TensorFlow2.0 学习笔记 keras实战(下)
目录
- wide&Deep 模型
- 编程实战
- 函数式API 功能API
- 子类API
- 多输入与多输出
- 多输入实现
- 多输出实现
- 超参数搜索
- 手动实现超参数搜索
- 用sklearn 实现超参数搜索
- 1.定义并转化为sklearn的model
- 2.定义参数集合
- 3.搜索参数
- 打印超参数搜索结果
- 用超参数搜索得到的最好的model 来在测试集上验证
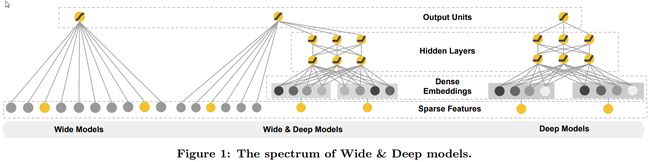
wide&Deep 模型
- 16年发布,用于分类和回归
- 应用在Google Play中的应用推荐
- 原始论文 https://arxiv.org/pdf/1606.07792v1.pdf
稀疏特征
- 离散值特征 eg.性别 工作 年龄
- One-hot 表示
- Eg:专业 = {计算机,人文,其他}. 人文=[0,1,0]
- Eg:词表={智能,你,他,我…}
- 叉乘=
- 叉乘之后
- 稀疏特征做叉乘 获取共现信息
- 实现记忆效果
- 叉乘之后
- 优点
- 有效,广泛应用于工业界(推荐算法)
- 缺点
- 需要人工设计 (选取特征)
- 可能过拟合,所有特征都叉乘,相当于记住每一个样本(泛化能力差)
密集特征
- 向量表达
- Eg 词表 ={智能,你,他,我}.
- 他 = [0.3,0.2,0.6(n维向量)]
- word2vec
- 男-女 = 国王-王后
- 把词语转换成向量,之后通过计算向量之间的距离,来确定词语之间的语义近似程度
- 优点
- 带有语音信息,不同向量之间有相关性
- 兼容没有出现过的特征组合
- 更少的人参与
- 缺点
- 过度泛化,推荐不怎么相关的产品
编程实战
- Wide & Deep 模型
- 子类API
- 功能API(函数式API)
- 多输入与多输出
在Wide&Deep模型中,要先划分特征是给Wide用还是Deep用.
训练数据选取 房价预测的数据集,因为其中8个特征.划分起来更有意义.
并没有选取图像分类测试集,因为图像分类中每一个特征重要性都是一样的.
因为wide&deep模型不是单一层级结构,所以不能使用Sequential模型
函数式API 功能API
input = keras.layers.Input(shape = x_train.shape[1:]) #使用Keras.Input 确定输入形状
hidden1 = keras.layers.Dense(30,activation="relu")(input) # 括号后面是这层的输入
hidden2 = keras.layers.Dense(30,activation = "relu")(hidden1)#实现了两层的模拟deep模型
concat = keras.layers.concatenate([input,hidden2]) # 把Wide 和Deep 模型拼接到一起
output = keras.layers.Dense(1)(concat) #应用拼接到一起的Wide&Deep模型构建最后一层
model = keras.models.Model(inputs = [input], #使用Keras.models.Model 固话所建立的model
outputs = [output])
子类API
- 完成的功能和上面 函数式 API一样 个人感觉这个有点抽象
# 子类API
class WideDeepModel(keras.models.Model):
def __init__(self):
super(WideDeepModel, self).__init__()
"""定义模型的层次"""
self.hidden1_layer = keras.layers.Dense(30, activation='relu')
self.hidden2_layer = keras.layers.Dense(30, activation='relu')
self.output_layer = keras.layers.Dense(1)
def call(self, input):
"""完成模型的正向计算"""
hidden1 = self.hidden1_layer(input)
hidden2 = self.hidden2_layer(hidden1)
concat = keras.layers.concatenate([input, hidden2])
output = self.output_layer(concat)
return output
model = WideDeepModel()
#model = keras.models.Sequential([
# WideDeepModel(),
#])
model.build(input_shape=(None, 8))
model.summary()
多输入与多输出
多输入实现
在很多情况下Wide 和Deep模型的输入特征不相同,所以就要有两个不同的输入
因为输入改变,所以对应的 **model.fit()**中的参数也要改变
同时train特征进行了改变,那么vaild 特征也要做相应改变,同样 test特征也要改变
input_wide = keras.layers.Input(shape = "5") # x_train 前5项
input_deep = keras.layers.Input(shape = "6") # x_train 后6项
hidden1 = keras.layers.Dense(30,activation="relu")(input_deep)
hidden2 = keras.layers.Dense(30,activation = "relu")(hidden1)
concat = keras.layers.concatenate([input_wide,hidden2])
output = keras.layers.Dense(1)(concat)
model = keras.models.Model(inputs = [input_wide,input_deep],
outputs = [output])
对多输入数据的构造
x_train_wide = x_train_scaled[:,:5]
x_train_deep = x_train_scaled[:,-6:]
x_valid_wide = x_valid_scaled[:,:5]
x_valid_deep = x_valid_scaled[:,-6:]
x_test_wide = x_test_scaled[:,:5]
x_test_deep = x_test_scaled[:,-6:]
fit函数的改写
history = model.fit([x_train_wide,x_train_deep], y_train,
validation_data = ([x_valid_wide,x_valid_deep], y_valid),
epochs = 100,
callbacks = callbacks)
多输出实现
比方说预测房价,可能需要根据当前的数据,既预测当前的价值,还要预测一年以后的房价,这样就需要有两部分输出
- 同时多输出 也可以在构建的网络的时候对多个模型,使用多输出,这样一次训练就可以得到多个想要的模型效果.在从好的效果中,选择你想要的模型.
