《Phrase-Based & Neural Unsupervised Machine Translation》阅读
这周例会上分享了《Phrase-Based & Neural Unsupervised Machine Translation》这篇文章,同时在csdn上也写一下吧
论文中主要提出了两个模型,分别是基于神经网络的NMT和基于N-Gram的词频统计模型。作者说使用非监督的方式翻译,只要遵循一下三个原则,就可以实现,而不在于模型。所以在这里我只介绍其中的NMT模型。
作者在文章中提出无监督的MT的核心原理可以分成一下三个原则:
- 初始化(Initialization)
- 语言建模(Language Modeling)
- 迭代反向翻译(Iterative Back-translation)
一般看到这里可能会不太清楚,所以我用自己的语言重新描述下他这三个原则的目的是什么:
- 初始化:文中通过这一步获得了一个将不同语言的字嵌入空间进行了对齐,这样就产生了一个可以进行逐字翻译的模型。
- 语言模型:在有了一个逐字翻译的模型之后,使用单语言侧的语言模型,去将翻译出来的不完整的不流利的翻译进行改进,使得在当前语言下符合语法和规范。同时,这样产生的语料可以作为平行语料。这就是第二步单侧语言模型的作用。
- 反向翻译:翻译大约可以看做是A语言->B语言的过程,反向翻译则是将这一过程反向,即从B->A的过程。由于上一阶段已经产生了平行语料,这样将这个平行语料翻译回A的过程,就是反向翻译的过程,且这一成程可以看做是一个有监督的学习(已知正确的语言为A)。
好了,通过这样的描述,大概就能明白了论文的大体思路:
1)简单的词到词的翻译模型
2)使用语言模型让他变得更流程,并获得平行语料
3)使用平行语料,进行有监督的学习。
接下来,我们就可以看看论文具体是什么实现这三步的:
词嵌入的旋转对齐
Facebook无监督机器翻译的方法,首先是让系统学习双语词典,将一个词与其他语言对应的多种翻译联系起来。举个例子,就好比让系统学会“Bug”在作为名词时,既有“虫子”、“计算机漏洞”,也有“窃听器”的意思。
Facebook使用了他们在之前发表于ICLR 2018的论文《Word Translation Without Parallel Data》中介绍的方法,让系统首先为每种语言中的每个单词学习词嵌入,也即单词的向量表示。
然后,系统会训练词嵌入,根据其上下文(例如,给定单词前后的各5个单词)来预测给定单词周围的单词。尽管词嵌入是一种非常简单的表示方法,但从中可以获得很有趣的语义结构。例如,与“kitty”(小猫)这个词距离最近的是“cat”(猫),并且“kitty”这个词与“animal”(动物)之间的距离要远远小于它与“rocket”(火箭)这个词的距离。换句话说,“kitty”很少出现在有“rocket”的上下文里。
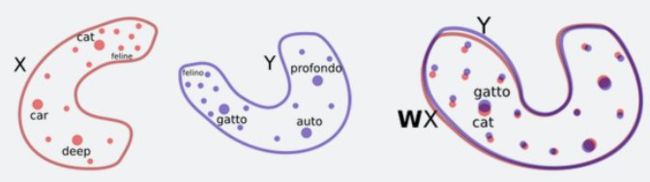
可以通过简单的旋转并对齐两种语言(X和Y)的二维词嵌入,然后通过最近邻搜索实现单词翻译。
鉴于这些相似之处,Facebook的研究人员提出了一种方法,让系统通过对抗训练等方法,学习将一种语言的词嵌入结构进行旋转,从而匹配另一种语言的词嵌入结构。有了这些信息以后,他们就可以推断出一个相当准确的双语词典,无需任何已经翻译好的语句,并且基本上可以做到逐字翻译。

