OpenStack学习 (4) - Nova
Nova整体架构
Nova控制着虚拟机的生老病死,管理他们的计算资源分配。
我们来看Nova的一个执行流程案例。
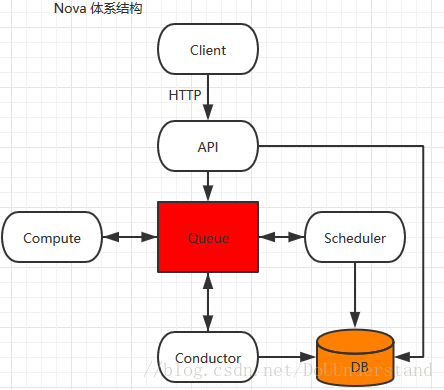
Step1:首先用户执行Nova Client提供的用于创建虚拟机的指令
Step2:nova-api service监听到来自于Nova Client的HTTP请求,并将这些请求转换为AMQP消息之后加入消息队列Queue
Step3:通过消息队列Queue调用nova-conductor service
Step4:nova-conductor service从Queue接收到虚拟机实例化请求消息后,进行一些准备工作(EG. 汇总HTTP请求中所需要实例化的虚拟机参数)
Step5:nova-conductor service通过Queue告诉nova-scheduler去选择一个合适的Compute Node来创建虚拟机,此时nova-scheduler会读取数据库的内容
Step6:nova-conductor从nova-scheduler得到了合适的Compute Node的信息后,在通过Queue来通知nova-compute service实现虚拟机的创建.
Nova主要有API、Compute、Conductor、Scheduler四个核心服务组成,这些服务之间通过AMQP消息队列来进行通信。
Nova API
nova-api主要用于接受Http请求,作为客户端与Nova质检的中间层,nova-api起到了一个桥梁的作用,接受客户端的请求,讲Nova处理完的请求结果返回给用户。
nova-api接收哪些请求?
简单的说,只要是跟虚拟机生命周期相关的操作,nova-api都可以响应。比如用户需要创建一个VM或者销毁一个VM。
当nova-api收到client发送过来的Client时,会经历以下两个步骤。
1.Paste将请求路由到具体的WSGI Application
2.WSGI Application到具体的执行函数
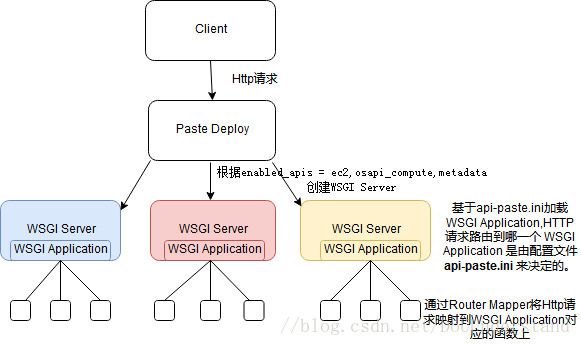
在Openstack中,每个资源都被封装成为一个nova.api.openstack.wsgi.Resource 对象,且对应着一个 WSGI Application ,这样就保证了资源的独立性。上面,我们已经确定了处理 HTTP请求的 Application,除此之外,我们还需要继续的去确定这个 HTTP 请求希望执行 Application中具体的哪一个操作函数。
比如“GET/v3/servers/detail”最终会定位到nova.api.openstack.compute.plugins.v3.ServersController.detail()函数。
Conductor
nova-compute需要获取和更新数据库中虚拟机的信息。以前,nova-compute可以直接访问数据库,但是这样很不安全。nova-conductor加入之后就解耦了nova-compute和数据库之间的联系。
nova-compute所有访问数据库的操作都交给nova-conductor完成,处于安全性考虑,最好不好讲nova-compute和nova-conductor部署在同一台服务器上。
Scheduler
nova-scheduler主要作用是裁决虚拟机的生存空间和资源分配,它通过考虑内存使用率与CPU负载等多种因素为虚拟机选择一个合适的主机。
创建instance时用户会提出资源需求,例如 CPU、内存、磁盘各需要多少。OpenStack 将这些需求定义在 Flavor 中,用户只需要指定用哪个Flavor 就可以了。
Flavor 主要定义了 VCPU,RAM,DISK 和 Metadata 这四类。 nova-scheduler 会按照 Flavor去选择合适的计算节点。
调度器
Nova中实现的调度器有
ChanceScheduler(随机调度器):从所有nova-compute服务正常运行的节点随机选择
FilterScheduler(过滤调度器):根据指定条件过滤选择最佳节点
不同的调度器不能共存FilterScheduler是默认调度器。
FilterScheduler
Filter scheduler 是 nova-scheduler 默认的调度器,调度过程分为两步:
(1)通过过滤器(filter)选择满足条件的计算节点(运行 nova-compute)
(2)通过权重计算(weighting)选择在最优(权重值最大)的计算节点上创建 Instance。
Scheduler 可以使用多个 filter 依次进行过滤,过滤之后的节点再通过计算权重选出最适合的节点。

如图,最终Host5得分最高,最终入选。
Filters
在调用Filters之前,先要从数据库中同步数据获取各个主机的资源情况,包括内存容量等。获取之后就开始调用Filters进行筛选。
Nova中常用的Filters有
AllHostsFilter:不进行任何过滤
RamFilter:根据内存情况过滤
ComputerFilter:挑选出处于活跃状态的主机
TrustedFilter:挑选出可信的主机
CoreFilter:将不能满足VCPU的过滤掉
DiskFilter:根据磁盘需求过滤
Filters一般组合使用,具体使用哪些Filter一般在配置文件中指定。
Weight
经过 filter 的过滤,nova-scheduler 选出了能够部署 instance 的计算节点。
如果有多个计算节点通过了过滤,那么最终选择哪个节点呢?
Scheduler 会对每个计算节点打分,选择得分最高的一个。
打分的过程就是 weight,翻译过来就是计算权重值,那么 scheduler 是根据什么来计算权重值呢?
目前 nova-scheduler 的默认实现是根据计算节点空闲的内存量计算权重值:
空闲内存越多,权重越大,instance 将被部署到当前空闲内存最多的计算节点上。
Compute
nova-compute一般管理虚拟机的生命周期。
但是我们要清楚,Nova并不提供虚拟化技术,只是借助主流虚拟化(比如:Xen KVM等)实现虚拟机的创建与管理,因此nova-compute需要和各种不同的hypervisor进行交互。目前Nova实现了Hyperv、Libvirt、VMware以及XenAPI四种。
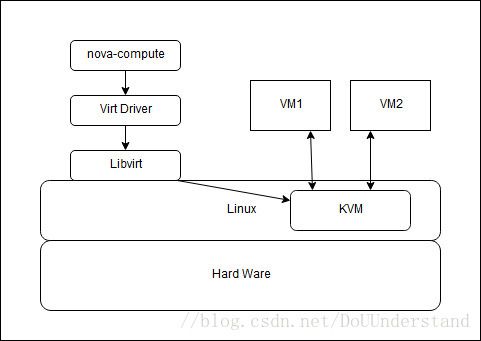
如上图:nova-compute安装部署在安装了Linux+KVM的主机上,nova-compute调用Libvirt提供的API实现虚拟机管理。
可以选择指定的Virt Driver,默认为Libvirt Driver
compute_driver = libvirt.LibvirtDriver