Oracle 11g学习笔记--分析函数
Oracle 11g学习笔记–分析函数
示例表:
评级函数
rank()/dense_rank()
返回数据项在分组中的排名,前者在排名相等的情况下,会留下空位,后者不会
select emp_id, sum(amount),
rank() over (order by sum(amount) desc [{nulls last]|nulls first}]) as rank,
dense_rank() over (order by sum(amount) desc) as dense_rank
from all_sales
group by emp_id;
该句中的desc的含义就是降序,可换为asc进行升序排名;
[{nulls last]|nulls first}]指明了,将空结果排列在第一名,还是最排在最后一名;默认的情况下,系统会视空数据为最低,再根据升序或者降序选择显示位置;
cume_dist和percent_rank函数
cume_dist可以计算某个特定值相对于一组值中的位置;
percent_rank可计算某个值相对于一组值的百分比排名;
select
prd_type_id, sum(amount),
cume_dist() over (order by sum(amount) desc) as cume_dist,
percent_rank() over (order by sum(amount) desc) as percent_rank
from all_sales
where year = 2003
group by prd_type_id
order by sum(amount) desc;
从中我们便容易便可以看出两个函数的作用了
ntile(buket)函数
可以计算n分片的值,buket指定了分片的片数,记录将被分组为buket个片。
select prd_type_id, sum(amount),
ntile(3) over(order by sum(amount) desc) as ntile
from all_sales
where year = 2003
and amount is not null
group by prd_type_id
order by sum(amount) desc;
可以看出片规定了最低的名次,多出的名次均是第一;
row_number
row_number()从1开始,为每一条分组记录返回一个数字。
select
prd_type_id, sum(amount),
dense_rank() over (order by sum(amount) desc nulls last) as dense_rank,
row_number() over (order by sum(amount) desc nulls last) as row_number
from all_sales
where year = 2003
group by prd_type_id
order by sum(amount) desc;
通过该图初步判定(猜测)row_number()的作用,和dense_rank作用一样;只不过在排名相等的情况下,不可能出现并排;
反百分点函数
反百分点函数有两个:percentile_disc(x)和percentile_cont(x)
他们的作用于cume_dist()和percent_rank()相反。percentile_disc(x)在每一个分组中检查累积分布的数值,直到大于或者等于x的值。
percentile_cont(x)在每一个分组中检查百分比排名的值,直到周到找打大于或者等于x的值。
select
percentile_cont(0.6) within group (order by sum(amount) desc) as percentile_count,
percentile_disc(0.5) within group (order by sum(amount) desc) as percentile_disc
from all_sales
where year = 2003 and amount is not null
group by prd_type_id;? percentile_cont()什么意思,没看懂。
窗口函数
窗口函数可以计算一定记录范围内,一定值域内,或者一段时间内的累计和以及移动平均值。窗口可以与这些函数结合使用:sum(), avg(), max(), min(), count(), variance(), stddev(), first_value(), last_value()。
那么窗口函数到底用来干什么的呢?
- 计算累计和
select
month, sum(amount) as m_amount,
sum(sum(amount)) over (order by month rows between unbounded preceding and current row) as cumulative_amount
from all_sales
where year = 2003
group by month
order by month;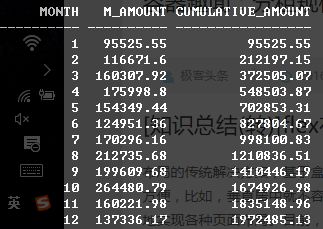
- 计算移动平均值
select
month as month, sum(amount) as month_amount,
sum(sum(amount)) over (order by month rows between unbounded preceding and current row) as sum,
avg(sum(amount)) over (order by month rows between unbounded preceding and current row) as avg
from all_sales
where year = 2003 and month between 6
and 12
group by month
order by month;
从上图可以看出所谓的移动平均值就是将当前行到窗口起点所有项的平均值,其实计算的项是根据窗口大小具体而定的;
- 计算中心平均值
select
month, sum(amount) as month_amount,
sum(sum(amount)) over (order by month rows between 1 preceding and 1 following) as moving_sum,
avg(sum(amount)) over (order by month rows between 1 preceding and 1 following) as moving_average
from all_sales
where year = 2003
group by month
order by month;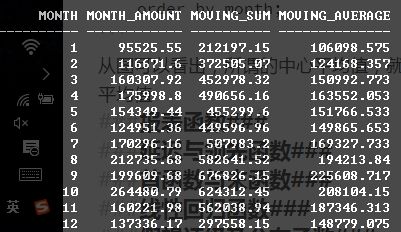
从图可以看出,所谓的中心平均值,就是讲当月和上月的平均值
frist_value和last_value
这个函数的作用是获取窗口的第一行和最后一行数据
使用方法和上面的类似,读者自测;
补充:不知道从以上的列子中你是否看出了over里面语句的作用没?
其实它的作用就是规定了一个窗口,而前面的函数只是对这个窗口的函数进行操作;窗口规定:
between 1 preceding and 1 following:就是从前一行到后一行
between unbounded preceding and current row:(未绑定,默认从开始处,)从最开始处到当前行
报表函数
报表函数可用与执行跨越分组和组内分区的计算。
总计报表
select
month, prd_type_id,
sum(sum(amount)) over (partition by month)
as total_month_amount,
sum(sum(amount)) over (partition by prd_type_id) as total_type_amount
from all_sales
where year = 2003 and month <= 3
group by month, prd_type_id
order by month, prd_type_id;
表达式分解:
sum(amount)计算一个销量的总和,外的sum()计算总计
over(pratition by month)让外部的sum()计算每一个月的总计
使用patio_to_report函数
该函数用来计算某个值在一组值的总和中所占的比率;
select month,
sum(amount) as prd_type_amount,
ratio_to_report(sum(amount)) over (partition by month) as prd_type_ratio from all_sales
where year = 2003 and month <= 3
group by month, prd_type_id
order by month;
月总计
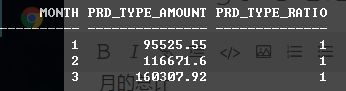
从两张图可以看出,计算的是当行的数据在总计中所占的比率
延迟与领先函数
lag和lead函数可获取距当前记录指定距离处的那条记录中的数据。
select month, sum(amount) as month_amount,
lag(sum(amount), 2) over (order by month) as previous_month_amount,
lead(sum(amount), 2) over (order by month) as next_month_amount
from all_sales
where year = 2003
group by month
order by month;
首函数与末函数
first和last函数可获取一个排序分组中的第一个值和最后一个值.rirst和last可以与系列函数一起使用:min(), max(), sum(), avg(), stddev(), varlance().
select
max(month) keep (dense_rank first order by sum(amount)) as highest_sales_month,
min(month) keep (dense_rank last order by sum(amount))
from all_sales
where year = 2003
group by month
order by month;
-------------------------------------
select
month, sum(amount)
from all_sales
group by month
order by sum(amount);

线性回归函数
线性回归函数可以用普通最小平方回归曲线拟合一组数值对,线性回归函数可用于聚合,窗口或报表函数;
| 函数 | 说明 |
| regr_avgx(y,x) | 先去除x或y为空值的x和y数值对,然后返回x的平均值 |
| regr_avgy(y,x) | 先去除x或y为空值的x和y数值对,然后返回y的平均值 |
| regr_count(y,x) | 返回可用于拟合回归曲线的非空数值对个数 |
| regr_intercept(y,x) | 返回回归曲线在y轴方向的截距 |
| regr_r2(y,x) | 返回回归曲线的决定系数,或相关系数(R-squared) |
| regr_slope(y,x) | 返回回归曲线的斜率 |
| regr_sxx(y,x) | 返回reg_count(y,x)*var_pop(x) |
| regr_sxy(y,x) | 返回reg_count(y,x)*covar_pop(y,x) |
| regr_syy(y,x) | 返回reg_count(y,x)*var_pop(y) |
select
prd_type_id,
regr_avgx(&&y,&&x) as avgx,
regr_avgy(&&y,&&x) as avgy,
regr_count(&&y,&&x) as count,
regr_intercept(&&y,&&x) as intercept,
regr_r2(&&y,&&x) as r2,
regr_slope(&&y,&&x) as solpe,
regr_sxx(&&y,&&x) as sxx,
regr_sxy(&&y,&&x) as sxy,
regr_syy(&&y,&&x) as syy
from all_sales
where year = 2003
group by prd_type_id;参数:y=amount , x=month

这方面实在是没有了解过,有点难以入脑;
假想评级及分布函数
假想评级与分布函数可以计算一条新的记录在表中的排名和百分比,而不用将其插入表中。下面这些函数可以与假想计算结合使用:rank(), dense_rank(), percent_rank()和cume_dist()。
select
prd_type_id, sum(amount),
rank() over (order by sum(amount) desc) as rank,
percent_rank() over (order by sum(amount) desc) as rank
from all_sales
where year = 2003 and amount is not null
group by prd_type_id
order by sum(amount);
---------------------------------------
select
rank(&&amount) within group (order by sum(amount) desc) as rank,
percent_rank(&&amount) within group (order by sum(amount) desc) as percent_rank
from all_sales
where year = 2003 and amount is not null
group by prd_type_id
order by prd_type_id;
参数:amount=500000

通过这种方式可以估计出排名,这就是假想评级