数据结构基础入门
简单地说,数据结构是以某种特定的布局方式存储数据的容器。这种“布局方式”决定了数据结构对于某些操作是高效的,而对于其他操作则是低效的。首先我们需要理解各种数据结构,才能在处理实际问题时选取最合适的数据结构。
首先列出一些最常见的数据结构,我们将逐一说明:
- 数组
- 栈
- 队列
- 链表
- 树
- 图
- 字典树(这是一种高效的树形结构,但值得单独说明)
- 散列表(哈希表)
主要基于jdk8, 可能会有些特性与jdk7之前不相同, 例如LinkedList LinkedHashMap中的双向列表不再是回环的,HashMap中的单链表是尾插, 而不是头插入等等。
【1】数组
数组是最简单、也是使用最广泛的数据结构。栈、队列等其他数据结构均由数组演变而来。下图是一个包含元素(1,2,3和4)的简单数组,数组长度为4。
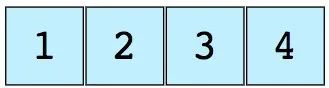
每个数据元素都关联一个正数值,我们称之为索引,它表明数组中每个元素所在的位置。大部分语言将初始索引定义为零 index=0。
以下是数组的两种类型:
- 一维数组(如上所示)
- 多维数组(数组的数组)
① 数组的基本操作
- Insert——在指定索引位置插入一个元素
- Get——返回指定索引位置的元素
- Delete——删除指定索引位置的元素
- Size——得到数组所有元素的数量
② 面试中关于数组的常见问题:
- 寻找数组中第二小的元素
- 找到数组中第一个不重复出现的整数
- 合并两个有序数组
- 重新排列数组中的正值和负值
【2】栈
著名的撤销操作几乎遍布任意一个应用。但你有没有思考过它是如何工作的呢?这个问题的解决思路是按照将最后的状态排列在先的顺序,在内存中存储历史工作状态(当然,它会受限于一定的数量)。有了栈,这就变得非常方便了。
经典的数据结构, 底层也是数组, 继承自Vector, 先进后出FILO, 默认new Stack()容量为10, 超出自动扩容。
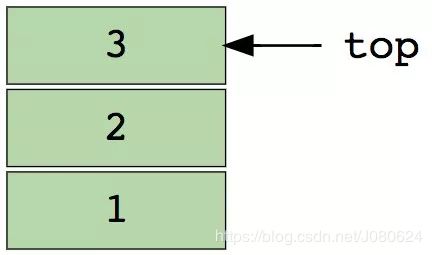
可以把栈想象成一列垂直堆放的书。为了拿到中间的书,你需要移除放置在这上面的所有书。这就是LIFO(后进先出)的工作原理。
下图是包含三个数据元素(1,2和3)的栈,其中顶部的3将被最先移除:
① 栈的基本操作
- Push——在顶部插入一个元素-入栈/压栈

- Pop——返回并移除栈顶元素-出栈

- isEmpty——如果栈为空,则返回true
- Top——返回顶部元素,但并不移除它
② 面试中关于栈的常见问题
- 使用栈计算后缀表达式
- 对栈的元素进行排序
- 判断表达式是否括号平衡
③ 后缀表达式
Stack的一个典型应用就是计算表达式如 9 + (3 - 1) * 3 + 10 / 2, 计算机将中缀表达式转为后缀表达式, 再对后缀表达式进行计算.
