从头学习大数据 spark 基于内存的分布式计算框架(一)spark 介绍、RDD 原理、spark 开发环境搭建
1.什么Spark
Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发的通用内存并行计算框架,用于构建大型的、低延迟的数据分析应用程序。
Spark使用Scala语言开发,它还提供了对Scala、Python、Java(支持Java 8)和R语言的支持
Apache顶级项目
2.Spark历史
2009年由Berkeley's AMPLab开始编写最初的源代码
2010年开放源代码
2013年6月进入Apache孵化器项目
2014年2月成为Apache的顶级项目(8个月时间)
2014年5月底Spark1.0.0发布,打破Hadoop保持的基准排序纪录
2014年12月Spark1.2.0发布
2015年11月Spark1.5.2发布
2016年1月Spark1.6发布
2016年12月Spark2.1发布
3.为什么要用Spark
运行速度快:使用DAG执行引擎以支持循环数据流与内存计算
易用性好:支持使用Scala、Java、Python和R语言进行编程,可以通过Spark Shell进行交互式编程
通用性强:Spark提供了完整而强大的工具,包括SQL查询、流式计算、机器学习和图算法组件
随处运行:可运行于独立的集群模式中,可运行于Hadoop中,也可运行于Amazon EC2等云环境中,并且可以访问HDFS、Cassandra、HBase、Hive等多种数据源
在这里还是要推荐下我自己建的大数据学习交流群:199427210,群里都是学大数据开发的,如果你正在学习大数据 ,小编欢迎你加入,大家都是软件开发党,不定期分享干货(只有大数据软件开发相关的),包括我自己整理的一份2018最新的大数据进阶资料和高级开发教程,欢迎进阶中和进想深入大数据的小伙伴加入。
4.对比Hadoop
解决问题的出发点不一样
Hadoop用普通硬件解决存储和计算问题
Spark用于构建大型的、低延迟的数据分析应用程序,不实现存储
Spark是在借鉴了MapReduce之上发展而来的,继承了其分布式并行计算的优点并改进了MapReduce明显的缺陷
Spark中间数据放到内存中,迭代运算效率高
Spark引进了弹性分布式数据集的抽象,数据对象既可以放在内存,也可以放在磁盘,容错性高,可用自动重建
RDD计算时可以通过CheckPoint来实现容错
Hadoop只提供了Map和Reduce操作,Spark更加通用,提供的数据集操作类型有很多种,主要分为: Transformations和Actions两大类
5.spark生态

spark core实现了spark的基本功能、包括任务调度、内存管理、错误恢复与存储系统交互等模块。spark core中还包含了对弹性分布式数据集(resileent distributed dataset)的定义
spark sql是spark用来操作结构化数据的程序,能过SPARK SQL,我们可以使用SQL或者HIVE(HQL)来查询数据,支持多种数据源,比如HIVE表就是JSON等,除了提供SQL查询接口,还支持将SQL和传统的RDD结合,开发者可以在一个应用中同时使用SQL和编程的方式(API)进行数据的查询分析,SPARK SQL是在1.0中被引入的
Spark Streaming是Spark提供的对实时数据进行流式计算的组件,比如网页服务器日志,或者是消息队列都是数据流。
MLLib是Spark中提供常见的机器学习功能的程序库,包括很多机器学习算法,比如分类、回归、聚类、协同过滤等。
GraphX是用于图计算的比如社交网络的朋友关系图。
6.Spark应用场景
