Spark排序算法系列之(MLLib、ML)GBTs使用方式介绍(模型训练、保存、加载、预测)

“ Spark推荐排序系列文章之GBDT(梯度提升决策树)介绍”
前言
【Spark排序算法系列】主要介绍的是目前推荐系统或者广告点击方面用的比较广的几种算法,和他们在Spark中的应用实现,本篇文章主要介绍GBDT算法,本系列还包括(持续更新):
-
Spark排序算法系列之LR(逻辑回归)
-
Spark排序算法系列之模型融合(GBDT+LR)
-
Spark排序算法系列之XGBoost
-
Spark排序算法系列之FTRL(Follow-the-regularized-Leader)
-
Spark排序算法系列之FM与FFM
在本篇文章中你可以学到:
-
Spark MLLib包中的GBDT使用方式
-
模型的通过保存、加载、预测
-
PipeLine
-
ML包中的GBDT
概述
LR因为其容易并行最早应用到推荐排序中的,但学习能力有限,需要大量的特征工程来增加模型的学习能力。但大量的特征工程耗时耗力,且不一定带来效果的提升,因此在如何能有效的发现特征组合,来缩短LR特征实验周期的背景下,GBDT被应用了起来。GBDT模型全称是Gradient Boosting Decision Tree,梯度提升决策树。是属于Boosing算法中的一种,关于Boosting的介绍可以参考文章集成学习(Ensemble Learning)
关于GBDT算法理解可参考:
-
Spark排序算法系列之GBTs基础——梯度上升和梯度下降
-
梯度提升决策树GBDT(Gradient Boosting Decision Tree)
其实相信很多人对Spark 机器学习包(ml和mllib)中的GBDT傻傻分不清楚,这里我们先来捋一捋。Spark中的GBDT较GBTs——梯度提升树,因为其是基于决策树(Decision Tree,DT)实现的,所以叫GBDT。Spark 中的GBDT算法存在于ml包和mllib包中,mllib是基于RDD的,ml包则是针对DataFrame的,ml包中的GBDT分为分类和回归,在实际使用过程中,需要根据具体情况进行衡量和选择。由于在实际生产环境中使用基于RDD的较多,所以下面将着重介绍下MLLib包中的GBTs,ML包中的将进行简单说明。
MLLib中的GBTs
在前边提到了GBTs是基于决策树(Decision Tree,DT),所以不了解DT的朋友可以先进行学习,这里就不做过多解释。GBDT 在Spark中的使用方式如下描述
创建Spark对象并加载数据
// 文件路径
val file = "data/new_sample_libsvm_data.txt"
val model_path = "output/gbdt/"
// 创建spark对象
val spark = SparkSession.builder().master("local[5]")
.appName("GBDT_MLLib_Model_Train")
.getOrCreate()
Logger.getRootLogger.setLevel(Level.WARN)
// 使用MLUtils加载文件,并拆分成训练集和测试集
val split = MLUtils.loadLibSVMFile(spark.sparkContext, file).randomSplit(Array(0.7,0.3))
val (train, test) = (split(0), split(1))
GBDT参数初始化
def getBoostingParam(): BoostingStrategy = {
val boostingStrategy = BoostingStrategy.defaultParams("Regression")
//一般不需要修改模型的学习率,除非模型训练结果值变化很大时,降低学习率的值
boostingStrategy.setLearningRate(boostingStrategy.getLearningRate())
// 迭代次数
boostingStrategy.setNumIterations(10)
// 设置树的深度,若树过深,容易导致过拟合
boostingStrategy.treeStrategy.setMaxDepth(5)
// 连续特征离散化的最大数量
boostingStrategy.treeStrategy.setMaxBins(10)
// 分裂后节点包含最少的实例个数
boostingStrategy.treeStrategy.setMinInstancesPerNode(2)
// 设置分类的数量
boostingStrategy.treeStrategy.setNumClasses(2)
// 设置最小信息增益值
boostingStrategy.treeStrategy.setMinInfoGain(1e-4)
//设置基类纯度值的计算方法,针对分类问题,支持基尼系数和信息增益
//(org.apache.spark.mllib.tree.impurity.Entropy)
boostingStrategy.treeStrategy.setImpurity(org.apache.spark.mllib.tree.impurity.Gini)
boostingStrategy.treeStrategy.categoricalFeaturesInfo = Map[Int, Int]()
boostingStrategy
}模型训练与测试集加载
// 创建模型
val model = GradientBoostedTrees.train(train, boostingStrategy)
// 测试集测试
val test_result = test.map( line => {
val pre_label = model.predict(line.features)
//计算各个树预测值与树权重的点积;计算得到的结果值作为模型计算得到的分数值,用于排序
// 查看predict源码
val treePredictions = model.trees.map(_.predict(line.features))
val pre_score = blas.ddot(model.numTrees, treePredictions, 1, model.treeWeights, 1)
// 将森林生成的各个树得到的预测分值进行变形,得到最终用户点击的预估值
val score = Math.pow(1+Math.pow(Math.E, -2 * pre_score), -1)
(line.label, pre_label, score)
})
// 打印10条结果
test_result.take(10).foreach(println)效果验证
def evaluteResult(test_result: RDD[(Double, Double, Double)]): Unit = {
// MSE
val testMSE = test_result.map{ case(real, pre, _) => math.pow((real - pre), 2)}.mean()
println(s"Test Mean Squared Error = $testMSE")
