爬虫开发日记(第三天)
数据提取
1 爬虫中数据的分类
- 结构化数据:json,xml等
处理方式:直接转化为python类型 - 非结构化数据:HTML
处理方式:正则表达式、xpath
json的数据提取
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写。同时也方便了机器进行解析和生成。适用于进行数据交互的场景,比如网站前台与后台之间的数据交互。

具体使用方法:
#json.dumps 实现python类型转化为json字符串
#indent实现换行和空格
#ensure_ascii=False实现让中文写入的时候保持为中文
json_str = json.dumps(mydict,indent=2,ensure_ascii=False)
#json.loads 实现json字符串转化为python的数据类型
my_dict = json.loads(json_str)
#json.dump 实现把python类型写入类文件对象
with open("temp.txt","w") as f:
json.dump(mydict,f,ensure_ascii=False,indent=2)
#json.load 实现类文件对象中的json字符串转化为python类型
with open("temp.txt","r") as f:
my_dict = json.load(f)
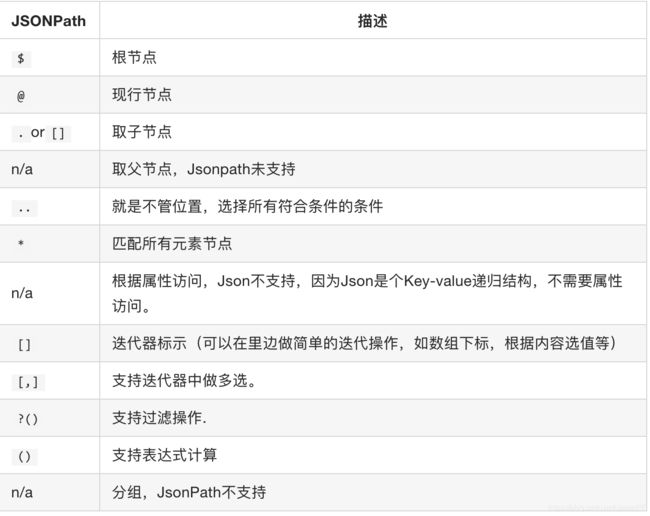
jsonpath模块
用来解析多层嵌套的json数据;JsonPath 是一种信息抽取类库,是从JSON文档中抽取指定信息的工具,提供多种语言实现版本,包括:Javascript, Python, PHP 和 Java。
JsonPath 对于 JSON 来说,相当于 XPath 对于 XML。
安装方法:pip install jsonpath
官方文档:http://goessner.net/articles/JsonPath
JsonPath与XPath语法对比:
正则
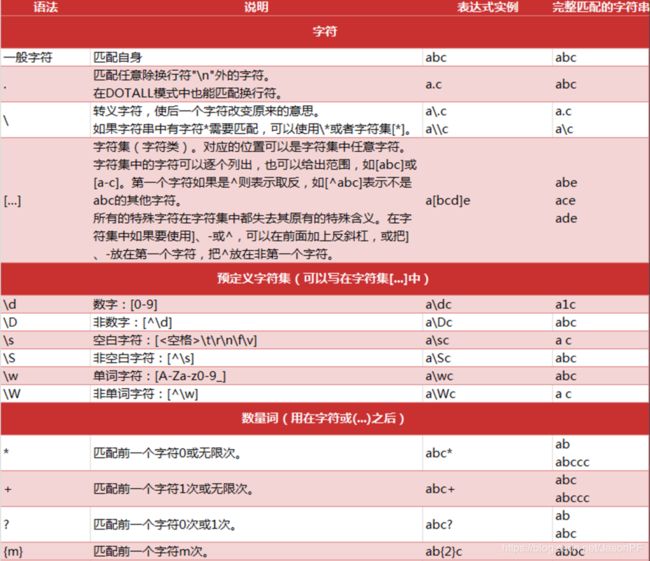
用事先定义好的一些特定字符、及这些特定字符的组合,组成一个规则字符串,这个规则字符串用来表达对字符串的一种过滤逻辑。
正则表达式的常见语法:
re模块的常见方法:
- pattern.match(从头找一个)
- pattern.search(找一个)
- pattern.findall(找所有)
返回一个列表,没有就是空列表
re.findall("\d",“chuan1zhi2”) >> [“1”,“2”] - pattern.sub(替换)
re.sub("\d","",“chuan1zhi2”) >> ["chuan_zhi"] - re.compile(编译)
返回一个模型P,具有和re一样的方法,但是传递的参数不同
匹配模式需要传到compile中
案例
1.json转换
import json
dict_one = {
"name": "laowang",
"age": 18
}
# 1.python的dict --> 字符串json_str
json_one_str = json.dumps(dict_one)
print(type(json_one_str))
# 2.字符串json_str --> python的dict list
dict_json = json.loads(json_one_str)
print(type(dict_json))
# 3.dict写入json文件中
fp = open('01json.json', 'w')
json.dump(dict_one, fp)
fp.close()
# 4.读取json文件直接转成dict
fp_dict = json.load(open('01json.json', 'r'))
print(type(fp_dict))
2.jsonpath的使用
import json
import requests
import jsonpath
class LaGou(object):
def __init__(self):
self.url = 'https://www.lagou.com/lbs/getAllCitySearchLabels.json'
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.86 Safari/537.36"
}
def send_request(self):
response = requests.get(self.url, headers=self.headers)
data = response.content.decode()
return data
def save_data(self, data):
data_dict = json.loads(data)
result_list = jsonpath.jsonpath(data_dict, '$..name')
# print(result_list)
json.dump(result_list, open('02lagou.json', 'w'))
def run(self):
data = self.send_request()
self.save_data(data)
if __name__ == '__main__':
tool = LaGou()
tool.run()
3.正则
import re
# # 1. . 点匹配任意字符, 除了\n; 但是在DOTALL中可以匹配
#
# one = """
# afklsfhefNVS
# MMMMDJNJKKBB
# NNAAACCCCCCb
# """
#
# pattern = re.compile('a(.*)b') # []
# pattern = re.compile('a(.*)b', re.DOTALL) # ['fklsfhefNVS\nMMMMDJNJKKBB\nNNAAACCCCCC']
# # 或者写成re.S
# pattern = re.compile('a(.*)b', re.S)
#
# result = pattern.findall(one)
# print(result)
#
#
# two = 'abc123cba'
# pattern = re.compile('^\d+$')
# result = pattern.match(two) # None
# result = pattern.search(two) # None
# result = pattern.findall(two) # []
#
# # 了解
# result = pattern.finditer(two)
# for res in result:
# print(res.group())
#
# # print(result)
# 替换
three = 'ni_hao_hello'
pattern = re.compile('_')
result = pattern.sub('', three)
print(result) # nihaohello
# 调换顺序
four = 'a b c d'
sub_pattern = re.compile(r'(\w+) (\w+)')
result = sub_pattern.sub(r'\2 \1', four)
