MiniGUI 体系结构之三——逻辑字体以及多字体和多字符集实现
简介: 本文是 MiniGUI 体系结构系列文章的第三篇,重点介绍 MiniGUI 的逻辑字体支持,主要内容涉及 MiniGUI 中以面向对象技术为基础构建的多字体和多字符集支持,并举例说明了如何在 MiniGUI 中实现对新字符集和新字体的支持。
1 引言
我们在介绍 MiniGUI 体系结构的第一篇文章中提到,MiniGUI 采用了面向对象的技术实现了 GAL、IAL 以及多字体和多字符集的支持。字体和字符集的支持,对任何一个 GUI 系统来讲都是不可缺少的。不过,各种 GUI 在实现多字体和多字符集的支持时,采用不同的策略。比如,对多字符集的支持,QT/Embedded采用 UNICODE 为基础实现,这种方法是目前比较常用的方法,是一种适合于通用系统的解决方案。然而,这种方法带来许多问题,其中最主要就是 UNICODE 和其他字符集之间的转换码表会大大增加 GUI 系统的尺寸。这对某些嵌入式系统来讲是不能接受的。
MiniGUI 在内部并没有采用 UNICODE 为基础实现多字符集的支持。MiniGUI的策略是,对某个特定的字符集,在内部使用和该字符集完全一致的内码表示。然后,通过一系列抽象的接口,提供对某个特定字符集文本的一致分析接口。该接口既可以用于对字体模块,也可以用来实现多字节字符串的分析功能。如果要增加对某个字符集的支持,只需要实现该字符集的接口即可。到目前为止,MiniGUI 已经实现了 ISO8859-x 的单字节字符集支持,以及 GB2312、BIG5、EUCKR、UJIS 等多字节字符集的支持。
和字符集类似,MiniGUI 也针对字体定义了一系列抽象接口,如果要增加对某种字体的支持,只需实现该字体类型的接口即可。到目前为止,MiniGUI 已经实现了对 RBF 和 VBF 字体(这是 MiniGUI 定义的两种光栅字体格式)、TrueType 和 Adobe Type1 字体等的支持。
在多字体和多字符集的抽象接口之上,MiniGUI 通过逻辑字体为应用程序提供了一致的接口。
本文重点介绍 MiniGUI 的逻辑字体、多字体和多字符集的实现,并以 EUCKR(韩文)字符集和 Adobe Type1 字体为例,说明如何在 MiniGUI 中实现一种新的字符集支持和新的字体类型支持。
2 逻辑字体、设备字体以及字符集之间的关系
在 MiniGUI 中,每个逻辑字体至少由一个单字节的设备字体组成。设备字体是直接与底层字体相关联的数据结构。每个设备字体有一个操作集(即 font_ops),其中包含了 get_char_width、get_char_bitmap 等抽象接口。每个 MiniGUI 所支持的字体类型,比如等宽光栅字体(RBF)、变宽光栅字体(VBF)、TrueType 字体、Adobe Type1 字体等均对应一组字体操作集。通过这个字体操作集,我们就可以从相应的字体文件中获得某个字符的点阵(对光栅字体而言)或者轮廓(对矢量字体而言)。之后,MiniGUI 上层的绘图函数就可以将这些点阵输出到屏幕上,最终就可以看到显示在屏幕上的文字。
图 1 给出了逻辑字体、设备字体以及字符集之间的关系。
图 1 逻辑字体以及相关数据结构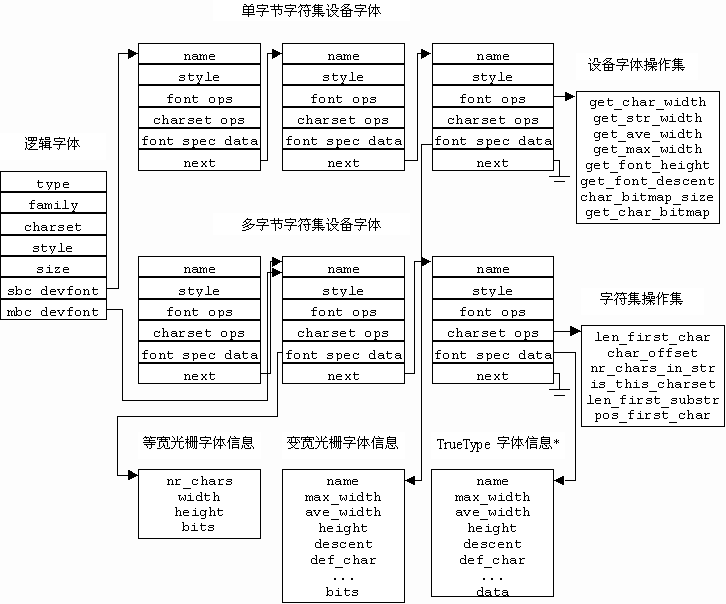
在设备字体结构中,还有一个字符集操作集(即 charset_ops),其中包含了 len_first_char、char_offset、len_first_substr 等抽象接口。每个 MiniGUI 所支持的字符集,比如 ISO8859-x、GB2312、BIG5 等字符集均对应一组字符集操作集。通过这个字符集操作集,我们就可以对某个多种字符集混合的字符串进行文本分析。比如在“ABC中文”这个字符串中,头三个字符是属于 ISO8859 的字符,而“中文”是属于 GB2312 的字符。通过调用这两个字符集操作集中的函数,我们就可以了解该字符串中哪些字符是属于 ISO8859 的字符,哪些字符是属于 GB2312 的字符,甚至可以进行更加复杂的分析。比如,MiniGUI 中的 GetFirstWord 函数可以从这种字符串中获得第一个单词。比如“ABC DEF 中文”字符串中的第一个单词是“ABC”,而第二个单词是“DEF”,第三个单词和第四个单词分别是“中”和“文”。该函数的实现如下:
int GUIAPI GetFirstWord (PLOGFONT log_font, const char* mstr, int len,
WORDINFO* word_info)
{
DEVFONT* sbc_devfont = log_font->sbc_devfont;
DEVFONT* mbc_devfont = log_font->mbc_devfont;
if (mbc_devfont) {
int mbc_pos;
mbc_pos = (*mbc_devfont->charset_ops->pos_first_char) (mstr, len);
if (mbc_pos == 0) {
len = (*mbc_devfont->charset_ops->len_first_substr) (mstr, len);
