北理工嵩天教授-Python网络爬虫与信息提取课程笔记
BeautifulSoup:

信息标记形式:
 XML:尖括号+标签的表达形式
XML:尖括号+标签的表达形式


JASON有类型的键值对

 XML表达一个人的身份信息的形式(有效信息比例不高 大多被标签占据)
XML表达一个人的身份信息的形式(有效信息比例不高 大多被标签占据)

JSON(不要漏掉双引号)

深刻比较:XML最早 可扩展性好 但比较繁琐
Json 信息有类型 适合程序处理
YAML 信息无类型 文本信息比例高 可读性强
XML应用于INTERNET上的信息与传递
JSON能够被程序直接运行 适合应用于云端和节点的信息通信 无法体现注释
YAML 各种系统的配置文件 有注释 易读
信息提取的一般方法:
方法一:完整解析信息的标记形式再提取关键信息
需要标记解析器; 优点:信心解析准确 缺点:解析繁琐,慢
方法二:无视标记形式,直接搜索关键信息
即对信息的文本查找函数
融合方法:结合形式解析和搜索方法 提取关键信息
注意:爬取到的网页使用X.encoding = X.apparent_encoding 时,右边的步骤会花费很多时间解析网页来获得编码,如果我们已知编码,可以省略这一步,直接把编码赋给左侧,.
BeautifulSoup库的FIND_ALL函数

查找一个或者两个参数的配置如下; 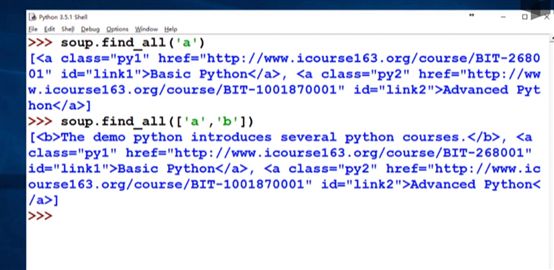 可以看出查找A和B时使用的列表类型,如果要查找所有标签 则直接输入True,要查找某个字母开头的所有信息 则可以使用正则表达式 re.compile
可以看出查找A和B时使用的列表类型,如果要查找所有标签 则直接输入True,要查找某个字母开头的所有信息 则可以使用正则表达式 re.compile
查找P标签中包括course的相关信息

Recursive: 是否搜索全部子孙,默认True
Find_all函数的简写
Find_all函数的扩展: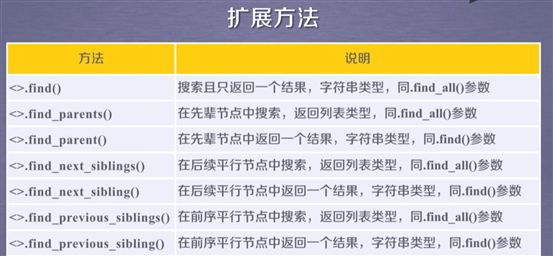
打印结果时长度不一致: 

正则表达式的编译:
 正则表达式操作符
正则表达式操作符


匹配IP地址: 注意:{1,3}即表示长度为1到3
注意:{1,3}即表示长度为1到3

最终结果: ![]()
RE库: 
Raw String: 原生字符串,也即不包括转义符的字符串.

Re.research

Re.match
注意: 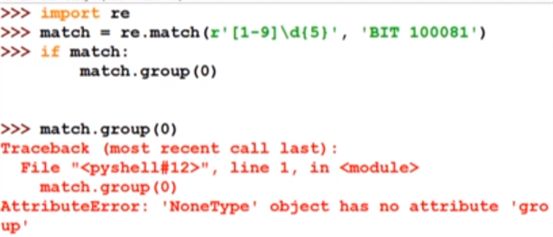
这里返回没有类型,说明match对象是空的,原因是给定的BIT 10081字符串的开头并不是邮政编码,而Match方法是要从字符串的开始进行匹配的.
Re.findall
Re.split

Re.finditer

Re.sub
![]()
Re库的等价用法:
Match对象: 

使用方法:
Re库的匹配方法:


Scrapy框架
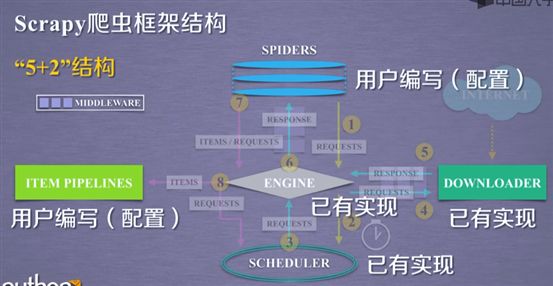
Scheduler:负责调度多种任务请求,发送真实的要爬取的URL链接.
“5+2”:2 是指图中的两个中间件(downloader middleware),5如图所示. Scrapy爬取的3条技术路径也如图所示.
Engine:框架核心,控制所有模块之间的数据流.根据条件出发请求.不需要用户配置
Downloader:获得请求并向网络提交请求,获得页面
Spiders: 
Item pipelines: 

Downloader middleware:

Spider Middleware:

Scrapy vs Requests:

对于最后一点,可通过扩展额外的库来解决.

分析:
1. 若要批量爬取大量网页,建议使用Scrapy库.
2. Scrapy库基于异步结构设计,因此可以同时向多个网站发起请求.注意:对于一些反爬技术成熟的网站,爬取速度过快反而可能导致被反爬.
3. 如果要定制自己的爬虫框架,那么requests>scrapy(它的5+2结构相比之下不是那么灵活)
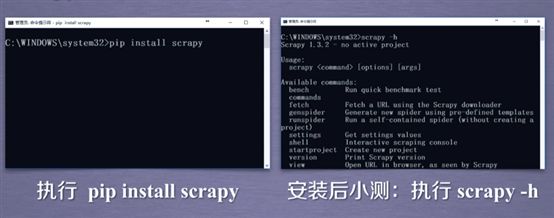
Scrapy常用命令
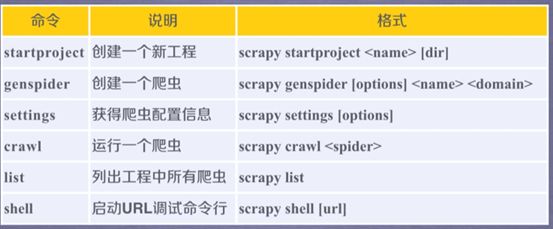
注:一个project下可以有多个爬虫

Scrapy实例:
在C盘pycodes目录下创建一个名为python123demo的工程: 
产生各文件和文件夹的作用:
Scrapy.cfg 为了把爬虫部署在服务器上而配置接口的文件,本机爬虫不需要配置. 

生成一个spider爬虫;
![]()
这样就在名为python123demo的子目录的spiders目录下下生成了一个名为demo.py的爬虫文件,并且已经配置了爬取的网站.我们也可以手工生成这个文件

分析代码:类必须继承于scrapy.Spider类 allowed_domains:爬虫只能爬取该域名下的页面
Start_urls:爬取网页的列表.而parse()
![]()
修改demo.py的代码来爬取https://www.python123.io/ws/demo.html这个网页并保存:

执行爬虫:
![]()
获得的网页会存储在python123demo父目录下
Demo.py有两个等价版本:

要更好地了解各项含义以及scrapy的框架,我们需要了解yield关键字:


Scrapy爬虫的数据类型:

其中 Request类

![]()
Scrapy类的方法:

其中 headers用来定义http请求的头部
Meta在互联网请求时没有用
Response类:

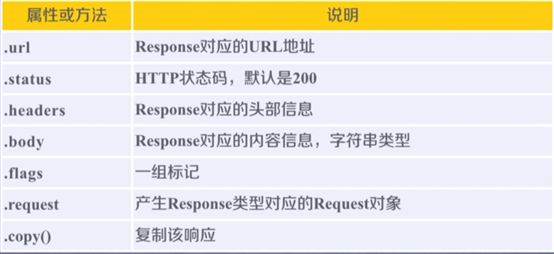
Item类:

Scrapy爬虫提取信息的方法;
 这些方法都作用在Spider模块下.
这些方法都作用在Spider模块下.
Css Selector的使用方法:
