1.了解其出现的背景
googlenet和vgg是2014年imagenet竞赛的双雄,这两类模型结构有一个共同特点是go deeper。跟vgg不同的是,googlenet做了更大胆的网络上的尝试而不是像vgg继承了lenet以及alexnet的一些框架,该模型虽然 有22层,但大小却比alexnet和vgg都小很多,性能优越。
2.优化方向提出的动机
简而言之:要提高网络性能->加深网络深度和宽度->大大增加了运算量和过拟合->提出将全连接甚至一般的卷积都转化为稀疏连接->计算机对非均匀稀疏数据的计算效率却很差->需要一个即能保持网络结构稀疏性,又能利用密集矩阵的高计算性能的网络
3.优化细节
首先,作者提出了下面的结构
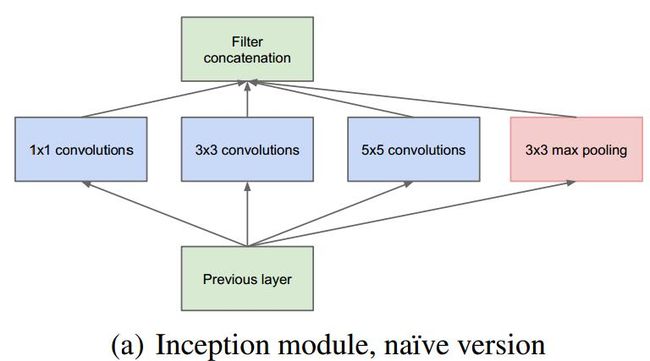
优点:
1.不同的卷积核意味不同的感受野,最后拼接能将不同尺度的特征相融合
2. 卷积核之所以大小采用1、3和5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定pad=0、1、2,那么卷积之后便可以得到相同维度的特征,然后这些特征就可以直接拼接在一起了;
3. 加pooling是因为文章说很多地方都表明pooling挺有效,所以Inception里面也嵌入了。
4.网络越到后面,特征越抽象,而且每个特征所涉及的感受野也更大了,因此随着层数的增加,3x3和5x5卷积的比例也要增加。
这就出现了一个问题:使用5x5的卷积核仍然会带来巨大的计算量。
为此,文章借鉴NIN2,采用1x1卷积核来进行降维。
(原文的运算推理我现在看不懂,以后你线性代数复习好以后回过头再来理解)
结构如下:
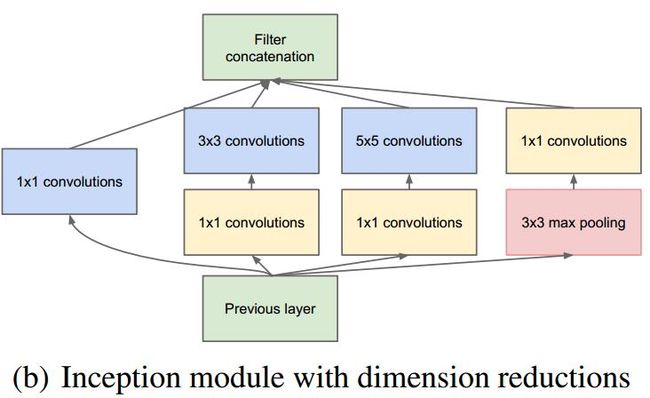
但同样,GoogLeNet在低层上保持为传统卷积方式不变,只在较高的层开始用Inception模块
最后的效果:
一是允许显著增加每一步的单元数目,计算复杂性不会不受控制。降维的普遍使用能保护最后一步到下一层的大量输入滤波器,在对它们 用大的patch size卷积前首先降维。
二是视觉信息在不同的尺度上进行处理然后聚合,这样下一步可以同时从不同尺度提取特征。
三是采用了Inception模块的网络要比没有采用Inception模块的同样架构的网络快2~3倍。
4.整体架构
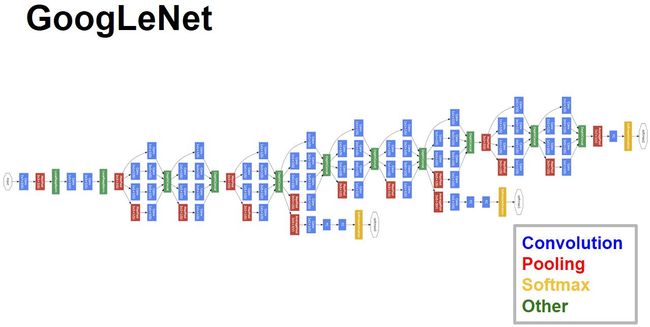

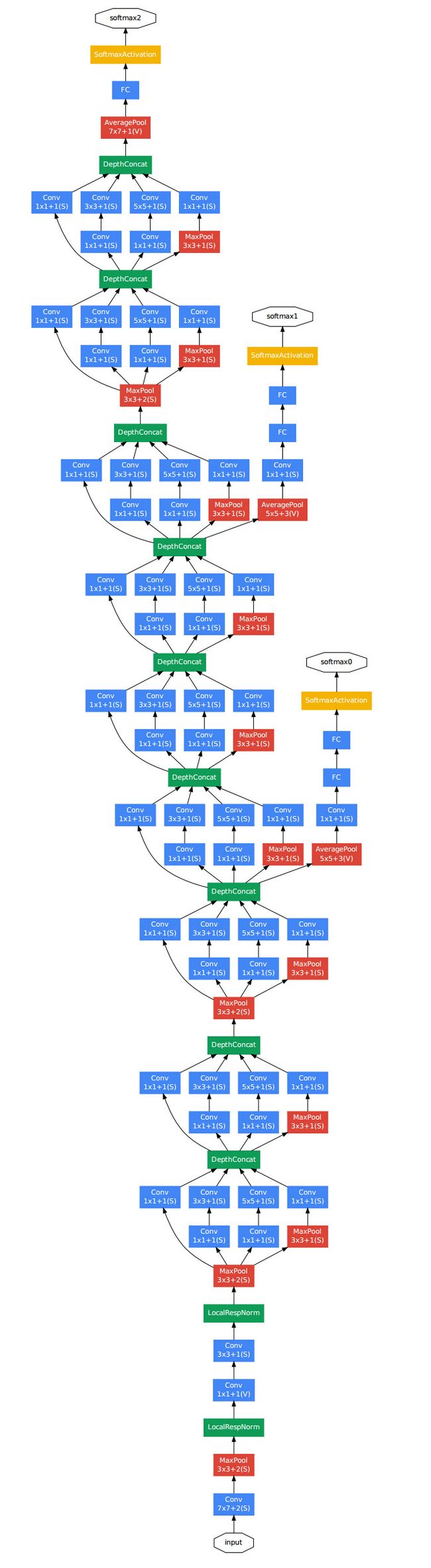
架构细节:
1.显然GoogLeNet采用了模块化结构,方便增添和修改。
2.网络最后采用average pooling,这是第二处采用NIN的地方,事实证明可以将TOP1的accuracy提高0.6%,实际还是加了FC,意思是方便大家微调。
3.虽然移除了全连接,但是网络中依然使用了Dropout ;
4.为里避免梯度消失,网络增加了两个辅助的softmax用于前向传导梯度。
5.包括Inception模块的所有卷积,都用了修正单元(Relu)。
6.网络的感受野是224*224,采用彩色通道,且都进行了减均值操作。
7.网络中间的层次生成的特征会非常有区分性,给这些层增加一些辅助分类器。这些分类器以小卷积网络的形式放在Inception(4a)和Inception(4b)的输出上。在训练过程中,损失会根据折扣后的权重(折扣权重为0.3)叠加到总损失中。
这个仅仅是GoogLeNet的V1版本理解,如果要深入理解,可以这个博客:
https://blog.csdn.net/shuzfan/article/details/50738394
借鉴的也是这两个博客
https://blog.csdn.net/shuzfan/article/details/50738394
https://www.cnblogs.com/Allen-rg/p/5833919.html