Yahoo将Spark用在Audience Expansion中的应用,进行点击预测和即席查询等
淘宝技术团队使用了Spark来解决多次迭代的机器学习算法、高计算复杂度的算法等。应用于内容推荐、社区发现等
腾讯大数据精准推荐借助Spark快速迭代的优势,实现了在“数据实时采集、算法实时训练、系统实时预测”的全流程实时并行高维算法,最终成功应用于广点通pCTR投放系统上。
优酷土豆将Spark应用于视频推荐(图计算)、广告业务,主要实现机器学习、图计算等迭代计算
7.spark编程
1.RDD设计背景
在实际应用中,存在许多迭代式计算,这些应用场景的共同之处是,不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。但是,目前的MapReduce框架都是把中间结果写入到HDFS中,带来了大量的数据复制、磁盘IO和序列化开销。显然,如果能将结果保存在内存当中,就可以大量减少IO。RDD就是为了满足这种需求而出现的,它提供了一个抽象的数据架构,我们不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换处理,不同RDD之间的转换操作形成依赖关系,可以实现管道化,从而避免了中间结果的落地存储,大大降低了数据复制、磁盘IO和序列化开销。
2.RDD概念
一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可以分成多个分区,每个分区就是一个数据集片段(HDFS上的块),并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算。RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,不能直接修改,只能基于稳定的物理存储中的数据集来创建RDD,或者通过在其他RDD上执行确定的转换操作(如map、join和groupBy)而创建得到新的RDD。RDD提供了一组丰富的操作以支持常见的数据运算,分为“行动”(Action)和“转换”(Transformation)两种类型,前者用于执行计算并指定输出的形式,后者指定RDD之间的相互依赖关系。两类操作的主要区别是,转换操作(比如map、filter、groupBy、join等)接受RDD并返回RDD,而行动操作(比如count、collect等)接受RDD但是返回非RDD(即输出一个值或结果)。
Spark用Scala语言实现了RDD的API,程序员可以通过调用API实现对RDD的各种操作。RDD典型的执行过程如下:
RDD读入外部数据源(或者内存中的集合)进行创建;
RDD经过一系列的“转换”操作,每一次都会产生不同的RDD,供给下一个“转换”使用;
最后一个RDD经“行动”操作进行处理,并输出到外部数据源(或者变成Scala/JAVA集合或变量)。
需要说明的是,RDD采用了惰性调用,即在RDD的执行过程中,真正的计算发生在RDD的“行动”操作,对于“行动”之前的所有“转换”操作,Spark只是记录下“转换”操作应用的一些基础数据集以及RDD生成的轨迹,即相互之间的依赖关系,而不会触发真正的计算。
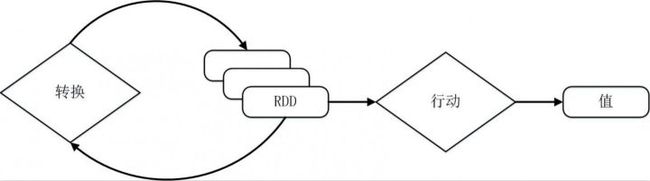
从输入中逻辑上生成A和C两个RDD,经过一系列“转换”操作,逻辑上生成了F(也是一个RDD),之所以说是逻辑上,是因为这时候计算并没有发生,Spark只是记录了RDD之间的生成和依赖关系。当F要进行输出时,也就是当F进行“行动”操作的时候,Spark才会根据RDD的依赖关系生成DAG,并从起点开始真正的计算。

