Mysql 数据库学习笔记
前言
Mysql
Mysql是一个关系型的数据库管理系统,由Mysql ab公司设计的产品,后期被oracle收购,内部采用分库分表形式管理数据。一个数据库管理系统可以管理多个数据库;一个数据库中可以存放多张表。开源免费,支持千万级,支持GPL。
数据库
- 数据库(DataBase:DB):按照一定数据结构存储和管理数据的仓库。数据模型结构分为: 1)层次模型2)网状模型3)关系模型,关系模型:将复杂的关系以简单的二元形式进行表示。以行和列的形式进行表示(表格)。行叫记录,列叫字段。
-
数据分类:1)结构化数据:可以通过统一的结构来进行描述的管理 2)非结构化数据:通过统一的方式进行描述 3)半结构化数据:位于上述两者之间 (html/xml)。
- 数据库分类:1)关系型数据库:操作结构化数据 2)非关系型数据库:非结构化
-
数据库管理系统(DBMS:Database Management System):管理和操作数据库的软件,1)关系型数据库管理系统:Oracle、Mysql、SQL server、DB2 2)非关系型数据库管理系统:Redis 、Hbase 、mongdb 、neo4j
数据库的下载和安装
(此处省略,相信会有很多博客对此的详细描述)
Sql(结构化查询语言 对大小写不敏感)
分类
- DDL(Data definatition language):数据定义语言,对数据库对象(数据库,表,视图,索引等)结构操作。(创建/修改/销毁:create/alter/drop)
- DML(Data Manitaption language):数据操纵语言。(增删改查:Insert/delete/update/select)
- DCL(Data Contol language):数据控制语言。(Grant/revoke:授权与取消授权)
- TCL(Transaction Contol language):事务控制语言(Commit/rollback:提交和回滚)
DDL:数据定义语言
数据库的销毁和创建
-- 创建数据库 test
create database if not exists test;
-- 销毁数据库(少用)
drop database if exists test;数据库表的创建
create table student(id int,name string,age int);数据类型(各种数据库之间有所区别):
整型数据
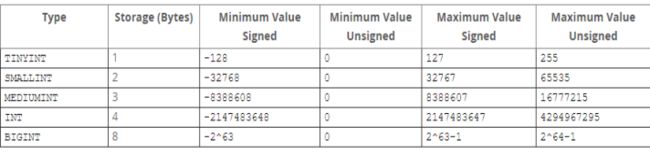
浮点数:
Float(m,n): m为长度,n 为小数点位数
Double(m,n)
Decimal(m,n):16字节
字符串:
Char(n):定长字符串
Varchar(n):可变字符串
Text:长文本
日期:
Date:年月日
Time:时分秒
Datatime:年月日-时分秒 1000-9999
TimeStamp:时间戳
Year
其他类型
Blob:二进制数据
Enum('male',famale):枚举
Set('1','2','3'):集合类型
Json:json类型
表结构的修改
-- 添加字段(追加)
alter table student add sex varchar(20);
-- 添加到首位
alter table student add cid int first;
-- 添加到指定位置
alter table student add birthday date after cid;
-- 查看表结构
desc student;
-- 修改字段(名称,类型,长度,位置)(modify)
alter table student change age sage int;
alter table student change sname sname varchar(50);
alter table student modify sname varchar(20);
(注意change和modify的区别,change需要加上原表表名,modify直接跟新表名)
alter table student change sname sname varchar(20) after cid;
alter table student modify sname varchar(20) after cid;
-- 删除字段
alter table student drop cid;
-- 表名称修改
rename table student to stu;
-- 清空表
truncate table stu;销毁表
drop table tbname;完整性约束
实体完整性
实体:记录(记录之间不能重复);
主键约束: 唯一并且不能为空
-- 创建表的同时添加主键约束
-- 主键选择:无意义字段(主键一般不修改,经常变化字段,业务字段不适合作为主键)
-- 1.字段声明后添加primary key
create table student(sid int primary key,sname varchar(20),age int);
-- 2. 声明完字段之后添加主键
create table student(sid int,sname varchar(20),age int,primary key(sid,sname));
-- 3.创建完表添加主键约束
-- 约束 约束的名称
alter table student add CONSTRAINT pk_sid primary key(sid);唯一约束:
唯一约束(unique 唯一)
alter table student add CONSTRAINT uq_card unique(card);主键自增: 1 增加1
alter table student modify sid int primary key auto_increment;域完整性
- 类型约束
- 非空约束: not null
-
默认值: default
引用完整性
一张表中字段(外键)的取值需要参照另一张表(主键),外键取值范围不能大于另一张表的主键范围。
外键:foreign key:
-- ref:参照
alter table student add CONSTRAINT FK_CID foreign key(cid)
REFERENCES classroom(cid);
外键名称可以和参照表主键不一致,但是类型长度必须一致。自定义完整性
自定义完整性(check约束oracle mysql不支持 )
-- check约束