// AUC
val metrics = new BinaryClassificationMetrics(test_result.map(x => (x._2,x._1)).sortByKey(ascending = true),numBins = 2)
println(s"0-1 label AUC is = ${metrics.areaUnderROC}")
val metrics1 = new BinaryClassificationMetrics(test_result.map(x => (x._3,x._1)).sortByKey(ascending = true),numBins = 2)
println(s"score-label AUC is = ${metrics1.areaUnderROC}")
// 错误率
val error = test_result.filter(x => x._1!=x._2).count().toDouble / test_result.count()
println(s"error is = $error")
// 准确率
val accuracy = test_result.filter(x => x._1==x._2).count().toDouble / test_result.count()
println(s"accuracy is = $accuracy")
}模型保存
def saveModel(model: GradientBoostedTreesModel, model_path: Any): Unit = {
// 保存模型文件 obj
val out_obj = new ObjectOutputStream(new FileOutputStream(model_path+"model.obj"))
out_obj.writeObject(model)
// 保存模型信息
val model_info=new BufferedWriter(new FileWriter(model_path+"model_info.txt"))
model_info.write(model.toDebugString)
model_info.flush()
model_info.close()
// 保存模型权重
val model_weights=new BufferedWriter(new FileWriter(model_path+"model_weights.txt"))
model_weights.write(model.treeWeights.zipWithIndex.map(x=>s"第${x._2+1}棵树的权重是:${x._1}").mkString("\n"))
model_weights.flush()
model_weights.close()
}
模型加载
def getModel(path: String): Option[GradientBoostedTreesModel] = {
try {
val in = new ObjectInputStream(new FileInputStream(path))
val model = Option(in.readObject().asInstanceOf[GradientBoostedTreesModel])
in.close()
println("model load success !")
model
}catch {
case ex: ClassNotFoundException => {
println(ex.printStackTrace())
None
}
case ex: IOException => {
ex.printStackTrace()
None
}
case _: Throwable => throw new Exception
}
}数值预测
def predict(model: GradientBoostedTreesModel,feature:Array[Double]):Double={
val featureScore=Vectors.dense(feature)
val treePredictions = model.trees.map(_.predict(featureScore))
//计算各个树预测值与树权重的点积;计算得到的结果值作为模型计算得到的分数值,用于排序。
val predictScore=blas.ddot(model.numTrees,treePredictions,1,model.treeWeights,1)
// 将森林生成的各个树得到的预测分值进行变形,得到最终用户点击的预估值
val score=Math.pow(1 + Math.pow(Math.E, -2 * predictScore),-1)
score
}Pipeline
Spark ML Pipeline 的出现,是受到了 scikit-learn 项目的启发,并且总结了 MLlib 在处理复杂机器学习问题上的弊端,旨在向用户提供基于 DataFrame 之上的更加高层次的 API 库,以更加方便的构建复杂的机器学习工作流式应用。一个 Pipeline 在结构上会包含一个或多个 PipelineStage,每一个 PipelineStage 都会完成一个任务,如数据集处理转化,模型训练,参数设置或数据预测等,这样的 PipelineStage 在 ML 里按照处理问题类型的不同都有相应的定义和实现。接下来,我们先来了解几个重要概念。
-
DataFrame
相比RDD,DF包含了 schema 信息,更类似传统数据库中的二维表格。它被 ML Pipeline 用来存储源数据。DataFrame 可以被用来保存各种类型的数据,如我们可以把特征向量存储在 DataFrame 的一列中,这样用起来是非常方便的。
-
Transformer
Transformer 中文可以被翻译成转换器,是一个 PipelineStage,实现上也是继承自 PipelineStage 类,主要是用来把 一个 DataFrame 转换成另一个 DataFrame,比如一个模型就是一个 Transformer,因为它可以把 一个不包含预测标签的测试数据集 DataFrame 打上标签转化成另一个包含预测标签的 DataFrame,显然这样的结果集可以被用来做分析结果的可视化。
-
Estimator
Estimator 中文可以被翻译成评估器或适配器,在 Pipeline 里通常是被用来操作 DataFrame 数据并生产一个 Transformer,如一个随机森林算法就是一个 Estimator,因为它可以通过训练特征数据而得到一个随机森林模型。实现上 Estimator 也是继承自 PipelineStage 类。
-
Parameter
Parameter 被用来设置 Transformer 或者 Estimator 的参数。
要构建一个 Pipeline,首先我们需要定义 Pipeline 中的各个 PipelineStage,如指标提取和转换模型训练等。有了这些处理特定问题的 Transformer 和 Estimator,我们就可以按照具体的处理逻辑来有序的组织 PipelineStages 并创建一个 Pipeline,如 :
val pipeline = new Pipeline().setStages(Array(stage1,stage2,stage3,…))然后就可以把训练数据集作为入参并调用 Pipelin 实例的 fit 方法来开始以流的方式来处理源训练数据,这个调用会返回一个 PipelineModel 类实例,进而被用来预测测试数据的标签,它是一个 Transformer。
比如在构建一个GBDT模型的时候,流程是这样的
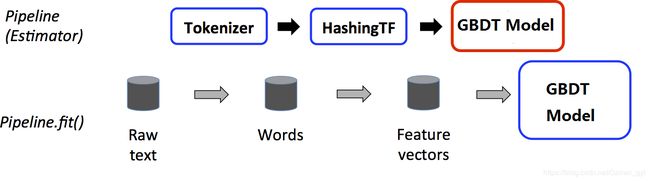
ML包中的GBTs
从Spark 2.0开始,spark.mllib包中基于RDD的API已进入维护模式。 Spark的主要机器学习API现在是spark.ml包中基于DataFrame的API。接下来我们看下ml包中的GBDT(regression)。
加载数据训练模型
// 文件路径
val file = "data/sample_libsvm_data.txt"
val model_path = "output/gbdt_ml/"
// 创建spark对象
val spark = SparkSession.builder().master("local[5]").appName("GBDT_ML_Model_Train").getOrCreate()
Logger.getRootLogger.setLevel(Level.WARN)
// 加载数据,并拆分为训练集和测试集
// http://blog.leanote.com/post/kobeliuziyang/Spark%E8%AF%BB%E5%86%99%E6%95%B0%E6%8D%AE%E9%9B%86
val data = spark.read.format("libsvm").load(file)
data.printSchema()
data.show(10)
val Array(train, test) = data.randomSplit(Array(0.7,0.3))
// 当特征值的不同个数大于4时,才认为该特征为连续型.
val featureindexer = new VectorIndexer().setInputCol("features").setOutputCol("indexedFeatures").setMaxCategories(4).fit(data)
// 创建gbdt model,这里只设置了最大迭代次数,其他也可以通过.setXXX进行设置
val gbdt = new GBTRegressor().setLabelCol("label").setFeaturesCol("indexedFeatures").setMaxIter(10)
// 在pipeline中进行设置
val pipeline = new Pipeline().setStages(Array(featureindexer, gbdt))
// 训练模型
val model = pipeline.fit(train)模型评估
def evaluteModel(predictions: DataFrame) = {
// 效果评估, 默认的支持:"mse", "rmse", "r2", "mae"
val evaluator = new RegressionEvaluator().setLabelCol("label").setPredictionCol("prediction")
val rmse = evaluator.setMetricName("rmse").evaluate(predictions)
println(s"Root Mean Squared Error(RMSE) on test data: $rmse")
val mse = evaluator.setMetricName("mse").evaluate(predictions)
println(s"Mean Squared Error(MSE) on test data: $mse")
val mae = evaluator.setMetricName("mae").evaluate(predictions)
println(s"Mean Absolute Error(MAE) on test data: $mae")
val r2 = evaluator.setMetricName("r2").evaluate(predictions)
println(s"Coefficient of Determination(r2) on test data: $r2")
// supports "areaUnderROC" (default), "areaUnderPR"
val evaluator_binary = new BinaryClassificationEvaluator().setLabelCol("label").setRawPredictionCol("prediction")
val auc = evaluator_binary.setMetricName("areaUnderROC").evaluate(predictions)
println(s"areaUnderROC: $auc")
val apr = evaluator_binary.setMetricName("areaUnderPR").evaluate(predictions)
println(s"areaUnderPR: $apr")
// supports "f1" (default), "weightedPrecision","weightedRecall", "accuracy")
val evaluator_mul = new MulticlassClassificationEvaluator().setLabelCol("label").setPredictionCol("prediction")
val f1 = evaluator_mul.setMetricName("f1").evaluate(predictions)
println(s"f1 is : $f1")
val precision = evaluator_mul.setMetricName("weightedPrecision").evaluate(predictions)
println(s"precision is : $precision")
val recall = evaluator_mul.setMetricName("weightedRecall").evaluate(predictions)
println(s"recall is : $recall")
val accuracy = evaluator_mul.setMetricName("accuracy").evaluate(predictions)
println(s"accuracy is : $accuracy")
}
其余相关代码可参考MLLib中的GBTs
本篇文章中涉及的代码可在github中找到:https://github.com/Thinkgamer/Hadoop-Spark-Learning/tree/master/Spark
