numpy初认识
numpy是数值化的python,
Python list的替代品:numpy array
可以对整个数组进行计算
操作方便,且快速
height = [1.56,1.75,1.60,1.68]
weight = [45,65,50,52]
print weight / height ** 2
上面的代码运行错误

但是有了numpy,这个问题是可以解决的
# 计算身体质量指数 (Body Mass Index, 简称BMI)
import numpy as np
height = [1.56,1.75,1.60,1.68]
weight = [45,65,50,52]
np_heigh = np.array(height)
np_weigh = np.array(weight)
print np_weigh / np_heigh ** 2
#输出 [ 18.49112426 21.2244898 19.53125 18.42403628]
注意
numpy数组的元素的类型是相同的。
>>> np.array([1.0,"is",True])
array(['1.0', 'is', 'True'],
dtype='|S4')
分清list和numpy数组的区别,对list进行 “ + ” 运算是两个list连接起来,numpy数组则是对应的元素逐个相加。
>>> python_list = [1,2,3]
>>> numpy_array = np.array([1,2,3])
>>> python_list + python_list
[1, 2, 3, 1, 2, 3]
>>> numpy_array + numpy_array
array([2, 4, 6])
>>> numpy_array + python_list
array([2, 4, 6])
numpy的构造子集
先将上述的计算身体质量指数的结果赋给变量bmi,其中bmi>19输出了bool类型的list,满足这个条件的元素对于的值是True。对于bmi[bmi>19],则是选取到了值大于19的子集。
>>> bmi = np_weigh / np_heigh ** 2
>>> print bmi
[ 18.49112426 21.2244898 19.53125 18.42403628]
>>> bmi > 19
array([False, True, True, False], dtype=bool)
>>> bmi[bmi>19]
array([ 21.2244898, 19.53125 ])
>>> bmi[1]
21.224489795918366
numpy数组的类型
numpy数组的类型:ndarray
>>> type(bmi)
ndarray表示n维数组,下面来看看二维数组,以及它的构造子集是怎样的。
其中的np_2d[:,1:3],逗号前面没有指明第几行,表示所有行都被选取,逗号后是1:3表示选择第2列和第3列的值。结果就是每行的第2列和第3列的值。
np_2d[:1,1:3]根据切片的特点,冒号后面的数字不包含,结果也就是第0(即第一行)的第2列和第3列的值。
>>> np_2d = np.array([[1,2,3,4],[5,6,7,8]])
>>> np_2d
array([[1, 2, 3, 4],
[5, 6, 7, 8]])
>>> np_2d.shape
(2, 4)
>>> np_2d[0]
array([1, 2, 3, 4])
>>> np_2d[0][2]
3
>>> np_2d[:,1:3]
array([[2, 3],
[6, 7]])
>>> np_2d[1,:]
array([5, 6, 7, 8])
>>> np_2d[:1,1:3]
array([[2, 3]])
平均数 mean 和中位数 median
>>> np_dd = np.array([[1.56,40],[1.67,50],[1.60,45],[1.75,60],[1.68,53]])
>>> np.mean(np_dd[:,0])
1.6519999999999999