中缀转后缀
- 数字直接输出
- 栈为空时,遇到运算符,直接入栈
- 遇到左括号, 将其入栈
- 遇到右括号, 执行出栈操作,并将出栈的元素输出,直到弹出栈的是左括号,左括号不输出。
- 遇到运算符(加减乘除):弹出所有优先级大于或者等于该运算符的栈顶元素,然后将该运算符入栈
- 最终将栈中的元素依次出栈,输出。

计算后缀表达
- 遇到数字时,将数字压入堆栈
- 遇到运算符时,弹出栈顶的两个数,用运算符对它们做相应的计算, 并将结果入栈
- 重复上述过程直到表达式最右端
- 运算得出的值即为表达式的结果

【3】队列
与栈相似,队列是另一种顺序存储元素的线性数据结构。栈与队列的最大差别在于栈是LIFO(后进先出),而队列是FIFO,即先进先出。Stack的删除与添加都在队尾进行, 而Queue删除在队头, 添加在队尾。
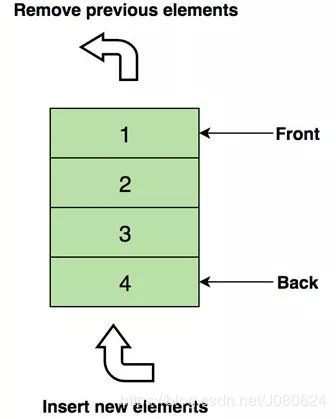
一个完美的队列现实例子:售票亭排队队伍。如果有新人加入,他需要到队尾去排队,而非队首——排在前面的人会先拿到票,然后离开队伍。
下图是包含四个元素(1,2,3和4)的队列,其中在顶部的1将被最先移除:
ArrayBlockingQueue,生产消费者中常用的阻塞有界队列, FIFO。
put(E)
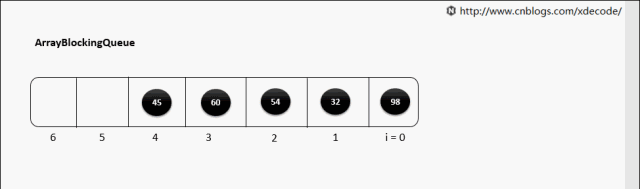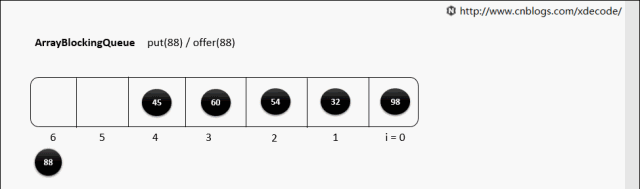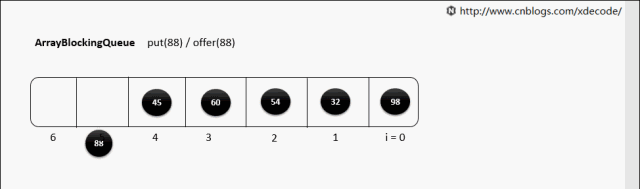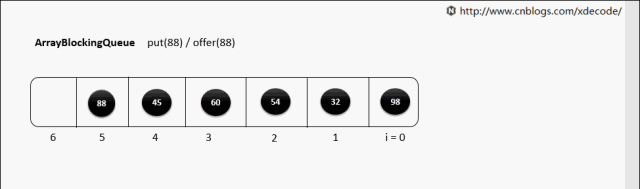
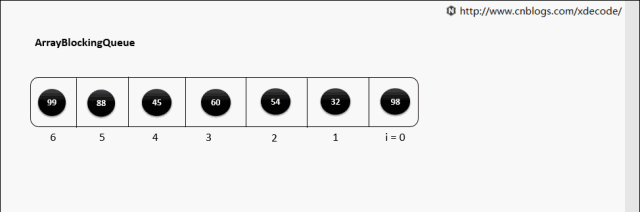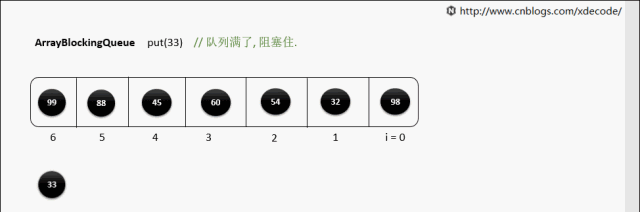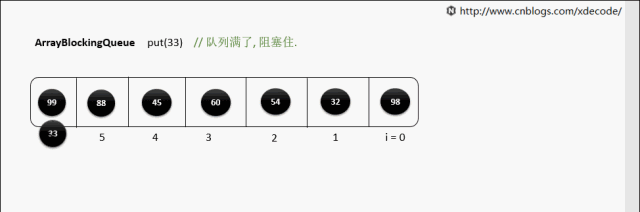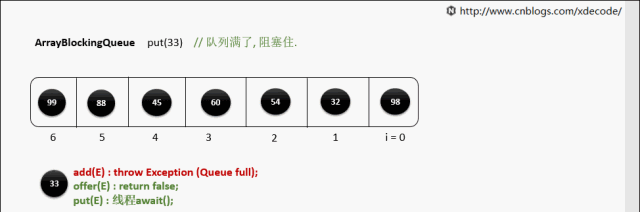
put(E) 队列满了
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == items.length)
notFull.await();//阻塞等待
enqueue(e);
} finally {
lock.unlock();
}
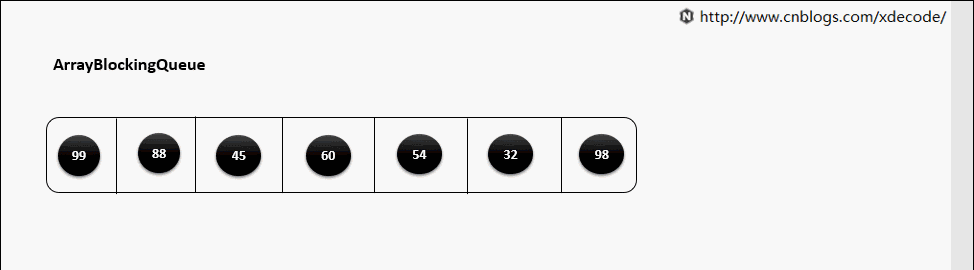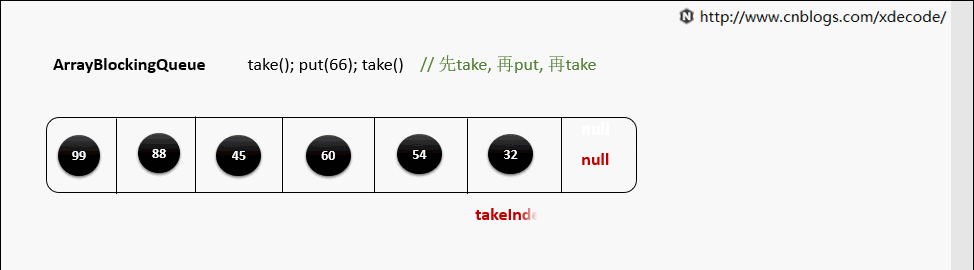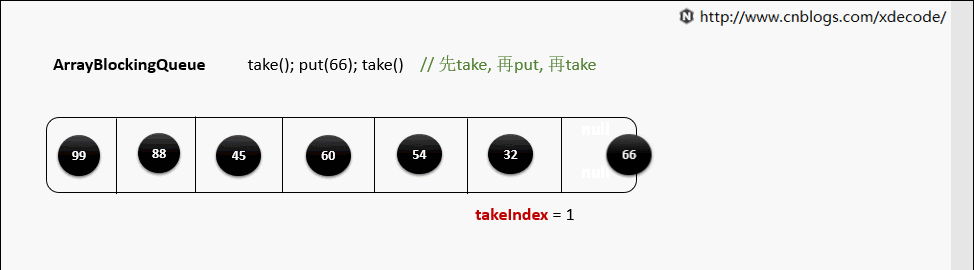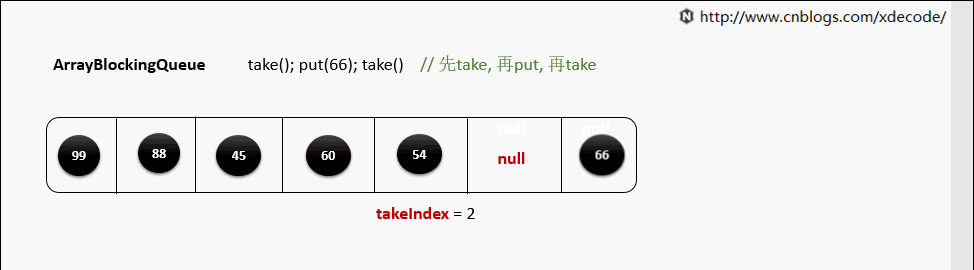
take()
当元素被取出后, 并没有对数组后面的元素位移, 而是更新takeIndex来指向下一个元素.