alter table student add CONSTRAINT ck_age check(age BETWEEN 1 and 120);DML:数据操纵语言
添加:insert into tname[(字段名称…)] values(值…)
1.全部字段添加数据
insert into student values(1,'zs',1,'男');
2.部分字段添加数据
insert into student(sname,cid) values('ls',2);
3.添加三条测试数据到student表(批量插入)
insert into student(sname,cid,sex) values('ww',2,'man'),('zl',3,'man'),('fq',3,'man');
4.复制student表创建stu where子句:条件
-- 复制表结构和数据
create table stu select * from student;
-- 复制表结构
create table stu select * from student where 1=0;
5.插入数据(获取结果集插入)
insert into stu select * from student;修改: update tname set 字段名称=值 [where 条件]
update student set sex = '女' where sid = 4;删除:delete from tname [where 条件]
delete from student where sid = 7;
delete from student where sid = 1 or sid = 3 or sid = 5
delete from student where sid in (1,3,5); 从集合中删除
delete和truncate区别:
1. 不修改结构只清除数据
2. delete删除不释放资源,truncate释放(会重置自增)
3. delete是逐行删除,truncate效率高于delete。查询
select 字句 from 表(结果集)where 条件(简单,组合条件)group by 分组 having 条件 order by 排序 limit 限制结果(分页查询 mysql)
示例:
#查询emp表所有数据
select * from emp;
#查询所有员工姓名
select ename from emp;
#简单条件 7788员工信息
select * from emp where empno = 7788;
#查询20号部门工资大于2000的员工信息
select * from emp where deptno = 20 and sal > 2000;
#查询工资在1500-2000之间的员工信息(范围查询)
#select * from emp where sal >= 1500 and sal <=2000;
select * from emp where sal BETWEEN 1500 and 2000;
#查询工资大于2000,工资小于1000的员工信息
select * from emp where sal > 2000 or sal < 1000;
#查询员工编号为7788,7521,7369的员工信息(集合查询)
#select * from emp where empno=7788 or empno=7521 or empno=7369;
select * from emp where empno in (7788,7521,7369);
# 查询所有的职位信息(去重)
select DISTINCT job from emp;
# 查询所有没有奖金的员工信息(null判断 is [not] null)
select * from emp where comm = 0 or comm is not null;
# 起别名(解释字段 简化字段 ) 字段|表 [as] 别名
select empno 编号,ename 名称 from emp;
select empno,ename from emp;
# 查询姓名S打头的员工信息(模糊查询 like %:0到多个字符 _:代表一个字符)
select * from emp where ename like 'S%';
#查询T结尾的
select * from emp where ename like '%T';
#查询包含S的
select * from emp where ename like '%S%';
#查询第二个字符为L的
select * from emp where ename like '_L%';
# 查询前五条记录 (分页) limit index,length
select * from emp limit 4,2;
# 查询工资最高的5个人 order by 字段 [asc|desc]
select * from emp order by sal desc limit 0,5;
# 排序
select * from emp order by sal desc,empno desc;函数
单行函数
- 数学函数
select ABS(-1); -- 绝对值
select CEIL(12.3); -- 向上取整
select CEIL(-12.8);
select FLOOR(-12.3); -- 向下取整
select RAND(); -- 随机数
select ROUND(12.3,-1); -- 四舍五入 0:小数点
select PI(); -- PI
select MOD(5,2); -- 取模
select POW(2,3);- 字符函数
-- 字符函数
select UPPER(ename) from emp;
select LOWER(ename) from emp;
select LENGTH(ename) from emp;
select CONCAT('aa ','bb');
select SUBSTR('abcd',1,3); -- 截取
select REPLACE('abcd','bc','ee'); -- 替换
-- 填充
select LPAD('aa',10,'*');
select RPAD('aa',10,'*');
-- 去空格
select TRIM(' aa ');- 日期函数
-- 日期函数
-- 获取当前时间
select NOW();
select SYSDATE();
select CURRENT_DATE();
select CURRENT_TIME();
select CURRENT_TIMESTAMP();
