Linux系统搭建Solr和Redis集群详细步骤
1 搭建Solr集群(SolrCloud)
1.1 Zookeeper介绍
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务、node管理等。
Zookeeper实现了高性能,高可靠性,和有序的访问。高性能保证了zookeeper能应用在大型的分布式系统上。高可靠性保证它不会由于单一节点的故障而造成任何问题。
你运行一个zookeeper也是可以的,但是在生产环境中,你最好部署3,5,7个节点。部署的越多,可靠性就越高,当然最好是部署奇数个,偶数个不是不可以的,但是zookeeper集群是以宕机个数过半才会让整个集群宕机的(选举机制),所以奇数个集群更佳。
1.2 介绍搭建环境
资料\solr资料
1.3 搭建zookeeper集群
1.3.1 软件上传
略
1.3.2 创建zookeeper-cluster目录
在/usr/local/src/下创建zookeeper-cluster目录
![]()
1.3.3 解压zookeeper到该目录下
![]()
1.3.4 修改zookeeper名称
修改解压后的目录名称zookeeper-3.4.6位zookeeper01

1.3.5 在zookeeper01下创建data、logs目录
在zookeeper01下创建
1、 data目录(存放配置的服务或者节点等)
2、 logs目录(存放日志)
![]()
1.3.6 修改conf目录下的文件名称
进入conf目录下,将zoo_sample.cfg文件修改为zoo.cfg文件。

1.3.7 修改zoo.cfg文件
1、 指定data目录
2、 指定logs目录
3、 指定zookeeper的节点编号

说明:2888端口用于zookeeper集群间数据同步传输,3888端口用于zookeeper的选举机制
# The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. # dataDir=/tmp/zookeeper # the port at which the clients will connect clientPort=2181 # the maximum number of client connections. # increase this if you need to handle more clients #maxClientCnxns=60 # # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. # # http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance # # The number of snapshots to retain in dataDir #autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature #autopurge.purgeInterval=1 dataDir=/usr/local/src/zookeeper/zookeeper01/data dataLogDir=/usr/local/src/zookeeper/zookeeper01/logs server.1=192.168.200.128:2888:3888 server.2=192.168.200.128:4888:5888 server.3=192.168.200.128:6888:7888 |
1.3.8 在data目录下创建myid文件
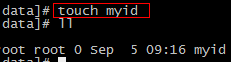
1.3.9 修改myid
指定该zookeeper是第几个节点
echo 1 > myid
查看文件中的值命令:
more myid
![]()
1.3.10 copy zookeeper02

修改:
1、 修改zoo.cfg文件

2、 修改myid文件

1.3.11 copy zookeeper03
![]()
修改:
1、 修改zoo.cfg文件

2、 修改myid文件

1.3.12 依次启动该三台zookeeper
注意:任意启动第一个zookeeper都会报错(不用理会)

1.4 本项目中的作用
管理dubbo服务以及solr集群节点。
2 solr集群
2.1 solr集群原理

2.2 SolrCloud概念以及结构
2.2.1 概念
SolrCloud(solr 云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时使用 SolrCloud。当一个系统的索引数据量少的时候是不需要使用SolrCloud的,当索引量很大,搜索请求并发很高,这时需要使用SolrCloud来满足这些需求。
2.2.2 结构
SolrCloud为了降低单机的处理压力,需要由多台服务器共同来完成索引和搜索任务。实现的思路是将索引数据进行Shard(分片)拆分,每个分片由多台的服务器共同完成,当一个索引或搜索请求过来时会分别从不同的Shard的服务器中操作索引。
SolrCloud需要Solr基于Zookeeper部署,Zookeeper是一个集群管理软件,由于SolrCloud需要由多台服务器组成,由zookeeper来进行协调管理。
2.3 solr集群搭建
2.3.1 创建solr-cluster目录
在/usr/local/src下创建solr-cluster目录
![]()
2.3.2 copy 单机版的solr到该目录下
copy单机版的solr到该目录下,即:copy tomcat到该目录下
![]()
2.3.3 copy solr home到该目录下
![]()
2.3.4 删除solr home下的数据
![]()
2.3.5 修改tomcat下solr的home