takeIndex是一个环形的增长, 当移动到队列尾部时, 会指向0, 再次循环。
private E dequeue() {
// assert lock.getHoldCount() == 1;
// assert items[takeIndex] != null;
final Object[] items = this.items;
@SuppressWarnings("unchecked")
E x = (E) items[takeIndex];
items[takeIndex] = null;
if (++takeIndex == items.length)
takeIndex = 0;
count--;
if (itrs != null)
itrs.elementDequeued();
notFull.signal();
return x;
}
队列的基本操作
- Enqueue() —— 在队列尾部插入元素
- Dequeue() ——移除队列头部的元素
- isEmpty()——如果队列为空,则返回true
- Top() ——返回队列的第一个元素
面试中关于队列的常见问题
- 使用队列表示栈
- 对队列的前k个元素倒序
- 使用队列生成从1到n的二进制数
【4】链表
链表是另一个重要的线性数据结构,乍一看可能有点像数组,但在内存分配、内部结构以及数据插入和删除的基本操作方面均有所不同。
链表就像一个节点链,其中每个节点包含着数据和指向后续节点的指针。 链表还包含一个头指针,它指向链表的第一个元素,但当列表为空时,它指向null或无具体内容。
链表一般用于实现文件系统、哈希表和邻接表。这是链表内部结构的展示:

链表包括以下类型:
- 单链表(单向)
- 双向链表(双向)
链表的基本操作:
- InsertAtEnd - 在链表的末尾插入指定元素
- InsertAtHead - 在链接列表的开头/头部插入指定元素
- Delete - 从链接列表中删除指定元素
- DeleteAtHead - 删除链接列表的第一个元素
- Search - 从链表中返回指定元素
- isEmpty - 如果链表为空,则返回true
面试中关于链表的常见问题
- 反转链表
- 检测链表中的循环
- 返回链表倒数第N个节点
- 删除链表中的重复项
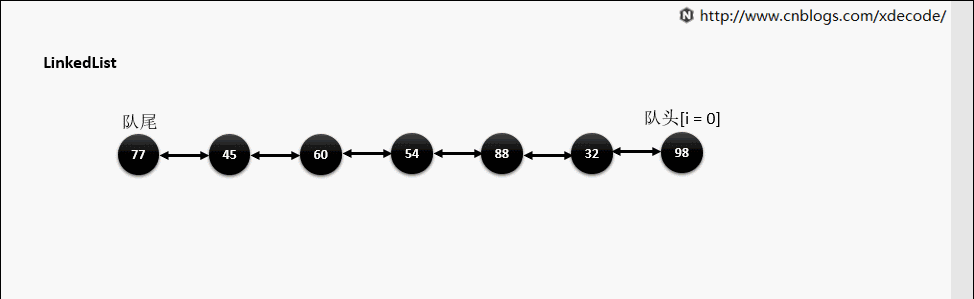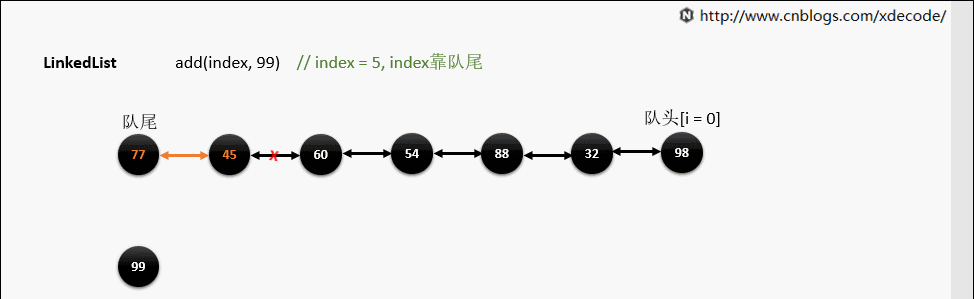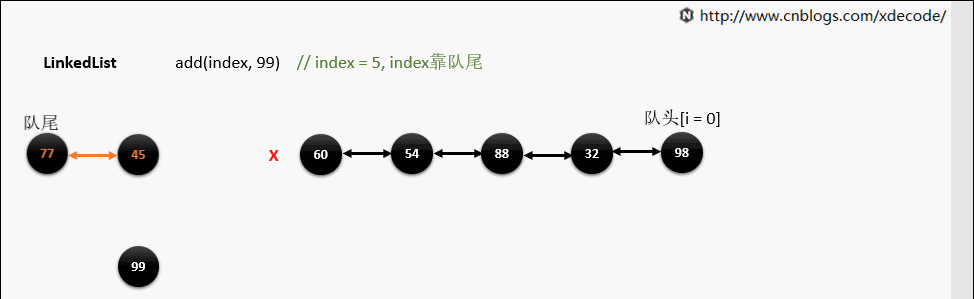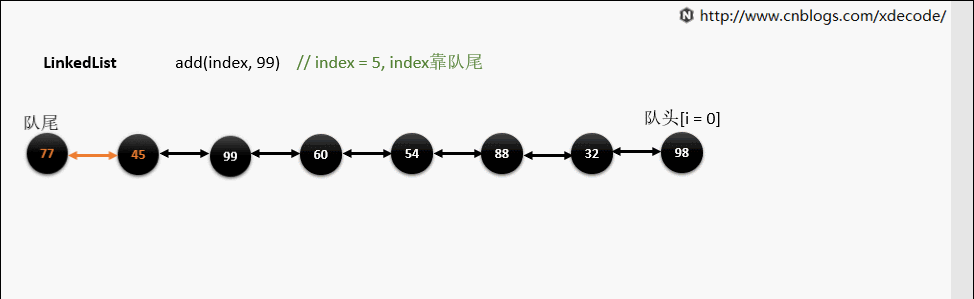
LinkedList
经典的双向链表结构, 适用于乱序插入, 删除。指定序列操作则性能不如ArrayList, 这也是其数据结构决定的。
add(E) / addLast(E)
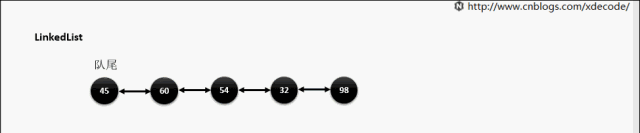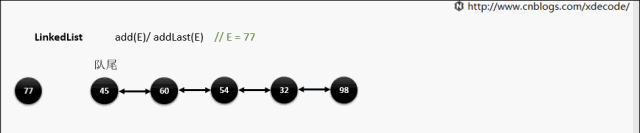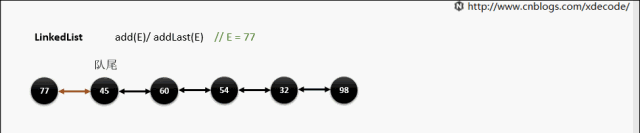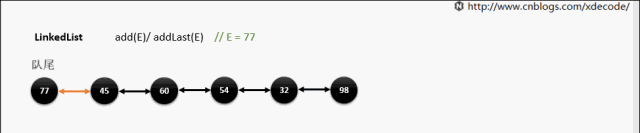
add(index, E)
这边有个小的优化, 他会先判断index是靠近队头还是队尾, 来确定从哪个方向遍历链入。
if (index < (size >> 1)) {
//如果小于size/2,则表示从队头插入
Node x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
靠队头
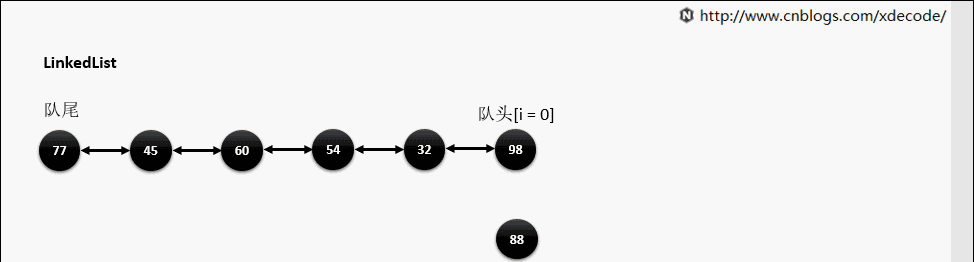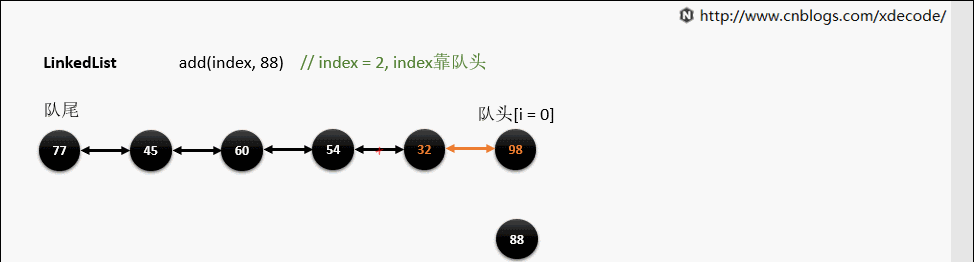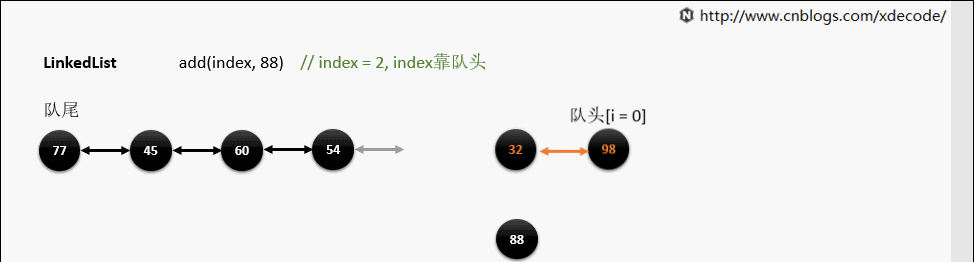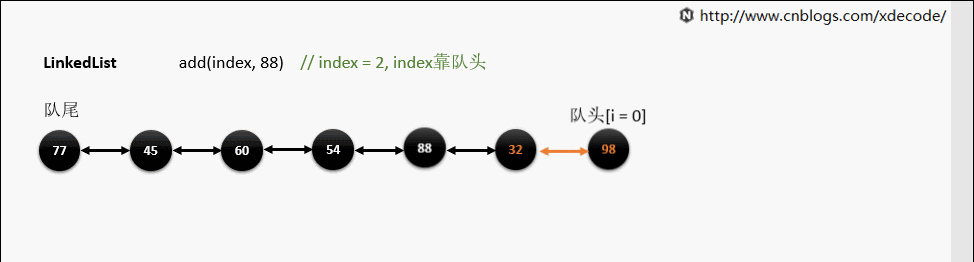
靠队尾