这一系列处理称为一个“血缘关系(Lineage)”,即DAG拓扑排序的结果。采用惰性调用,通过血缘关系连接起来的一系列RDD操作就可以实现管道化(pipeline),避免了多次转换操作之间数据同步的等待,而且不用担心有过多的中间数据,因为这些具有血缘关系的操作都管道化了,一个操作得到的结果不需要保存为中间数据,而是直接管道式地流入到下一个操作进行处理。同时,这种通过血缘关系把一系列操作进行管道化连接的设计方式,也使得管道中每次操作的计算变得相对简单,保证了每个操作在处理逻辑上的单一性;相反,在MapReduce的设计中,为了尽可能地减少MapReduce过程,在单个MapReduce中会写入过多复杂的逻辑。
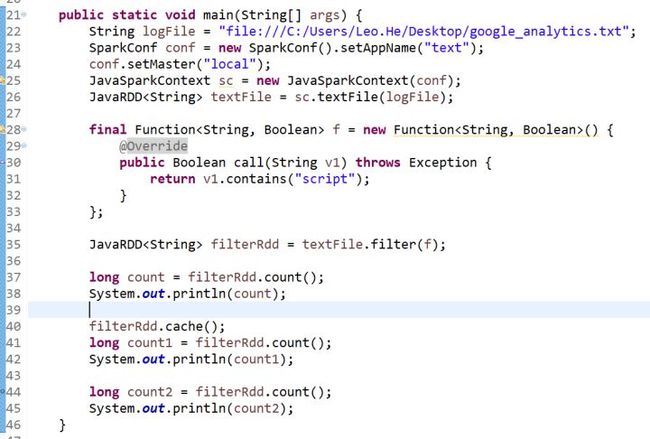
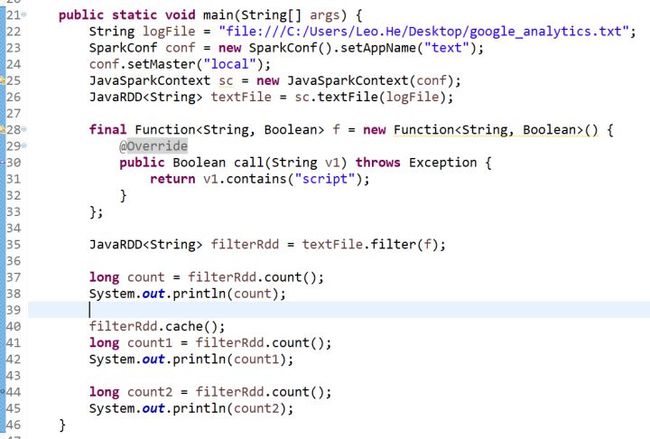
java程序示例
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD lines = sc.textFile(logFile);
lines.filter(new Function() {
@Override
public Boolean call(String v1) throws Exception {
return v1.contains("helle world");
}
});
lines.cache();
long count = lines.count();
System.out.println(count);
可以看出,一个Spark应用程序,基本是基于RDD的一系列计算操作。第1行代码用于创建JavaSparkContext对象;第2行代码从HDFS文件中读取数据创建一个RDD;第3行代码对fileRDD进行转换操作得到一个新的RDD,即filterRDD;lines.cache()表示对filterRDD进行持久化,把它保存在内存或磁盘中(这里采用cache接口把数据集保存在内存中),方便后续重复使用,当数据被反复访问时(比如查询一些热点数据,或者运行迭代算法),这是非常有用的,而且通过cache()可以缓存非常大的数据集,支持跨越几十甚至上百个节点;lines.count()是一个行动操作,用于计算一个RDD集合中包含的元素个数。这个程序的执行过程如下:
创建这个Spark程序的执行上下文,即创建SparkContext对象;
从外部数据源(即HDFS文件)中读取数据创建fileRDD对象;
构建起fileRDD和filterRDD之间的依赖关系,形成DAG图,这时候并没有发生真正的计算,只是记录转换的轨迹;
执行action代码时,count()是一个行动类型的操作,触发真正的计算,开始实际执行从fileRDD到filterRDD的转换操作,并把结果持久化到内存中,最后计算出filterRDD中包含的元素个数。
3.RDD特性
总体而言,Spark采用RDD以后能够实现高效计算的主要原因如下:
(1)高效的容错性。现有的分布式共享内存、键值存储、内存数据库等,为了实现容错,必须在集群节点之间进行数据复制或者记录日志,也就是在节点之间会发生大量的数据传输,这对于数据密集型应用而言会带来很大的开销。在RDD的设计中,数据只读,不可修改,如果需要修改数据,必须从父RDD转换到子RDD,由此在不同RDD之间建立了血缘关系。所以,RDD是一种天生具有容错机制的特殊集合,不需要通过数据冗余的方式(比如检查点)实现容错,而只需通过RDD父子依赖(血缘)关系重新计算得到丢失的分区来实现容错,无需回滚整个系统,这样就避免了数据复制的高开销,而且重算过程可以在不同节点之间并行进行,实现了高效的容错。此外,RDD提供的转换操作都是一些粗粒度的操作(比如map、filter和join),RDD依赖关系只需要记录这种粗粒度的转换操作,而不需要记录具体的数据和各种细粒度操作的日志(比如对哪个数据项进行了修改),这就大大降低了数据密集型应用中的容错开销;
(2)中间结果持久化到内存。数据在内存中的多个RDD操作之间进行传递,不需要“落地”到磁盘上,避免了不必要的读写磁盘开销;
(3)存放的数据可以是Java对象,避免了不必要的对象序列化和反序列化开销。
RDD之间的依赖关系
RDD中不同的操作会使得不同RDD中的分区会产生不同的依赖。RDD中的依赖关系分为窄依赖(Narrow Dependency)与宽依赖(Wide Dependency)
两种依赖之间的区别。
窄依赖表现为一个父RDD的分区对应于一个子RDD的分区,或多个父RDD的分区对应于一个子RDD的分区
宽依赖则表现为存在一个父RDD的一个分区对应一个子RDD的多个分区

总体而言,如果父RDD的一个分区只被一个子RDD的一个分区所使用就是窄依赖,否则就是宽依赖。窄依赖典型的操作包括map、filter、union等,宽依赖典型的操作包括groupByKey、sortByKey等。对于连接(join)操作,可以分为两种情况。
(1)对输入进行协同划分,属于窄依赖。所谓协同划分(co-partitioned)是指多个父RDD的某一分区的所有“键(key)”,落在子RDD的同一个分区内,不会产生同一个父RDD的某一分区,落在子RDD的两个分区的情况。
(2)对输入做非协同划分,属于宽依赖,。
对于窄依赖的RDD,可以以流水线的方式计算所有父分区,不会造成网络之间的数据混合。对于宽依赖的RDD,则通常伴随着Shuffle操作,即首先需要计算好所有父分区数据,然后在节点之间进行Shuffle。
窄依赖与宽依赖的区别
Spark的这种依赖关系设计,使其具有了天生的容错性,大大加快了Spark的执行速度。因为,RDD数据集通过“血缘关系”记住了它是如何从其它RDD中演变过来的,血缘关系记录的是粗颗粒度的转换操作行为,当这个RDD的部分分区数据丢失时,它可以通过血缘关系获取足够的信息来重新运算和恢复丢失的数据分区,由此带来了性能的提升。相对而言,在两种依赖关系中,窄依赖的失败恢复更为高效,它只需要根据父RDD分区重新计算丢失的分区即可(不需要重新计算所有分区),而且可以并行地在不同节点进行重新计算。而对于宽依赖而言,单个节点失效通常意味着重新计算过程会涉及多个父RDD分区,开销较大。此外,Spark还提供了数据检查点和记录日志,用于持久化中间RDD,从而使得在进行失败恢复时不需要追溯到最开始的阶段。在进行故障恢复时,Spark会对数据检查点开销和重新计算RDD分区的开销进行比较,从而自动选择最优的恢复策略。
5.阶段的划分
Spark通过分析各个RDD的依赖关系生成了DAG,再通过分析各个RDD中的分区之间的依赖关系来决定如何划分阶段,具体划分方法是:在DAG中进行反向解析,遇到宽依赖就断开,遇到窄依赖就把当前的RDD加入到当前的阶段中;将窄依赖尽量划分在同一个阶段中,可以实现流水线计算。例如,假设从HDFS中读入数据生成3个不同的RDD(即A、C和E),通过一系列转换操作后再将计算结果保存回HDFS。对DAG进行解析时,在依赖图中进行反向解析,由于从RDD A到RDD B的转换以及从RDD B和F到RDD G的转换,都属于宽依赖,因此,在宽依赖处断开后可以得到三个阶段,即阶段1、阶段2和阶段3。可以看出,在阶段2中,从map到union都是窄依赖,这两步操作可以形成一个流水线操作,比如,分区7通过map操作生成的分区9,可以不用等待分区8到分区9这个转换操作的计算结束,而是继续进行union操作,转换得到分区13,这样流水线执行大大提高了计算的效率。
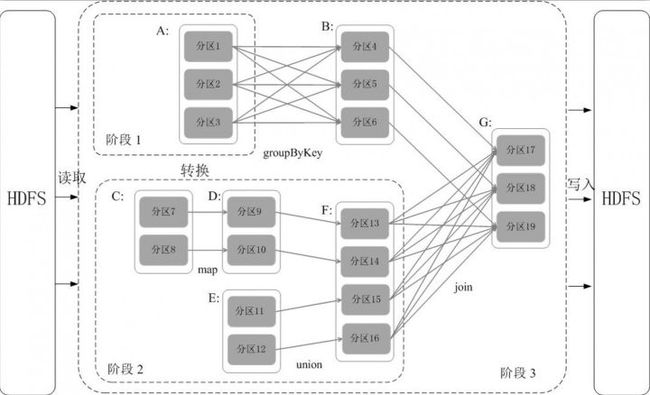
