Tensorflow 2.0 学习资料
- https://www.tensorflow.org/tutorials/text/word_embeddings
- https://www.tensorflow.org/tutorials/text/nmt_with_attention
- https://www.tensorflow.org/tutorials/text/transformer
- https://www.tensorflow.org/tutorials/text/image_captioning
A machine learning platform from the future.
A core principle of Keras is “progressive disclosure of complexity”: it’s easy to get started, and you can gradually dive into workflows where you write more and more logic from scratch, providing you with complete control. This applies to both model definition, and model training.
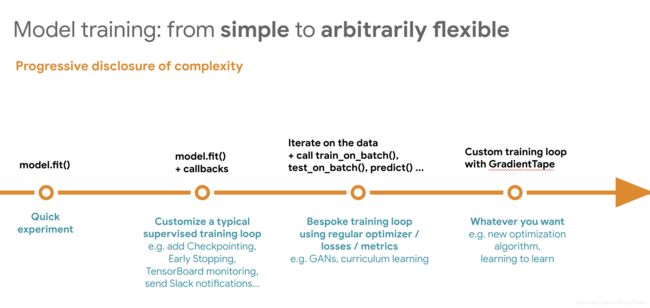
Resources to learn TensorFlow 2.0
- TensorFlow 2.0 + Keras Crash Course by Francois Chollet
- differences between models defined via subclassing and Functional models
- The Keras functional API in TensorFlow from official guide
- Train and evaluate with TensorFlow 2.0 from official guide
- Hands-On Machine Learning with Scikit-Learn, Keras and Tensor Flow by Aurélien Géron
- Inside TensorFlow: tf.Keras (video part 1) by Francois Chollet
- Inside TensorFlow: tf.Keras (video part 2) by Francois Chollet
Libraries and extensions
Tensorboard:https://www.tensorflow.org/tensorboard
部分笔记:
@tf.function: compile the training function into a static graph to speedup over 40%.- custom layers:
class Linear(Layer): """y = w.x + b""" # 定义全局变量 def __init__(self, units=32): super(Linear, self).__init__() self.units = units # 构建网络参数 def build(self, input_shape): self.w = self.add_weight(shape=(input_shape[-1], self.units), initializer='random_normal', trainable=True) self.b = self.add_weight(shape=(self.units,), initializer='random_normal', trainable=True) # 网络调用 def call(self, inputs): return tf.matmul(inputs, self.w) + self.b # Instantiate our lazy layer. linear_layer = Linear(4) # This will also call `build(input_shape)` and create the weights. y = linear_layer(tf.ones((2, 2))) assert len(linear_layer.weights) == 2 - loss classes are stateless: the output of
__call__is only a function of the input. - metrics are stateful. You update their state using the
update_statemethod, and you query the scalar metric result usingresult. self.add_loss: Sometimes you need to compute loss values on the fly during a forward pass (especially regularization losses). Layers can create losses during the forward pass. The losses created by sublayers are recursively tracked by the parent layers. You would typically use these losses by summing them before computing your gradients when writing a training loop.class ActivityRegularization(Layer): """Layer that creates an activity sparsity regularization loss.""" def __init__(self, rate=1e-2): super(ActivityRegularization, self).__init__() self.rate = rate def call(self, inputs): # We use `add_loss` to create a regularization loss # that depends on the inputs. self.add_loss(self.rate * tf.reduce_sum(tf.square(inputs))) return inputs- You can automatically retrieve the gradients of the weights of a layer by calling it inside a
GradientTape. Using these gradients, you can update the weights of the layer, either manually, or using an optimizer object.# Instantiate a linear layer with 10 units. linear_layer = Linear(10) # Instantiate a logistic loss function that expects integer targets. loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True) # Instantiate an optimizer. optimizer = tf.keras.optimizers.SGD(learning_rate=1e-3) # Iterate over the batches of the dataset. for step, (x, y) in enumerate(dataset): # Open a GradientTape. with tf.GradientTape() as tape: # Forward pass. logits = linear_layer(x) # Loss value for this batch. loss = loss_fn(y, logits) # Get gradients of weights wrt the loss. gradients = tape.gradient(loss, linear_layer.trainable_weights) # Update the weights of our linear layer. optimizer.apply_gradients(zip(gradients, linear_layer.trainable_weights)) - Keras functional API: Models with multiple inputs and outputs,manipulate non-linear connectivity topologies,sharing layer,custom layers
- It is less verbose.
- It validates your model while you’re defining it.
- Your Functional model is plottable and inspectable.
- Your Functional model can be serialized or cloned.
- It does not support dynamic architectures, which treats models as DAGs of layers.
- Train and evaluate with Keras: build-in training & evaluation loops (model.fit/model.evaluate/model.predict), training & evaluation loops from scratch (custom loops from scratch using eager execution and the GradientTape object)
- Custom losses
- Save and serialize models with Keras,Saving Subclassed Models
# Export the model to a SavedModel model.save('path_to_saved_model', save_format='tf') # Recreate the exact same model new_model = keras.models.load_model('path_to_saved_model') # Weights-only saving using Tensorflow checkpoints model.save_weights('path_to_my_tf_checkpoint', save_format='tf') - Checkpoints capture the exact value of all parameters (tf.Variable objects) used by a model. The SavedModel format on the other hand includes a serialized description of the computation defined by the model in addition to the parameter values (checkpoint). Models in this format are independent of the source code that created the model.