2.3.6 zookeeper管理配置文件
由于zookeeper统一管理solr的配置文件(主要是schema.xml、solrconfig.xml), solrCloud各各节点使用zookeeper管理的配置文件。也就是将solr home目录下的conf里的所有配置文件上传到zookeeper中。
这里我们通过solr提供的zkCli.sh进行上传
执行如下脚本:
sh /usr/local/src/solr-4.10.3/example/scripts/cloud-scripts/zkcli.sh -zkhost 192.168.200.128:2181,192.168.200.128:2182,192.168.200.128:2183 -cmd upconfig -confdir /usr/local/src/solr-4.10.3/example/solr/collection1/conf/ -confname myconf -solrhome /usr/local/src/solr-4.10.3/example/solr |

2.3.7 查看文件是否上传成功
进入zookeeper任意的bin目录下


2.3.8 将solr与zookeeper进行关联
将solr与zookeeper进行关联,即将solr交给zookeeper进行管理,在tomcat的bin目录下修改catalina.sh
JAVA_OPTS="-DzkHost=192.168.200.128:2181,192.168.200.128:2182,192.168.200.128:2183" |

2.3.9 修改SolrCloud监控端口
修改solrhome下的solr.xml文件

2.3.10 依次copy 三份solr home
![]()
注意:修改solrCloud的端口分别为8081、8082、8083.
修改solr.xml中的端口
2.3.11 依次copy 三份tomcat

注意:
1、 指定solr home的位置
2、 修改tomcat的端口号,分别为:8081、8082、8083
2.3.12 solr分片配置
numShards=2 name=collection1 shard=shard1 coreNodeName=core_node1 |
以上参数说明
numShards=2 //分片数量
name=collection1 //core名称
shard=shard1 //所属分片
coreNodeName=core_node1 //结点名称
192.168.200.128:8080 片1 1节点

192.168.200.128:8081 片1 2节点

192.168.200.128:8082 片2 3节点

192.168.200.128:8083 片2 4节点

2.3.13 分别启动tomcat并测试


2.4 Solr的集群版Java接口
//集群版 Solr测试 @Test public void testSolrCloud() throws Exception { //配置三台zk的IP String zkHost = "192.168.200.128:2181,192.168.200.133:2181,192.168.200.134:2181"; //创建集群版客户端 CloudSolrServer solrServer = new CloudSolrServer(zkHost); //设置collection1 solrServer.setDefaultCollection("collection1"); //保存数据 //创建一个存储数据的Solr对象 SolrInputDocument doc = new SolrInputDocument(); //保存ID doc.setField("id", 4); //保存Name doc.setField("name", "我是中国人"); //保存数据 solrServer.add(doc); //手动提交 solrServer.commit();
} |
2.5 Solr集群版Java接口交由Spring管理
|
3 Redis集群
3.1 集群原理
3.1.1 原理

架构细节:
(1)所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽.
(2)节点的fail是通过集群中超过半数的节点检测失效时才生效.
(3)客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
(4)redis-cluster把所有的物理节点映射到[0-16383]slot上,cluster 负责维护node<->slot<->value
Redis 集群中内置了 16384 个哈希槽,当需要在 Redis 集群中放置一个 key-value 时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点。
redis集群的好处:将数据分散在不同的节点上,降低单个节点的吞吐量,从而提高单个节点的性能。
3.1.2 投票容错
(1)领着投票过程是集群中所有master参与,如果半数以上master节点与master节点通信超过(cluster-node-timeout),认为当前master节点挂掉.
(2):什么时候整个集群不可用(cluster_state:fail)?
a:如果集群任意master挂掉,且当前master没有slave.集群进入fail状态,也可以理解成集群的slot映射[0-16383]不完成时进入fail状态. ps : redis-3.0.0.rc1加入cluster-require-full-coverage参数,默认关闭,打开集群兼容部分失败.
b:如果集群超过半数以上master挂掉,无论是否有slave集群进入fail状态.
ps:当集群不可用时,所有对集群的操作做都不可用,收到((error) CLUSTERDOWN The cluster is down)错误

3.2 搭建步骤
3.2.1 准备环境
安装ruby
yum -y install ruby
yum -y install rubygems
3.2.2 Redis单机版时的数据删除

3.2.3 在/usr/local/src下创建目录

3.2.4 安装单个redis
3.2.4.1 软件上传
略
3.2.4.2 解压
略
3.2.4.3 编译并安装
![]()
3.2.4.4 copy 配置到redis的bin目录下
![]()
3.2.4.5 修改redis配置文件
1、 后台启动
![]()
2、 端口号
![]()
3、 开启redis集群功能

3.2.5 将该redis copy到redis-cluster目录下
![]()
3.2.6 继续复制5份redis并改名

3.2.7 分别修改redis端口号
端口分别为:7002、7003、7004、7005、7006
3.2.8 编写脚本启动该6个redis服务
1、 在redis-cluster目录下创建start-all.sh文件

2、 编辑脚本

cd /usr/local/src/redis-cluster/7001/bin ./redis-server redis.conf cd /usr/local/src/redis-cluster/7002/bin ./redis-server redis.conf cd /usr/local/src/redis-cluster/7003/bin ./redis-server redis.conf cd /usr/local/src/redis-cluster/7004/bin ./redis-server redis.conf cd /usr/local/src/redis-cluster/7005/bin ./redis-server redis.conf cd /usr/local/src/redis-cluster/7006/bin ./redis-server redis.conf |
3、 设置脚本的具有可执行权限:chmod u+x start-all.sh
![]()
4、 启动脚本:./start-all.sh

3.2.9 创建集群---使用ruby脚本
1、 将redis解压目录后的src/redis-trib.rb的文件copy到redis-cluster下

2、 执行redis-3.0.0.gem脚本
![]()
3、 执行rb脚本
在redis-cluster目录下执行该脚本:
![]()
./redis-trib.rb create --replicas 1 192.168.33.135:7001 192.168.33.135:7002 192.168.33.135:7003 192.168.33.135:7004 192.168.33.135:7005 192.168.33.135:7006 |

4、 结果

3.2.10 测试

3.2.11 Java接口操作Redis集群
//集群版Jedis @Test public void testJedisCluster() throws Exception { //创建Jedis的连接池配置类 JedisPoolConfig config = new JedisPoolConfig(); //设置最大连接数 config.setMaxTotal(5); //设置最大间隔数 config.setMaxIdle(3);
//节点集 Set //配置多个IP及端口号 hostAndPorts.add(new HostAndPort("192.168.200.128",6379)); hostAndPorts.add(new HostAndPort("192.168.200.128",6380)); hostAndPorts.add(new HostAndPort("192.168.200.128",6381)); hostAndPorts.add(new HostAndPort("192.168.200.128",6382)); hostAndPorts.add(new HostAndPort("192.168.200.128",6383)); hostAndPorts.add(new HostAndPort("192.168.200.128",6384)); //创建客户端(集群版) JedisCluster jedisCluster = new JedisCluster(hostAndPorts,config);
//保存数据 jedisCluster.set("hejiong", "40"); //取数据 String num = jedisCluster.get("hejiong"); System.out.println(num); } |
3.2.12 Java接口交由Spring进行管理
3.2.12.1 Redis.xml配置
|
3.2.12.2 TestJedis测试类中
//将Redis集群版的Java接口交由Spring管理 @Autowired private JedisCluster jedisCluster;
@Test public void testJedisClusterSpring() throws Exception { //保存数据 jedisCluster.set("xiena", "36"); //取数据 String num = jedisCluster.get("xiena"); System.out.println(num); } |