print(result) # b a d c
# 拆分
five = 'a,b,c,d:e;f g'
split_pattern = re.compile(r'[,:; ]+')
result = split_pattern.split(five)
print(result) # ['a', 'b', 'c', 'd', 'e', 'f', 'g']
# 匹配汉字
china_str = '北京欢迎您 welcome to beijing'
china_pattern = re.compile('[\u4e00-\u9fa5]+')
result = china_pattern.findall(china_str)
print(result) # ['北京欢迎您']
china_pattern = re.compile('[^\u4e00-\u9fa5]+')
result = china_pattern.findall(china_str)
print(result) # [' welcome to beijing']
4.果壳网精彩问答
import json
import re
import requests
class GuokrSpider(object):
def __init__(self):
self.base_url = 'https://www.guokr.com/ask/highlight/'
self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko"}
# 1.发送请求
def send_request(self):
data = requests.get(self.base_url, headers=self.headers).content.decode()
return data
# 2.解析数据
# 需要提取的数据形式:
# 印度人把男人的生殖器叫林伽,把女人的生殖器叫瑜尼,林伽和瑜尼的交合,便是瑜伽。这是真还是假的
def parse_data(self, data):
pattern = re.compile(r'(.*)
')
data_list = pattern.findall(data)
# print(data_list)
return data_list
# 3.保存数据
def save_data(self, data_list):
# with open('04guokr.html', 'w') as f:
# f.write(data_list)
json.dump(data_list, open('04json.json', 'w'), ensure_ascii=False)
# 4.调度
def run(self):
data = self.send_request()
data_list = self.parse_data(data)
self.save_data(data_list)
if __name__ == '__main__':
GuokrSpider().run()
5.36氪新闻
import json
import re
import jsonpath
import requests
class KrSpider(object):
def __init__(self):
self.base_url = 'https://36kr.com/'
self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko"}
def send_request(self):
data = requests.get(self.base_url, headers=self.headers).content.decode()
return data
def prase_data(self, data):
patterns = re.compile(r'')
data_list = patterns.findall(data)[0]
return data_list
def save_data(self, data_list):
with open('05kr.json', 'w') as f:
f.write(data_list)
def read_data(self):
json_dict = json.load(open('05kr.json', 'r'))
print(type(json_dict))
result_list = jsonpath.jsonpath(json_dict, '$..title')
print(result_list)
def run(self):
data = self.send_request()
data_list = self.prase_data(data)
self.save_data(data_list)
self.read_data()
if __name__ == '__main__':
KrSpider().run()
6.内涵吧帖子
import re
import requests
class NeihanbaSpider(object):
def __init__(self):
self.base_url = 'https://www.neihan-8.com/article/list_5_{}.html'
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.86 Safari/537.36"}
self.first_pattern = re.compile(r'(.*?)', re.S)
self.second_pattern = re.compile(r'<(.*?)>|&(.*?);|\s')
def send_request(self, url):
data = requests.get(url, headers=self.headers).content.decode('gbk')
return data
def prase_data(self, data):
# 第一层解析
result_list = self.first_pattern.findall(data)
return result_list
def save_data(self, data_list, page):
page_num = '\n*******************第' + str(page) + '页*******************\n\n'
print(page_num)
with open('06内涵.txt', 'a') as f:
f.write(page_num)
i = 0
for data in data_list:
# 第二层解析
i += 1
new_data = str(i) + ': ' + self.second_pattern.sub('', data) + '\n'
f.write(new_data)
def run(self):
for page in range(1, 10):
url = self.base_url.format(page)
data = self.send_request(url)
data_list = self.prase_data(data)
self.save_data(data_list, page)
if __name__ == '__main__':
NeihanbaSpider().run()