtable as select * from wordcount;
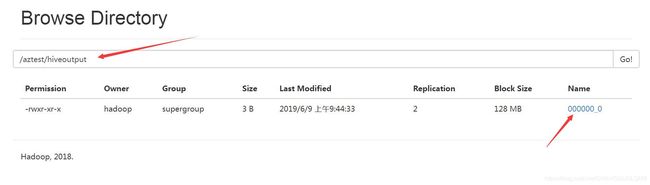
insert overwrite directory '/aztest/hiveoutput' select count(1) from newtable;
- 创建一个.job文件,运行hive.sql文件
#hive.job
type=command
command=hive -f 'hive.sql'
- 压缩
- 创建工程并上传 之后运行

检查hive仓库的数据
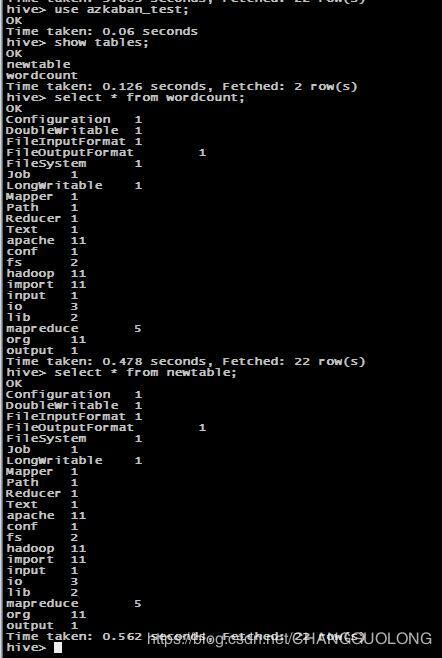
检查hdfs