>>> np.median(np_dd[:,0])
1.6699999999999999
np.random.normal(平均数mean,标准差stdev,size):给出均值为mean,标准差为stdev的高斯随机数(场),当size赋值时,例如:size=100,表示返回100个高斯随机数。
高斯分布的概率密度函数 numpy.random.normal( )
numpy中 ,numpy.random.normal(loc=0.0, scale=1.0, size=None)
参数的意义为:
loc:float
概率分布的均值,对应着整个分布的中心center
scale:float
概率分布的标准差,对应于分布的宽度,scale越大越矮胖,scale越小,越瘦高
size:int or tuple of ints
输出的shape,默认为None,只输出一个值
我们更经常会用到np.random.randn(size)所谓标准正太分布(μ=0, σ=1),对应于np.random.normal(loc=0, scale=1, size)
np.column_stack(a,b):函数column_stack以列将一维数组合成二维数组
>>> height = np.round(np.random.normal(1.75,0.20,5000),2)
>>> weight = np.round(np.random.normal(60.32,15,5000),2)
>>> np_city = np.column_stack((height,weight))
>>> np_city
array([[ 1.49, 70.15],
[ 2.12, 61.91],
[ 1.38, 58.53],
...,
[ 1.63, 74.36],
[ 1.44, 73.57],
[ 1.95, 52.57]])
可视化matplotlib
>>> import matplotlib.pyplot as plt
>>> year = [1950,1970,1990,2010]
>>> pop = [2.519,3.692,5.263,6.972]
>>> plt.plot(year,pop)
[]
>>> plt.show()
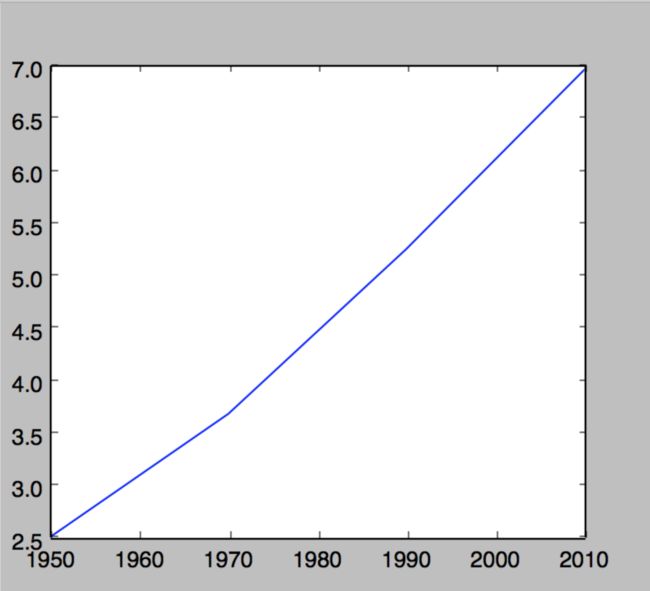
改成是散点图,改变一下函数即可
plt.plot(year,pop)改为
plt.scatter(year,pop)
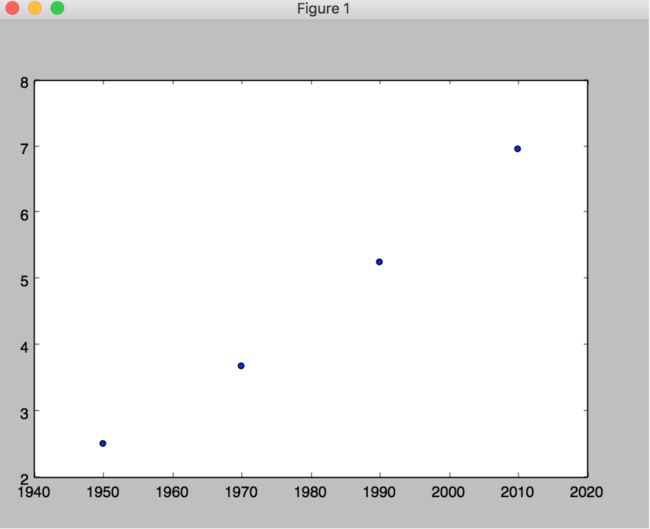
直方图
plt.hist(value,bins=3)
>>> value= [0.12,0.4,1.4,1.2,2.3,3.0,2.5,3.9,2.1,2.7,4.6,4.5,5.6]
>>> plt.hist(value,bins=3)
(array([ 4., 5., 4.]), array([ 0.12 , 1.94666667, 3.77333333, 5.6 ]), )
>>> plt.show()
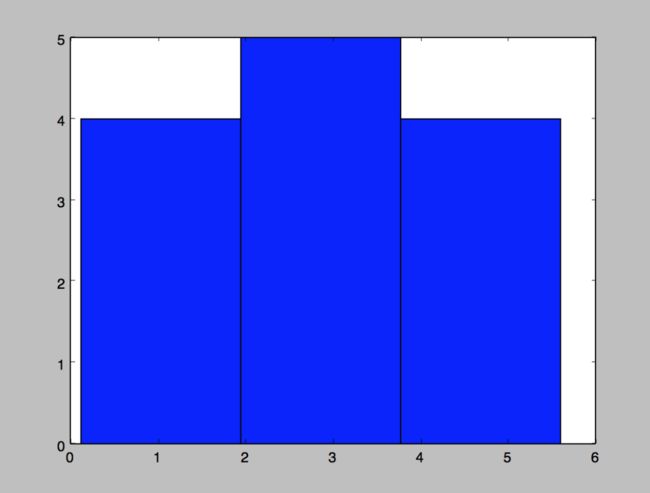
个性化图标
颜色填充函数 plt.fill_between()
设置x轴标签 plt.xlabel()
设置y轴标签 plt.ylabel()
设置图标标题 plt.title()
设置y轴的刻度 plt.yticks([0,2,4,6,8,10])
>>> import matplotlib.pyplot as plt
>>> year = [1950,1970,1990,2010]
>>> pop = [1.0,3.9,6.8,9.9]
>>> plt.fill_between(year,pop,0,color='green')
>>> plt.xlabel('year')
>>> plt.ylabel('population')
>>> plt.title('population projections')
>>> plt.yticks([0,2,4,6,8,10])
([, , , , , ], )
>>> plt.show()