- 多任务学习问题
- 不是模型上的改进,而是实际问题需要这种模型
程序实现
- 因为修改了输出的格式,所以不仅要修改model ,也要修改 fit中的output
input_wide = keras.layers.Input(shape = "5") # x_train 前5项
input_deep = keras.layers.Input(shape = "6") # x_train 后6项
hidden1 = keras.layers.Dense(30,activation="relu")(input_deep)
hidden2 = keras.layers.Dense(30,activation = "relu")(hidden1)
output2 = keras.layers.Dense(1)(hidden2) # 多输出修改处,创建一个输出
concat = keras.layers.concatenate([input_wide,hidden2])
output = keras.layers.Dense(1)(concat)
model = keras.models.Model(inputs = [input_wide,input_deep],
outputs = [output,output2]) # 多输出修改处,在model创建处
训练模型 修改
history = model.fit([x_train_wide,x_train_deep], [y_train,y_train], #修改
validation_data = ([x_valid_wide,x_valid_deep], #修改[y_valid,y_valid]),
epochs = 100,
callbacks = callbacks)
超参数搜索
- 神经网络训练过程中不变的参数
- 网络结构: 几层 每层宽度 每层激活函数
- 训练参数: batch_size 学习率,学习率衰减算法
- 搜索策略
- 网格搜索
- 随机搜索
- 遗传算法搜索
- 启发式搜索 - 最高端
网格搜索:
- 定义n维方格
- 每个方格对应一组超参数
- 一组组参数尝试 (可以并行提高速度)
- 缺点,最优解可能不在网格上.
随机搜索:
- 参数的生成方式是随机
- 搜索的范围大
- 慢(自己理解)
遗传算法
- 对自然界的模拟
- A.初始化候选参数->训练->得到模型指标作为生存概率
- B.选择->交叉->变异->产生下一代集合
- C.重新到A
- 找到表现最好的 遗传
启发式算法
- 研究热点-AutoMl
- 使用循环神经网络来生成参数
- 使用强化学习来进行反馈,使用模型来训练生成参数.
编程:使用scikit实现超参数搜索
手动实现超参数搜索
用矩阵配合 for循环直线 超参数搜索
learning_rate = [1e-4 ,1e-3 ,1e-2]
histories=[]
for lr in learning_rate:
input = keras.layers.Input(shape = x_train.shape[1:])
hidden1 = keras.layers.Dense(30,activation="relu")(input)
hidden2 = keras.layers.Dense(30,activation = "relu")(hidden1)
output = keras.layers.Dense(1)(hidden2)
model = keras.models.Model(inputs = [input],
outputs = [output])
optimizer = keras.optimizers.SGD(lr) #这里learn_rate 是在这里实现的修改
model.compile(loss="mean_squared_error", optimizer=optimizer)
callbacks = [keras.callbacks.EarlyStopping(
patience=5, min_delta=1e-3)]
history = model.fit(x_train_scaled, y_train,
validation_data = (x_valid_scaled, y_valid),
epochs = 100,
callbacks = callbacks)
histories.append(history)
图形化 显示
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize=(8,5))
plt.grid(True)
plt.gca().set_ylim(0,1)
plt.show()
for lr,history in zip(learning_rate,histories):
print("learning_rate : ",lr)
plot_learning_curves(history)
用sklearn 实现超参数搜索
RandomizedSearchCV
- 转化为sklearn的model
- 定义参数集合
- 搜索参数
1.定义并转化为sklearn的model
keras 创建 model
def build_model(hidden_layers = 1,
layer_size = 30,
learning_rate = 3e-3):
model = keras.models.Sequential()
model.add(keras.layers.Dense(layer_size, activation='relu',
input_shape=x_train.shape[1:]))
for _ in range(hidden_layers - 1):
model.add(keras.layers.Dense(layer_size,
activation = 'relu'))
model.add(keras.layers.Dense(1))
optimizer = keras.optimizers.SGD(learning_rate)
model.compile(loss = 'mse', optimizer = optimizer)
return model
把keras的model转换为sklearn的model
sklearn_model = KerasRegressor(
build_fn = build_model)
callbacks = [keras.callbacks.EarlyStopping(patience=5, min_delta=1e-2)]
开始训练
history = sklearn_model.fit(x_train_scaled, y_train,
epochs = 10,
validation_data = (x_valid_scaled, y_valid),
callbacks = callbacks)
2.定义参数集合
from scipy.stats import reciprocal
# f(x) = 1/(x*log(b/a)) a <= x <= b
param_distribution = {
"hidden_layers":[1, 2, 3, 4], #隐藏层数
"layer_size": np.arange(1, 100), #每层的节点数
"learning_rate": reciprocal(1e-4, 1e-2), #学习率
}
3.搜索参数
from sklearn.model_selection import RandomizedSearchCV
random_search_cv = RandomizedSearchCV(sklearn_model, #第一步设置的model
param_distribution, #定义参数的集合
n_iter = 10, # 参数集合 ??有点没有理解
cv = 3, #设置把测试集 拆分为 train 和vaild 比例 train/vaild=(3-1)
n_jobs = 1) #参数搜索,并行执行的个数
random_search_cv.fit(x_train_scaled, y_train, epochs = 100,
validation_data = (x_valid_scaled, y_valid),
callbacks = callbacks)
# cross_validation: 训练集分成n份,n-1训练,最后一份验证.
打印超参数搜索结果
print(random_search_cv.best_params_) #最好的参数
print(random_search_cv.best_score_) #最好的分值
print(random_search_cv.best_estimator_) #最好的model
用超参数搜索得到的最好的model 来在测试集上验证
model = random_search_cv.best_estimator_.model #获取模型
model.evaluate(x_test_scaled, y_test) #在测试集上训练