由上述论述可知,把一个DAG图划分成多个“阶段”以后,每个阶段都代表了一组关联的、相互之间没有Shuffle依赖关系的任务组成的任务集合。每个任务集合会被提交给任务调度器(TaskScheduler)进行处理,由任务调度器将任务分发给Executor运行。
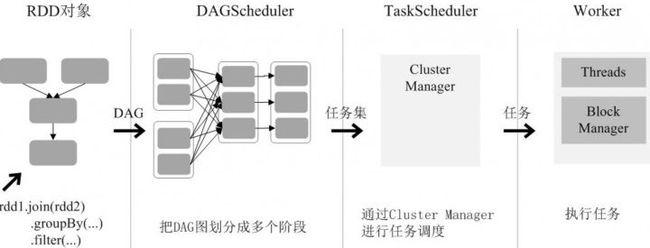
通过上述对RDD概念、依赖关系和阶段划分的介绍,结合之前介绍的Spark运行基本流程,这里再总结一下RDD在Spark架构中的运行过程:
(1)创建RDD对象;
(2)SparkContext负责计算RDD之间的依赖关系,构建DAG;
(3)DAGScheduler负责把DAG图分解成多个阶段,每个阶段中包含了多个任务,每个任务会被任务调度器分发
给各个工作节点(Worker Node)上的Executor去执行。
RDD支持两种类型的操作:
transformation:从一个RDD转换为一个新的RDD。
action:基于一个数据集进行运算,并返回RDD。
例如,map是一个transformation操作,map将数据集的每一个元素按指定的函数转换为一个RDD返回。reduce是一个action操作
Spark的所有transformation操作都是懒执行,它们并不立马执行,而是先记录对数据集的一系列transformation操作。这种设计让Spark的运算更加高效,例如,对一个数据集map操作之后使用reduce只返回结果,而不返回庞大的map运算的结果集。
默认情况下,每个转换的RDD在执行action操作时都会重新计算。即使两个action操作会使用同一个转换的RDD,该RDD也会重新计算。除非使用persist方法或cache方法将RDD缓存到内存,这样在下次使用这个RDD时将会提高计算效率,也支持将RDD持久化到硬盘上,或在多个节点上复制
8.Transformations
下面列出了Spark常用的transformation操作。详细的细节请参考RDD API文档(Scala、Java、Python、R)和键值对RDD方法文档(Scala、Java)。
map(func)
将原来RDD的每个数据项,使用map中用户自定义的函数func进行映射,转变为一个新的元素,并返回一个新的RDD。
filter(func)
使用函数func对原RDD中数据项进行过滤,将符合func中条件的数据项组成新的RDD返回。
flatMap(func)
类似于map,但是输入数据项可以被映射到0个或多个输出数据集合中,所以函数func的返回值是一个数据项集合而不是一个单一的数据项。
mapPartitions(func)
类似于map,但是该操作是在每个分区上分别执行,所以当操作一个类型为T的RDD时func的格式必须是Iterator => Iterator。即mapPartitions需要获取到每个分区的迭代器,在函数中通过这个分区的迭代器对整个分区的元素进行操作。
mapPartitionsWithIndex(func)
类似于mapPartitions,但是需要提供给func一个整型值,这个整型值是分区的索引,所以当处理T类型的RDD时,func的格式必须为(Int, Iterator) => Iterator。
sample(withReplacement, fraction, seed)
对数据采样。用户可以设定是否有放回(withReplacement)、采样的百分比(fraction)、随机种子(seed)。
union(otherDataset)