-- 获取年,月等
select YEAR('1989-09-09');
select MONTH(NOW());
select DAY(NOW());
select DAYOFYEAR(NOW());
-- 日期计算
select ADDDATE('1989-09-09',interval 10 DAY);
select ADDDATE('1989-09-09',interval 2 YEAR);
select LAST_DAY('2018-02-05');聚合函数
-- max() min() count() sum() avg()
select max(sal) from emp;
select min(sal) from emp;
select count(*) from emp; -- 统计记录数
select count(1) from emp; -- 统计记录数
select count(comm) from emp; -- 统计字段数据
select sum(sal) from emp;
select avg(sal) from emp;分组函数
分组函数 group by 分组字段 having
# where子句中不能写聚合函数
# where子句执行顺序在group by之前,语法也必须在group by之前
# having可以实现对分组之后的结果集再次进行检索
select deptno,avg(sal) avg from emp group by deptno having avg > 2000;
# 查询平均工资大于2000的部门编号和平均工资
# 查询每个部门中工资大于1000的员工的平均工资
select deptno,avg(sal) from emp where sal > 1000 group by deptno;加密函数
select length(MD5('root')); -- 32
select length(SHA('root'));
select PASSWORD('root');高级查询
关联查询
内连接
内连接能够出现的记录 : 只有在连接表都存在的记录才能被连接展示在最终结果集中。
连接顺序 : 内连接与连接顺序无关。
三种不同表达方式示例:
select * from emp,dept where emp.deptno = dept.deptno ;
select * from emp inner join dept on emp.deptno = dept.deptno;
select * from emp inner join dept using(deptno);外连接
左外连接: left [outer] join … on…
右外连接: right [outer] join … on…
执行策略 : 有主从表之分,以主表为基准,依次在从表中获取和主表相匹配的记录,如果找到,则连接并展示在结果集中;如果找不到则以null填充。
连接顺序 : 外连接与连接顺序有关。左外连接前主后从,右外连接前从后主。
示例:
select * from dept left join emp on emp.deptno = dept.deptno;自然连接
-- 自然连接(等值连接)
select * from emp NATURAL join dept;子查询(将子查询的结果作为另一个查询的条件或者结果集)
示例:
select * from emp where sal > (select sal from emp where ename ='scott');
单行子查询:
子查询的返回结果只有一条记录。 > < =
多行子查询:
子查询返回结果有多条记录。
In any all
=any:in >any:大于最小值 all:大于最大值 e.avg;
select * from emp e1 where sal > (select avg(sal) from emp e2 where e2.deptno = e1.deptno);
select * from dept where deptno in (select deptno from emp where sal > 2000);
select * from dept d where exists (select * from emp e where sal > 2000 and d.deptno = e.deptno);
# in:先执行子查询,然后子查询将结果返回给主查询,最后执行主查询
# exists:存在,先执行主查询,将主查询的记录依次在子查询中根据通用列实现匹配
# 如果匹配到,子查询返回true,将主查询的结果与子查询连接展示在结果集中.
# 如果不能匹配,则传入子查询的主查询记录不会出现在结果集中。 联合查询
联合查询
union 去除重复记录
union all 不去除重复记录(优化 索引:or)
# 查询工资>2000或者在20号部门的员工信息。
select * from emp where sal > 2000 union select * from emp where deptno = 20;事务
存储引擎
Mysql的核心就是存储引擎,增删改查操作通过存储引擎实现。Mysql中可以有多种存储引擎,5.5后默认使用InnoDB,InnoDB是事务型的存储引擎。

事务
- 什么是事务
事务用于保证数据的一致性,由一组DML操作组成,该组SQL语句要么同时成功,要么同时失败。例如转账。
- 事务的四个特性(ACID)
- 原子性: 事务中的一组DML操作必须作为整体执行,不可分割。
- 一致性: 事务执行前后整体的状态必须一致。
- 隔离性: 并发事务之间互相不能影响。
- 持久性: 事务执行完毕就永久保存。
- 并发事务引起的问题
- 脏读 : 一个事务读到另一个事务未提交的数据。
- 不可重复读 : 一个事务在多次读取过程中发现数据不一致。该事务在多次读取期间,由另一个事务修改并进行事务提交引起。
- 幻读(虚读) : 一个事务在读取过程中发现数据变多或者消失的问题。该事物多次读取期间,由另一个事务添加或者删除记录并提交事务引起。
- 事务的隔离级别
- 读未提交: 不能解决任何一个问题。
- 读已提交: 解决脏读问题。 较多
- 可重复读: 脏读,不可重复读问题。 较多。
- 串行化: 解决所有问题。速度慢。
- 编程事务管理
show VARIABLES like '%autocommit%';
-- 设置是否自动提交
set autocommit = 0;
-- 开启事务
start TRANSACTION;