(*mbc_devfont->charset_ops->get_next_word) (mstr, len, word_info);
return word_info->len + word_info->nr_delimiters;
}
else if (mbc_pos > 0)
len = mbc_pos;
}
(*sbc_devfont->charset_ops->get_next_word) (mstr, len, word_info);
return word_info->len + word_info->nr_delimiters;
}
|
该函数首先判断该逻辑字体是否包含多字节设备字体(mbc_devfont是否为空),如果是,则调用多字节字符集对应的操作函数 pos_first_char、len_first_substr、get_next_word 等函数获得第一个单词信息,并填充 word_info 结构。如果该逻辑字体只包含单字节设备字体,则直接调用单字节字符集对应的操作函数 get_next_word。一般而言,在 GetFirstWord 等函数中,我们首先要进行多字节字符集的某些判断,比如 pos_first_char 返回的是字符串中属于该字符集的第一个字符的位置。如果返回值不为零,表明第一个字符是单字节字符;如果为零,才会调用其他函数进行操作。
有了这样的逻辑字体、设备字体和字符集结构定义,当我们需要新添加一种字符集或者字体支持时,只需按照我们的字体操作集和字符集操作集定义对应的新操作集结构即可,而对上层程序没有任何影响。
3 MiniGUI 中的字符集支持
3.1 字符集操作集
在 MiniGUI 中,每个特定的字符集由对应的字符集操作集来表示。字符集操作集的定义如下(include/gdi.h。前面的数字表示在该文件中的行数,下同):
250 typedef struct _CHARSETOPS
251 {
252 int nr_chars; // 该字符集中字符的个数
253 int bytes_per_char; // 每个字符的平均字节数
254 int bytes_maxlen_char; // 字符的最大字节数
255 const char* name; // 字符集名称
256 char def_char [MAX_LEN_MCHAR]; // 默认字符
257
258 int (*len_first_char) (const unsigned char* mstr, int mstrlen);
259 int (*char_offset) (const unsigned char* mchar);
260
261 int (*nr_chars_in_str) (const unsigned char* mstr, int mstrlen);
262
263 int (*is_this_charset) (const unsigned char* charset);
264
265 int (*len_first_substr) (const unsigned char* mstr, int mstrlen);
266 const unsigned char* (*get_next_word) (const unsigned char* mstr,
267 int strlen, WORDINFO* word_info);
268
269 int (*pos_first_char) (const unsigned char* mstr, int mstrlen);
270
271 #ifndef _LITE_VERSION
272 unsigned short (*conv_to_uc16) (const unsigned char* mchar, int len);
273 #endif /* !LITE_VERSION */
274 } CHARSETOPS;
|
其中,前几个字段(nr_chars、bytes_per_char、bytes_maxlen_char、name、def_char 等)表示了该字符集的一些基本信息,具体含义参见注释。这里需要对 bytes_maxlen_char 和 def_chat 作进一步解释:
- bytes_maxlen_char 用来表示该字符集中字符的最长字节数。通常情况下,一个字符集中的每个字符的长度一般是定长的,但是也有许多例外,比如在 GB18303、UNICODE 等字符集中,字符的最长字节数可能超过 4 字节。
- def_char 用来表示该字符集中的默认字符。该字段主要和字体配合使用。当某个针对该字符集的字体中缺少一些字符的定义时,就需要用默认字体替代这些缺少的字符。
在上述字符集的操作集定义中,后几个字段定义为函数指针,它们均由逻辑字体接口用来进行文本分析:
- len_first_char 返回多字节字符串中第一个属于该字符集的字符的长度。若不属于该字符集,则返回 0。
- char_offset 返回某个字符在该字符集中的位置。该信息可以由设备字体使用,用来从一个字体文件中获取该字符对应的宽度或点阵。