返回原数据集和参数指定的数据集合并后的数据集。使用union函数时需要保证两个RDD元素的数据类型相同,返回的RDD数据类型和被合并的RDD元素数据类型相同。该操作不进行去重操作,返回的结果会保存所有元素。如果想去重,可以使用distinct()。
intersection(otherDataset)
返回两个数据集的交集。
distinct([numTasks]))
将RDD中的元素进行去重操作。
groupByKey([numTasks])
操作(K,V)格式的数据集,返回 (K, Iterable)格式的数据集。
注意,如果分组是为了按key进行聚合操作(例如,计算sum、average),此时使用reduceByKey或aggregateByKey计算效率会更高。
注意,默认情况下,并行情况取决于父RDD的分区数,但可以通过参数numTasks来设置任务数。
reduceByKey(func, [numTasks])
使用给定的func,将(K,V)对格式的数据集中key相同的值进行聚集,其中func的格式必须为(V,V) => V。可选参数numTasks可以指定reduce任务的数目。
aggregateByKey(zeroValue)(seqOp, combOp,[numTasks])
对(K,V)格式的数据按key进行聚合操作,聚合时使用给定的合并函数和一个初试值,返回一个(K,U)对格式数据。需要指定的三个参数:zeroValue为在每个分区中,对key值第一次读取V类型的值时,使用的U类型的初始变量;seqOp用于在每个分区中,相同的key中V类型的值合并到zeroValue创建的U类型的变量中。combOp是对重新分区后两个分区中传入的U类型数据的合并函数。
sortByKey([ascending], [numTasks])
(K,V)格式的数据集,其中K已实现了Ordered,经过sortByKey操作返回排序后的数据集。指定布尔值参数ascending来指定升序或降序排列。
join(otherDataset, [numTasks])
用于操作两个键值对格式的数据集,操作两个数据集(K,V)和(K,W)返回(K, (V, W))格式的数据集。通过leftOuterJoin、rightOuterJoin、fullOuterJoin完成外连接操作。
cogroup(otherDataset, [numTasks])
用于操作两个键值对格式数据集(K,V)和(K,W),返回数据集格式为 (K,(Iterable, Iterable)) 。这个操作也称为groupWith。对在两个RDD中的Key-Value类型的元素,每个RDD相同Key的元素分别聚合为一个集合,并且返回两个RDD中对应Key的元素集合的迭代器。
cartesian(otherDataset)
对类型为T和U的两个数据集进行操作,返回包含两个数据集所有元素对的(T,U)格式的数据集。即对两个RDD内的所有元素进行笛卡尔积操作。
pipe(command, [envVars])
以管道(pipe)方式将 RDD的各个分区(partition)使用 shell命令处理(比如一个 Perl或 bash脚本)。 RDD的元素会被写入进程的标准输入(stdin),将进程返回的一个字符串型 RDD(RDD of strings),以一行文本的形式写入进程的标准输出(stdout)中。
coalesce(numPartitions)
把RDD的分区数降低到通过参数numPartitions指定的值。在得到的更大一些数据集上执行操作,会更加高效。
repartition(numPartitions)
随机地对RDD的数据重新洗牌(Reshuffle),从而创建更多或更少的分区,以平衡数据。总是对网络上的所有数据进行洗牌(shuffles)。
repartitionAndSortWithinPartitions(partitioner)
根据给定的分区器对RDD进行重新分区,在每个结果分区中,按照key值对记录排序。这在每个分区中比先调用repartition再排序效率更高,因为它可以将排序过程在shuffle操作的机器上进行。
9.Actions
下面列出了Spark支持的常用的action操作。详细请参考RDD API文档(Scala、Java、Python、R)和键值对RDD方法文档(Scala、Java)。
reduce(func)
使用函数func聚集数据集中的元素,这个函数func输入为两个元素,返回为一个元素。这个函数应该符合结合律和交换了,这样才能保证数据集中各个元素计算的正确性。
collect()
在驱动程序中,以数组的形式返回数据集的所有元素。通常用于filter或其它产生了大量小数据集的情况。
count()
返回数据集中元素的个数。
first()
返回数据集中的第一个元素(类似于take(1))。
take(n)
返回数据集中的前n个元素。
takeSample(withReplacement,num, [seed])
对一个数据集随机抽样,返回一个包含num个随机抽样元素的数组,参数withReplacement指定是否有放回抽样,参数seed指定生成随机数的种子。
takeOrdered(n, [ordering])
返回RDD按自然顺序或自定义顺序排序后的前n个元素。
saveAsTextFile(path)
将数据集中的元素以文本文件(或文本文件集合)的形式保存到指定的本地文件系统、HDFS或其它Hadoop支持的文件系统中。Spark将在每个元素上调用toString方法,将数据元素转换为文本文件中的一行记录。
saveAsSequenceFile(path) (Java and Scala)
将数据集中的元素以Hadoop Sequence文件的形式保存到指定的本地文件系统、HDFS或其它Hadoop支持的文件系统中。该操作只支持对实现了Hadoop的Writable接口的键值对RDD进行操作。在Scala中,还支持隐式转换为Writable的类型(Spark包括了基本类型的转换,例如Int、Double、String等等)。
saveAsObjectFile(path) (Java and Scala)
将数据集中的元素以简单的Java序列化的格式写入指定的路径。这些保存该数据的文件,可以使用SparkContext.objectFile()进行加载。
countByKey()
仅支持对(K,V)格式的键值对类型的RDD进行操作。返回(K,Int)格式的Hashmap,(K,Int)为每个key值对应的记录数目。
foreach(func)
对数据集中每个元素使用函数func进行处理。该操作通常用于更新一个累加器(Accumulator)或与外部数据源进行交互。注意:在foreach()之外修改累加器变量可能引起不确定的后果。详细介绍请阅读
10.Spark环境部署
主要运行方式
Local
Standalone
On YARN
On Mesos
11.环境依赖
Linux,CentOS 6/7
安装JDK
下载 spark 安装包
http://spark.apache.org/downloads.html
12.应用开发环境
JDK 1.8
Eclipse 4.6
Scala-IDE
http://scala-ide.org
Scala 2.11 可选
http://www.scala-lang.org
1.eclipse的scala开发插件
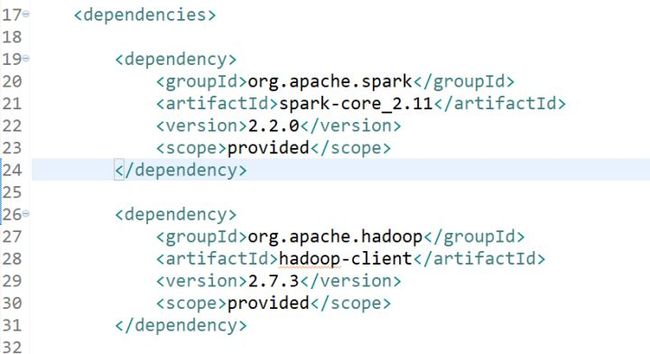
2.开发spark项目的maven依赖

2.开发spark项目的maven依赖