使用手势跟踪玩转谷歌小恐龙游戏 (Playing the Google Chrome's dinosaur game using hand-tracking)

今天我在OpenCV找一些鲁棒/快速的方式来进行手的跟踪。刚开始我将注意力放在了分类器上面,诸如:Haar cascade、Convolutional Neural Networks、SVM 等等。但是不幸的是这些方法有俩个主要的问题是:滑动窗口(sliding window)和 数据集 (dataset)。
-
为了分类图像中的一部分,经常会用到一个常用的方法那就是sliding window(滑动窗口)。一个滑动窗口经常是预先预定好尺寸且不断的在图片中移动,然后该滑动窗口作为分类器的入口。这个方法在计算机视觉中被广泛使用但同时有其缺点,首先是速度慢,然后需要很多的迭代来找到图片中的所有物体。
-
另外一个问题就是当你想实现一个分类器时需要找数据集,同时在训练阶段使用该数据集。OpenCV有
Haar cascade classifier库专门用来做手的检测,但是这个库只是在比较有限的数据集上进行训练,且识别的手需要摆成预定的手势。
在看到上述俩个问题中,需要怎么做?一种可能的方法是使用 histogram backprojection algorithm(直方图反向投影算法)
一. The histogram backprojection algorithm
histogram backprojection algorithm 是 Swain 和 Ballard 在他们的文章 “Color Indexing” 中提出的。如果你没有看我之前关于 histogram intersection 的介绍,最好先浏览下,明白histogram intersection 的概念,因为反向投影 (backprojection)可以认为是 交叉运算(intersection)的补充。使用 Swain 和 Ballard 在其文章提到的术语,我们可以清楚的明白,intersection 回答了“我们需要寻找什么物体”这个问题,然而 backprojection 回答了“在图片中属于我们要寻找的物体的颜色的位置?” 但是,反向投影(backprojection)是怎么工作的呢?给定一张图片的直方图 I I I 和 模型的直方图 M M M,然后我们如下所示定义比例直方图(ratio histogram) R R R :
R i = m i n ( M i I i , 1 ) R_{i}=min(\frac{M_{i}}{I_{i}},1) Ri=min(IiMi,1)
我们同样定义一个函数 h ( c ) h(c) h(c) ,该函数将 ( x , y ) (x,y) (x,y) 位置的像素颜色值 c c c 映射到直方图R索引的值(maps the colour c of the pixel at (x,y) to the value of the histogram R it indexes)。使用Swain 和 Ballard 所用到的行业用于(slang),我们可以说函数 h ( c ) h(c) h(c) 将直方图 R R R 反投影(backprojects)到 输入图片。
紧接着,使用半径为 r r r 的圆形卷积核 D D D 对反向投影后的 B B B 进行卷积。在文章中,作者建议选择 D D D 区域物体所期望的区域(The authors recommend to choose as area of D the expected area subtended by the object.)。如果你希望更多技术的细节,可以看查看原文章original article。因为反投影的过程很难被理解,我已我们画了个简图如下所示:
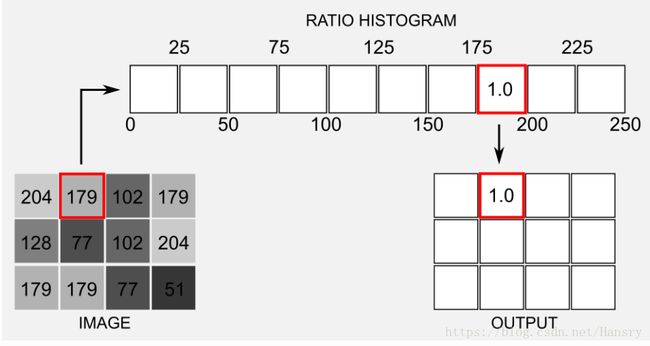
为了简化工作,先考虑单通道灰度图(single channel greyscale image),其中IMAGE代表输入图片灰度图的右上角3x4 的像素。每一个像素的值都在 [0,250] 之间。首先考虑位置为(1,2)的像素,其像素为179。我们使用10bins 的直方图,179落在第八个bin区域中([175,200]),且在这个位置中其值为1.0。 最后我们将1.0这个值赋予输出矩阵(即图片 B B B)对应的位置,即图片 B B B的 (1,2) 的位置。这就是反投影的一个小概括。
二.Implementation in python
让我们开始使用Numpy一步一步的实现这个算法吧。以下的代码只是使用了一维度的直方图(greyscale image),但是很容易可以扩展到多维度直方图中。对于多维度直方图,需要使用方法numpy.historgramdd而不是标准的方法numpy.histogram。在代码中,变量的名字跟Swain和Ballard在他们的文章使用的变量的名字是一样的。首先我们需要一个函数通过**模型直方图(model histogram) ∗ ∗ M **M ∗∗M 和 图片直方图(image histogram) I I I 来得到 比例直方图 (ratio histogram) R R R.
def return_ratio_histogram(M, I):
ones_array = np.ones(I.shape)
R = np.minimum(np.true_divide(M, I), ones_array)
return R
下一步等价于函数 h ( c ) h(c) h(c) ,作用是将输入图片的像素映射到比例直方图R中的值。在这里我假设所有的bin都有相同的范围,且最高的像素值为255,虽然有时候并不是这样子:
def return_backprojected_image(image, R):
indexes = np.true_divide(image.flatten, 255)*R.shape[0]
B = R.astype(int)[indexes]
return B
我们通过调用函数return_backprojected()得到图像 B B B。在下一步我们在反投影得到的图像 B B B使用半径为r的卷积。Numpy并没有实现 2 D 2D 2D的卷积操作,所以我们使用OpenCV函数 cv2.filter2D:
def convolve(B, r):
D = cv2.getStructuringElement(cv2.MORPH_ELLIPSE,(r,r))
cv2.filter2D(B, -1, D, B)
B = np.uint8(B)
cv2.normalize(B, B, 0, 255, cv2.NORM_MINMAX)
return B
从头开始实现这个算法是不必要的,因为OpenCV有一个有用的函数,叫做calcBackProject。我们将使用该函数从下面图像中分离老虎:

import cv2
import numpy as np
#Loading the image and converting to HSV
image = cv2.imread('tiger.jpg')
image_hsv = cv2.cvtColor(image,cv2.COLOR_BGR2HSV)
#I take a subframe of the original image
#corresponding to the fur of the tiger
model_hsv = image_hsv[225:275,625:675]
#Get the model histogram M and Normalise it
M = cv2.calcHist([model_hsv], channels=[0, 1], mask=None,
histSize=[180, 256], ranges=[0, 180, 0, 256] )
M = cv2.normalize(M, alpha=0, beta=255, norm_type=cv2.NORM_MINMAX)
#Backprojection of our original image using the model histogram M
B = cv2.calcBackProject([image_hsv], channels=[0,1], hist=M,
ranges=[0,180,0,256], scale=1)
#Now we can use the function convolve(B, r) we created previously
B = convolve(B, r=5)
#Threshold to clean the image and merging to three-channels
_, thresh = cv2.threshold(B, 50, 255, 0)
B_thresh = cv2.merge((thresh, thresh, thresh))
#Using B_tresh as a mask for a binary AND with the original image
cv2.imwrite('result.jpg', cv2.bitwise_and(image, B_thresh))

我们可以多次使用这个算法来获得更好的结果获得更好的,通过从我们需要找的物体进行不同模型的采样得到不同的模型。在作者deepgaze中,检测多个模型的类放在MultiBackProjectColorDetector,可以通过几行代码就对其进行初始化。MultiBackProjectColorDetector的主要优势在于你可以将多个模型放到一个列表中然后一起输入,并且传递一个模型列表并累积每个过滤器的结果。
import cv2
from deepgaze.color_detection import MultiBackProjectionColorDetector
#Loading the main image
img = cv2.imread('tiger.jpg')
#Creating a python list and appending the model-templates
#In this case the list are preprocessed images but you
#can take subframes from the original image
template_list=list()
template_list.append(cv2.imread('model_1.jpg')) #Load the image
template_list.append(cv2.imread('model_2.jpg')) #Load the image
template_list.append(cv2.imread('model_3.jpg')) #Load the image
template_list.append(cv2.imread('model_4.jpg')) #Load the image
template_list.append(cv2.imread('model_5.jpg')) #Load the image
#Defining the deepgaze color detector object
my_back_detector = MultiBackProjectionColorDetector()
my_back_detector.setTemplateList(template_list) #Set the template
#Return the image filterd, it applies the backprojection,
#the convolution and the mask all at once
img_filtered = my_back_detector.returnFiltered(img,
morph_opening=True, blur=True,
kernel_size=3, iterations=2)
cv2.imwrite("result.jpg", img_filtered)

可以看到我们得到了比较好的结果。拥有多个模板使得模型对物体有一个完整的表达。但是这种方法会有一些问题,引起多个模型意味着引起更多的噪声。实际上在上面俩种方式中,第二种方式引起了更多的噪声。智能地使用变形操作(morphing operations)可以减弱问题,从这个意义上说,内核大小的选择是至关重要的。最终版本的代码在 deepgaze repository。
二.Google Chrome’s dinosaur game
当你使用Google Chrome浏览器的时候,会有一个小恐龙在断网的时候出现。为了玩这个游戏,我们不需要故意断网,这里有一个在线的版本。最近作者在 youtube上面看到由Ivan Seidel等人写的用一个用遗传算法做的用来自动恐龙游戏的算法且达到了很高的效果。然后作者就想到了这个好玩的东西:手向上移动(Hand Up) -> 键盘向上的键按下(Key_up), 手向下移动 Hand Down -> 键盘向下的键按下(Key_Down), 在 Linux 系统中,我们需要使用 evdev 来跟键盘进行交互,该库是Linux 内核的一部分。举个例子:如果你想按下Key_Down,可以使用以下代码:
import time
from evdev import UInput, ecodes as e
ui = UInput()
ui.write(e.EV_KEY, e.KEY_DOWN, 1) #press the KEY_DOWN button
time.sleep(1)
ui.write(e.EV_KEY, e.KEY_DOWN, 0) #release the KEY_DOWN button
记住,因为某些考虑到安全的原因,只有当你是超级用户的时候才能使用evdev。作者在deepgaze中写了俩个类,分别为MultiBackProjectionColorDetector 和 BinaryMaskAnalyser。使用多反向投影(multi-backprojection)得到了mask of the hand ,且通过使用函数returnMaxAreaCenter(),得到了手的中心。但中心点高于或低于预先给定的水平的时候,通过evdev就相当于产生KEY_UP或者 KEP_DOWN的效果。
原文链接:https://mpatacchiola.github.io/blog/2016/12/01/playing-the-google-chrome-dinosaur-game-with-your-hand.html