- nr_chars_in_str 计算字符串中属于该字符集的字符个数并返回。注意,传入的字符串必须均为该字符集字符。
- is_this_charset 判断给定的用来表示字符集的名称是否指该字符集。因为对某种特定的字符集,其名称不一定和 name 字段所定义的名称匹配。比如,对 GB2312 字符集,就可能有 gb2312-1980.0、GB2312_80 等各种不同的名称。该函数可以帮助正确判断一个名称是否指该字符集。
- len_first_substr 返回某个多字节字符串中属于该字符集的子字符串长度。如果第一个字符不属于该字符集,则返回为 0。
- get_next_word 返回多字节字符串中属于该字符集的字符串中下一个单词的信息。对欧美语言来说,单词之间由空格、标点符号、制表符等相隔;对亚洲语言来说,单词通常定义为字符。
- pos_first_char 该函数返回多字节字符串中属于该字符集的第一个字符的位置。
- conv_to_uc16 该函数将某个属于该字符集的字符,转换为 UNICODE 的 16 位内码。该函数主要用来从 TrueType 字体中获得字符的轮廓信息。因为 TrueType 字体使用 UNICODE 定位字符,所以需要这个函数完成特定字符集内码到 UNICODE 内码的转换。由于 MiniGUI-Lite 版本尚不支持 TrueType 字体,所以该函数在 MiniGUI-Lite 版本中无需定义。
在 src/font/charset.c 中,定义了系统支持的所有字符集操作集,并由函数 GetCharsetOps 返回某个字符集名称对应的字符集操作集(src/font/charset.c):
716 static CHARSETOPS* Charsets [] =
717 {
718 &CharsetOps_iso8859_1,
719 &CharsetOps_iso8859_5,
720 #ifdef _GB_SUPPORT
721 &CharsetOps_gb2312,
722 #endif
723 #ifdef _BIG5_SUPPORT
724 &CharsetOps_big5,
725 #endif
726 #ifdef _EUCKR_SUPPORT
727 &CharsetOps_euckr,
728 #endif
729 #ifdef _UJIS_SUPPORT
730 &CharsetOps_ujis
731 #endif
732 };
733
734 #define NR_CHARSETS (sizeof(Charsets)/sizeof(CHARSETOPS*))
735
736 CHARSETOPS* GetCharsetOps (const char* charset_name)
737 {
738 int i;
739
740 for (i = 0; i < NR_CHARSETS; i++) {
741 if ((*Charsets [i]->is_this_charset) (charset_name) == 0)
742 return Charsets [i];
743 }
744
745 return NULL;
746 }
747
|
3.2 新字符集的实现举例
如果我们需要定义一种新的字符集支持时,只需在该文件中添加相应的操作集函数以及对应的操作集结构定义即可,比如,对 EUCKR 字符集的支持定义如下(src/font/charset.c):
468 #ifdef _EUCKR_SUPPORT
469 /************************* EUCKR Specific Operations ************************/
470 static int euckr_len_first_char (const unsigned char* mstr, int len)
471 {
472 unsigned char ch1;
473 unsigned char ch2;
474
475 if (len < 2) return 0;
476
477 ch1 = mstr [0];
478 if (ch1 == '\0')
479 return 0;
480
481 ch2 = mstr [1];
482 if (ch1 >= 0xA1 && ch1 <= 0xFE && ch2 >= 0xA1 && ch2 <= 0xFE)
483 return 2;
484
485 return 0;
486 }
487
488 static int euckr_char_offset (const unsigned char* mchar)
489 {
490 if(mchar [0] > 0xAD)
491 return ((mchar [0] - 0xA4) * 94 + mchar [1] - 0xA1 - 0x8E);
492 else
493 return ((mchar [0] - 0xA1) * 94 + mchar [1] - 0xA1 - 0x8E);
494 }
495
496 static int euckr_is_this_charset (const unsigned char* charset)
497 {
498 int i;
499 char name [LEN_FONT_NAME + 1];
500
501 for (i = 0; i < LEN_FONT_NAME + 1; i++) {
502 if (charset [i] == '\0')
503 break;
504 name [i] = toupper (charset [i]);
505 }
506 name [i] = '\0';
507
508 if (strstr (name, "EUCKR") )
509 return 0;
510
511 return 1;
512 }
513
514 static int euckr_len_first_substr (const unsigned char* mstr, int mstrlen)
515 {
516 unsigned char ch1;
517 unsigned char ch2;
518 int i, left;
519 int sub_len = 0;
520
521 left = mstrlen;
522 for (i = 0; i < mstrlen; i += 2) {
523 if (left < 2) return sub_len;
524
525 ch1 = mstr [i];
526 if (ch1 == '\0') return sub_len;
527
528 ch2 = mstr [i + 1];
529 if (ch1 >= 0xA1 && ch1 <= 0xFE && ch2 >= 0xA1 && ch2 <= 0xFE)
530 sub_len += 2;
531 else
532 return sub_len;
533
534 left -= 2;
535 }
536
537 return sub_len;
538 }
539
540 static int euckr_pos_first_char (const unsigned char* mstr, int mstrlen)
541 {
542 unsigned char ch1;
543 unsigned char ch2;
544 int i, left;
545
546 i = 0;
547 left = mstrlen;
548 while (left) {
549 if (left < 2) return -1;
550
551 ch1 = mstr [i];
552 if (ch1 == '\0') return -1;
553
554 ch2 = mstr [i + 1];
555 if (ch1 >= 0xA1 && ch1 <= 0xFE && ch2 >= 0xA1 && ch2 <= 0xFE)
556 return i;
557
558 i += 1;
559 left -= 1;
560 }
561
562 return -1;
563 }
564
565 #ifndef _LITE_VERSION
566 static unsigned short euckr_conv_to_uc16 (const unsigned char* mchar, int len)
567 {
568 return '?';
569 }
570 #endif
571
572 static CHARSETOPS CharsetOps_euckr = {
573 8836,
574 2,
575 2,
576 FONT_CHARSET_EUCKR,
577 {'\xA1', '\xA1'},
578 euckr_len_first_char,
579 euckr_char_offset,
580 db_nr_chars_in_str,
581 euckr_is_this_charset,
582 euckr_len_first_substr,
583 db_get_next_word,
584 euckr_pos_first_char,
585 #ifndef _LITE_VERSION
586 euckr_conv_to_uc16
587 #endif
588 };
589 /************************* End of EUCKR *************************************/
590 #endif /* _EUCKR_SUPPORT */
|
4 MiniGUI 中的字体支持
4.1 设备字体
在 MiniGUI 中,设备字体定义如下(include/gdi.h):
319 struct _DEVFONT
320 {
321 char name [LEN_DEVFONT_NAME + 1];
322 DWORD style;
323 FONTOPS* font_ops;
324 CHARSETOPS* charset_ops;
325 struct _DEVFONT* sbc_next;
326 struct _DEVFONT* mbc_next;
327 void* data;
328 };
|
其中各字段说明如下:
- name:该设备字体的名称。MiniGUI 中设备字体的名称格式如下:
|