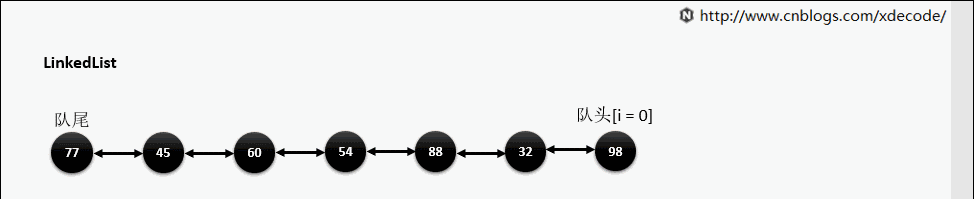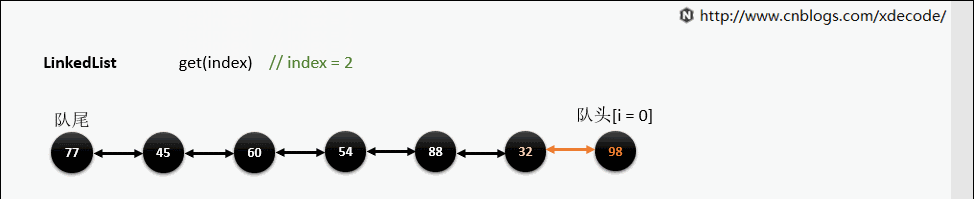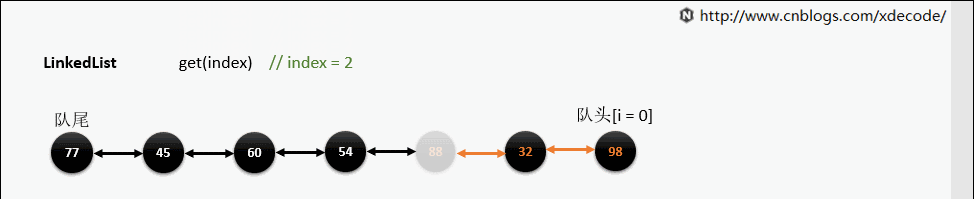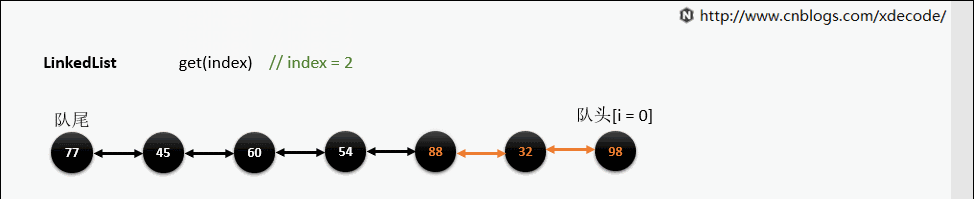
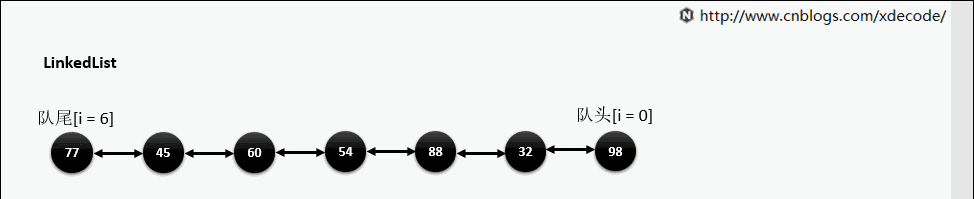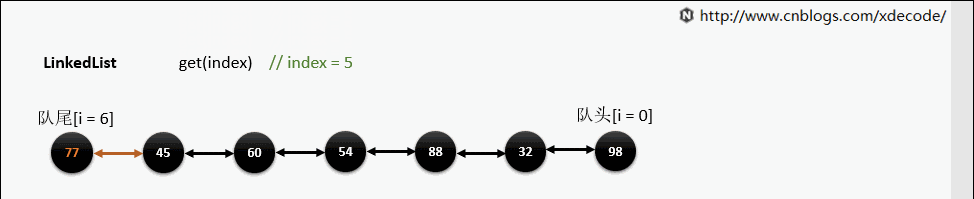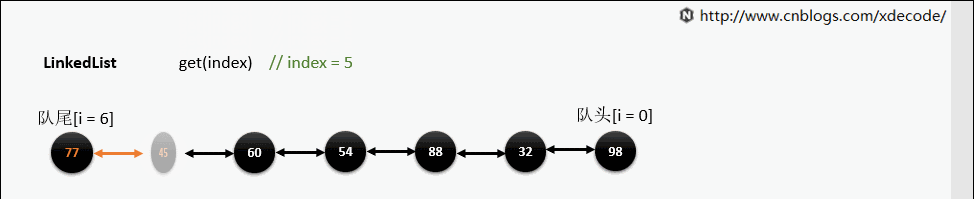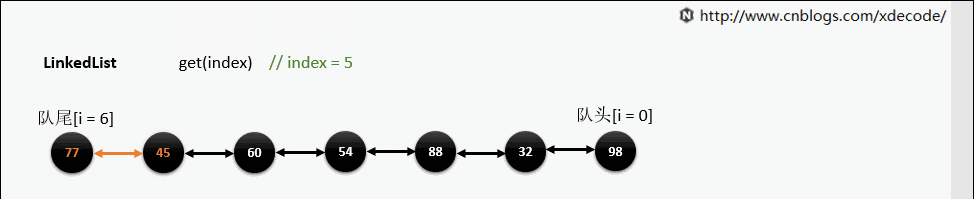
get(index)
也是会先判断index, 不过性能依然不好, 这也是为什么不推荐用for(int i = 0; i < lengh; i++)的方式遍历linkedlist, 而是使用iterator的方式遍历。
remove(E)
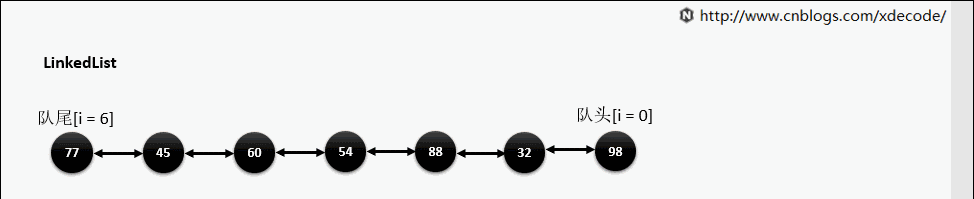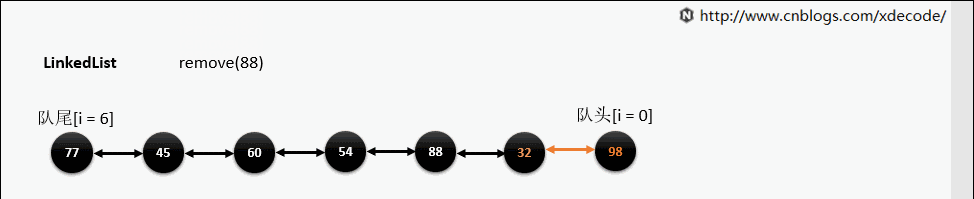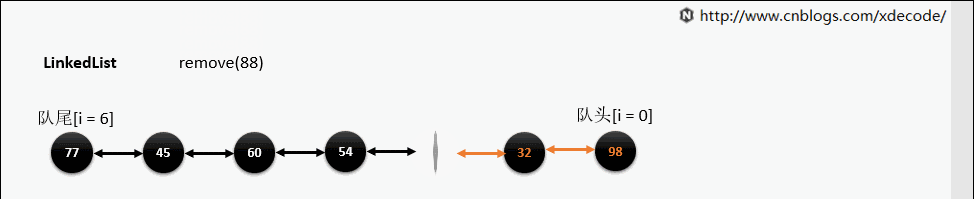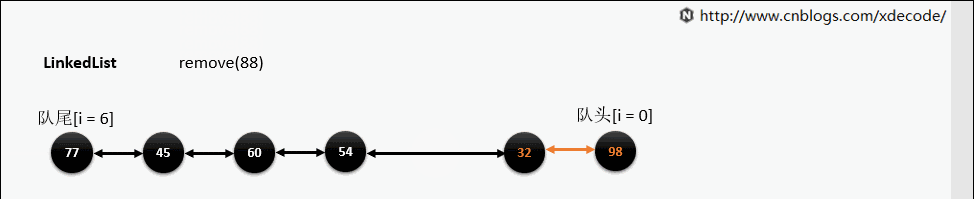
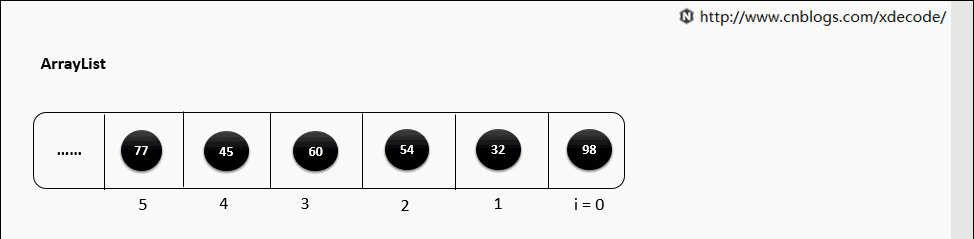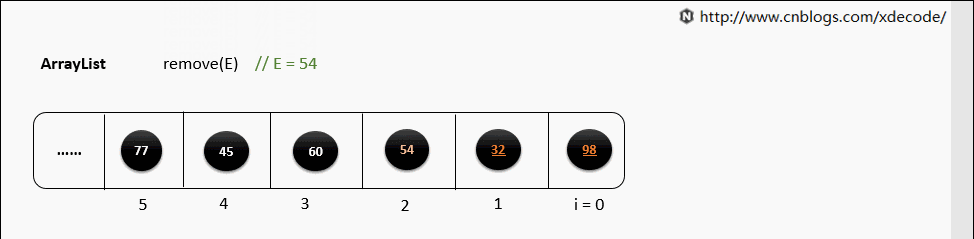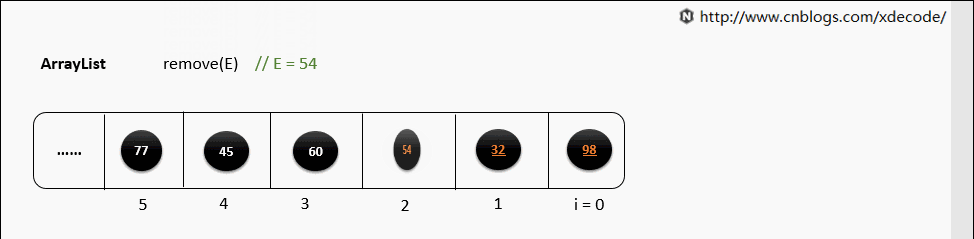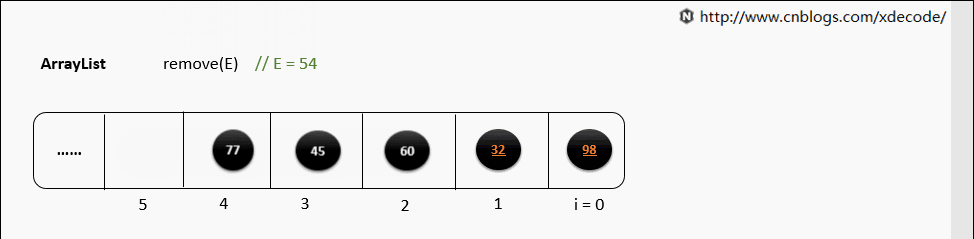
ArrayLis
底层就是一个数组, 因此按序查找快, 乱序插入、删除因为涉及到后面元素移位所以性能慢。
add(index, E)
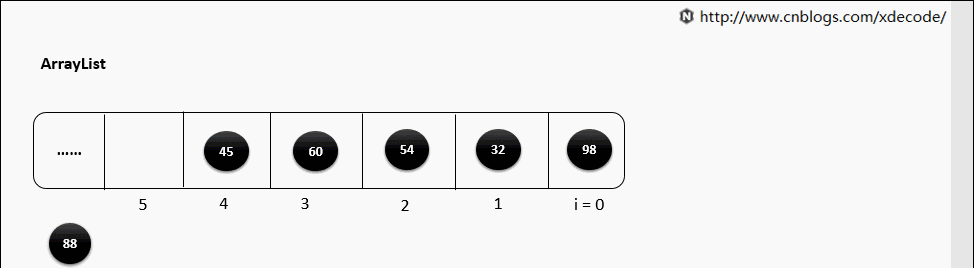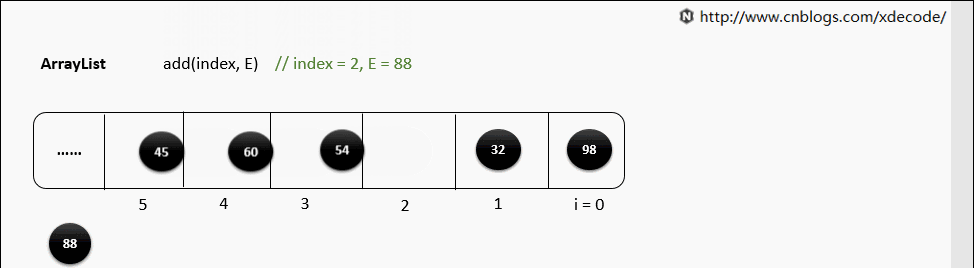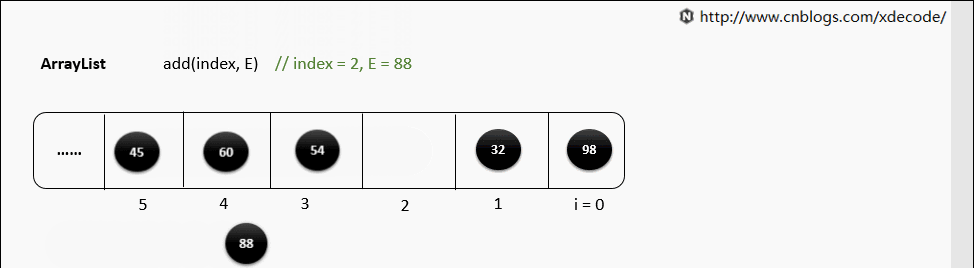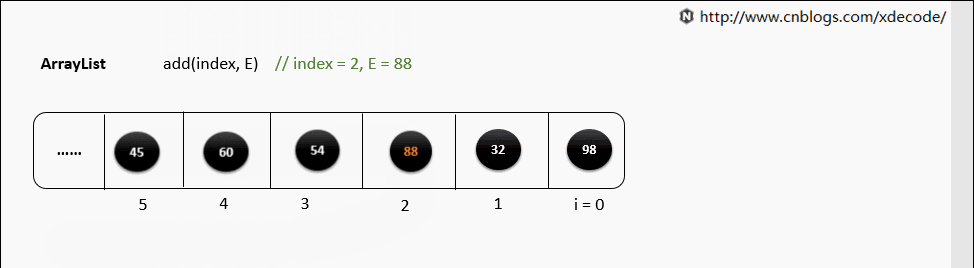
扩容
一般默认容量是10, 扩容后, 会length*1.5。

remove(E)
循环遍历数组, 判断E是否equals当前元素, 删除性能不如LinkedList.
【5】图
图是一组以网络形式相互连接的节点。节点也称为顶点。 一对节点(x,y)称为边(edge),表示顶点x连接到顶点y。边可以包含权重/成本,显示从顶点x到y所需的成本。

图的类型
- 无向图
- 有向图
在程序语言中,图可以用两种形式表示:
- 邻接矩阵
- 邻接表
常见图遍历算法
- 广度优先搜索
- 深度优先搜索
面试中关于图的常见问题
- 实现广度和深度优先搜索
- 检查图是否为树
- 计算图的边数
- 找到两个顶点之间的最短路径
【6】树
树形结构是一种层级式的数据结构,由顶点(节点)和连接它们的边组成。 树类似于图,但区分树和图的重要特征是树中不存在环路。
树形结构被广泛应用于人工智能和复杂算法,它可以提供解决问题的有效存储机制。
这是一个简单树的示意图,以及树数据结构中使用的基本术语:
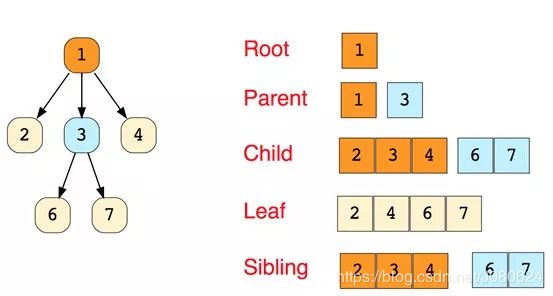
Root - 根节点
Parent - 父节点
Child - 子节点
Leaf - 叶子节点
Sibling - 兄弟节点
以下是树形结构的主要类型:
- N元树
- 平衡树
- 二叉树
- 二叉搜索树
- AVL树
- 红黑树
- 2-3树
其中,二叉树和二叉搜索树是最常用的树。
面试中关于树结构的常见问题:
- 求二叉树的高度
- 在二叉搜索树中查找第k个最大值
- 查找与根节点距离k的节点
- 在二叉树中查找给定节点的祖先节点
【7】字典树(Trie)
字典树,也称为“前缀树”,是一种特殊的树状数据结构,对于解决字符串相关问题非常有效。它能够提供快速检索,主要用于搜索字典中的单词,在搜索引擎中自动提供建议,甚至被用于IP的路由。
以下是在字典树中存储三个单词“top”,“thus”和“their”的例子:
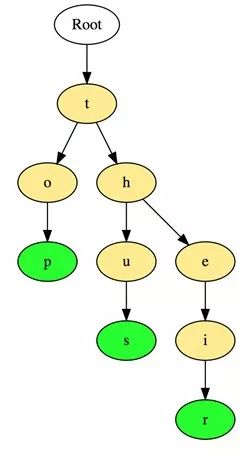
这些单词以顶部到底部的方式存储,其中绿色节点“p”,“s”和“r”分别表示“top”,“thus”和“theirs”的底部。
面试中关于字典树的常见问题
- 计算字典树中的总单词数
- 打印存储在字典树中的所有单词
- 使用字典树对数组的元素进行排序
- 使用字典树从字典中形成单词
- 构建T9字典(字典树+ DFS )
【8】哈希表
哈希法(Hashing)是一个用于唯一标识对象并将每个对象存储在一些预先计算的唯一索引(称为“键(key)”)中的过程。因此,对象以键值对的形式存储,这些键值对的集合被称为“字典”。可以使用键搜索每个对象。
基于哈希法有很多不同的数据结构,但最常用的数据结构是哈希表。哈希表通常使用数组实现。
散列数据结构的性能取决于以下三个因素:
- 哈希函数
- 哈希表的大小
- 碰撞处理方法
下图为如何在数组中映射哈希键值对的说明。该数组的索引是通过哈希函数计算的:
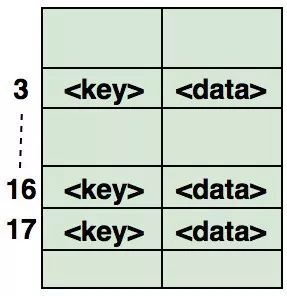
面试中关于哈希结构的常见问题:
- 在数组中查找对称键值对
- 追踪遍历的完整路径
- 查找数组是否是另一个数组的子集
- 检查给定的数组是否不相交
【9】HashMap
最常用的哈希表, 内部通过数组 + 单链表的方式实现. jdk8中引入了红黑树对长度 > 8的链表进行优化。
put(K, V)

put(K, V) 相同hash值

resize 动态扩容
当map中元素超出设定的阈值后, 会进行resize (length * 2)操作, 扩容过程中对元素一通操作, 并放置到新的位置。
具体操作如下:
- 在jdk7中对所有元素直接rehash, 并放到新的位置.
- 在jdk8中判断元素原hash值新增的bit位是0还是1, 0则索引不变, 1则索引变成"
原索引 + oldTable.length".
//定义两条链
//原来的hash值新增的bit为0的链,头部和尾部
Node loHead = null, loTail = null;
//原来的hash值新增的bit为1的链,头部和尾部
Node hiHead = null, hiTail = null;
Node next;
//循环遍历出链条链
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
//扩容前后位置不变的链
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
//扩容后位置加上原数组长度的链
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}

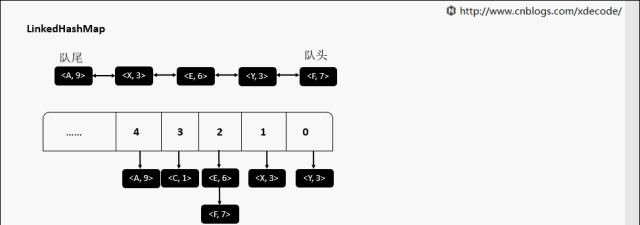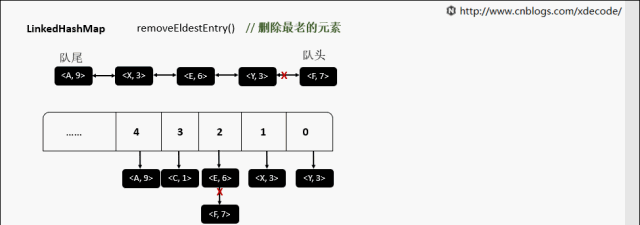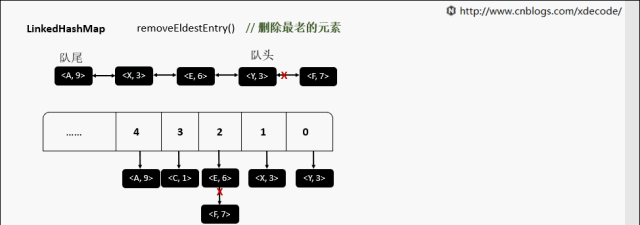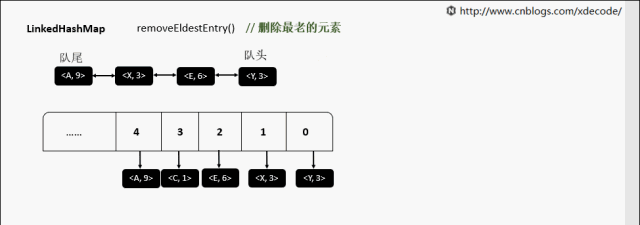
【10】LinkedHashMap
继承自HashMap, 底层额外维护了一个双向链表来维持数据有序. 可以通过设置accessOrder来实现FIFO(插入有序)或者LRU(访问有序)缓存。
put(K, V)

get(K)
accessOrder为false的时候, 直接返回元素就行了, 不需要调整位置。
accessOrder为true的时候, 需要将最近访问的元素, 放置到队尾。

removeEldestEntry 删除最老的元素
参考博文:
Java集合概述和总结分析与图示
Java 程序员必须掌握的 8 道数据结构面试题,你会几道?
几张动态图捋清Java常用数据结构及其设计原理