如上图所示,作者使用GAN网络的方式去生成一个线性映射W,用WX的方式去拟合Y,然后使用判别器去判断WX和Y。这样的方式就是讲问题转成了一个图上去的图形匹配的问题,具体的优化方法,可以看procrustes分析问题。
语言模型
通过旋转并对齐不同语言的词嵌入结构,得到词到词的翻译
用无监督反向翻译技术,训练句到句的机器翻译系统
当逐字翻译实现以后,接下来就是词组乃至句子的翻译了。
当然,逐字翻译的结果是无法直接用在句子翻译上的。于是,Facebook的研究人员又使用了一种方法,他们训练了一个单语种语言模型,对逐字翻译系统给出的结果打分,从而尽可能排除不符合语法规则或有语病的句子。
这个单语模型比较好获得,只要有小语种(比如乌尔都语)的大量单语数据集就可以。英语的单语模型则更好构建了。
通过使用单语模型对逐字翻译模型进行优化,就得到了一个比较原始的机器翻译系统。

这里的语言模型的损失函数如图,(即随机的删除句子中的一些词和交换句子中词的位置,对句子进行还原。)
虽然翻译结果不是很理想,但这个系统已经比逐字翻译的结果更好了,并且它可以将大量句子从源语言(比如乌尔都语)翻译成目标语言(比如英语)。
反向翻译
接下来,Facebook研究人员再将这些机器翻译所得到的句子(从乌尔都语到英语的翻译)作为ground truth,用于训练从英语到乌尔都语的机器翻译。这种技术最先由R. Sennrich等人在ACL 2015时提出,叫做“反向翻译”,当时使用的是半监督学习方法(有大量的语言对)。这还是反向翻译技术首次应用于完全无监督的系统。
我们举例来详细说明:
Source : 英语 Traget:乌尔都语

这里把英语看做输入x,那么输出的乌尔都语 v ∗ ( x ) v^*(x) v∗(x)的表达式为:
v ∗ ( x ) = a r g m a x P s → t ( v ∣ x ) v^*(x) = arg max P_{s\to t}(v|x) v∗(x)=argmaxPs→t(v∣x)
即:在输入x的情况下,当翻译模型给出 v v v的概率最大时,即是 x x x在乌尔都语下的翻译 v v v
再通过由单语种语料训练的语言模型将翻译变得更符合语法和规范,这样就可以生成平行语料 P t → t ( v ∗ ( x ) ) P_{t\to t}(v^*(x)) Pt→t(v∗(x))。

这样,再将 P t → t ( v ∗ ( x ) ) P_{t\to t}(v^*(x)) Pt→t(v∗(x))的语料翻译 x x x的过程,即为反向翻译,即为上图中多出来的部分。
而进行这一任务时,我们已知的是 x x x是一定正确的,即是有标签的,可以认为是一个有监督的任务,即翻译由一个无监督任务转变成了一个有监督任务。
我们又可以将翻译的过程看做是:
A->B的过程,但是同样的也存在着一个由B->A的反过程。

因此必要存在一个反过程。所以将这两个过程结合在一起时,就可以使得系统形成一个闭合的回路。可以进行循环迭代提升效果。
![]()
反向翻译的loss函数如图。
不可否认,由于第一个系统(从乌尔都语到英语的原始机器翻译系统)的翻译错误,作为训练数据输入的英语句子质量并不高,因此第二个反向翻译系统输出的乌尔都语翻译效果可想而知。
不过,有了刚才训练好的那个乌尔都语单语模型,就可以用它来对第二个反向翻译系统输出的乌尔都语译文进行校正,从而不断优化、迭代,逐渐完善第二个反向翻译系统。
参考资料:
BPE算法
《Word translation without parallel data》
论文笔记:Word translation without parallel data无监督单词翻译
《Improving Neural Machine Translation Models with Monolingual Data》
《Dual Learning for Machine Translation》
https://blog.csdn.net/cassiePython/article/details/74929801
https://tech.sina.com.cn/roll/2018-09-02/doc-ihiixyeu2050302.shtml
http://tech.ifeng.com/a/20180920/45176353_0.shtml
没有数据也能翻译?一文读懂「无监督」机器翻译