update account set money = money + 100 where name = 'zs';
update account set money = money - 100 where name = 'ls';
-- 提交/回滚
#commit;
rollback;存储程序
存储程序指的一组存储和执行在数据库服务器端的程序。存储程序总是在服务器的进程或者线程的内存中执行的。
存储过程
类似于方法,有过程名称,参数列表,过程体组成。
过程创建和调用:
-- 创建
delimiter //
create PROCEDURE selEmpByNo(eno int)
begin
select ename from emp where empno = eno;
end;
//
-- 调用
all selEmpByNo(7788);
参数有三种模式:
IN:默认,由外部将参数传入过程。
OUT: 可以由存储过程将值传出。
INOUT: 可以传入也可以传出。存储函数(有参数和返回值)
-- 存储函数(eno查询ename)
delimiter //
create function fun_sel(eno int)
returns varchar(20) -- 返回值的类型
DETERMINISTIC -- 确定
begin
declare v_name varchar(20);
select ename into v_name from emp where empno = eno;
return v_name;
end;
//
select fun_sel(7788);
存储过程和函数区别:
关键字不同
存储过程通过参数模式返回值,函数可以通过return返回值。
存储过程可以作为独立调用的个体,函数必须作为sql的一部分进行调用。触发器(不能手动调用,不能传递参数,由事件触发(增删改))
语法:
CREATE
[DEFINER = { user | CURRENT_USER }]
TRIGGER trigger_name
trigger_time trigger_event
ON tbl_name FOR EACH ROW
[trigger_order]
trigger_body
trigger_time: { BEFORE | AFTER }
trigger_event: { INSERT | UPDATE | DELETE }
trigger_order: { FOLLOWS | PRECEDES } other_trigger_name
示例:
delimiter //
create trigger tri_stu
after delete
on stu for each row
begin
insert into student(sname,cid) values(old.sname,old.cid);
end;
//
触发器影响性能。视图和索引
视图
虚拟表,在数据库中没有物理结构存在,视图数据来自于基表,在执行过程中动态从基表中获取数据并进行展示。视图可以使用增删改查的功能,视图如果使用增删改则会修改基表数据。视图不建议使用增删改。
- 基本语法
-- 视图
-- 创建视图
create view view_emp as select * from emp where deptno = 10 with check option;
-- 对视图的操作
select * from view_emp;
update view_emp set deptno = 20;
-- 删除视图
drop view view_emp;- 优点
- 简化开发
- 安全性
- 定制化数据(拆分,组合字段信息)
索引
索引是为提高查询效率设计的数据库结构,本质需要文件存储,需要维护。
索引添加规则:
数据量较大。
添加索引在高基数列。
不能添加过多索引(需要维护)
不合适添加索引:
不能添加在过多增删改操作的表。
默认采用B树索引。 (位图索引)
create index index_sid on stu(sid);
drop index index_sid on stu;数据库设计
三大范式
1NF: 数据列都是不可分割的原子项。
2NF: 所有非主键字段必须与主键相关,而不是部分相关(联合主键)。
一张表只描述一个事物。
3NF: 所有非主键字段必须与主键直接相关,非主键字段之间不能直接相关。实体之间的关系
一对一:个人信息表和档案表
1)外键添加唯一约束
2)主键做外键
一对多:雇员表和部门表
多对多:学生表和课程表
需要添加关系维护表
设计联合主键数据库优化
select 字句后尽量不要用 *
- 索引失效情况下
1.Not Null/Null 如果某列建立索引,当进行Select * from emp where depto is not null/is null。则会是索引失效。
2.索引列上不要使用函数,
SELECT Col FROM tbl WHERE substr(name ,1 ,3 ) = ‘ABC’(不)
SELECT Col FROM tbl WHERE name LIKE ‘%ABC%’ (不)
SELECT Col FROM tbl WHERE name LIKE ‘ABC%’ (使用)。
3.索引列上不能进行计算
SELECT Col FROM tbl WHERE col / 10 > 10 则会使索引失效
应该改成SELECT Col FROM tbl WHERE col > 10 * 10
4.索引列上不要使用NOT ( != 、 <> )
如:SELECT Col FROM tbl WHERE col ! = 10 应该
改成:union。- 使用 union 替换 or (使用于索引列)
union:是将两个查询的结果集进行追加在一起,它不会引起列的变化。 由于是追加操作,需要两个结果集的列数应该是相关的,并且相应列的数据类型也应该相当的。
union 返回两个结果集,同时将两个结果集重复的项进行消除。 如果不进行消除,用UNOIN ALL.
通常情况下, 用UNION替换WHERE子句中的OR将会起到较好的效果. 对索引列使用OR将造成全表扫描.
注意, 以上规则只针对多个索引列有效.
如果有column没有被索引, 查询效率可能会因为你没有选择OR而降低.- 用EXISTS替代IN、用NOT EXISTS替代NOT IN
在许多基于基础表的查询中, 为了满足一个条件, 往往需要对另一个表进行联接. 在这种情况下, 使用EXISTS(或NOT EXISTS)通常将提高查询的效率.
在子查询中, NOT IN子句将执行一个内部的排序和合并. 无论在哪种情况下, NOT IN都是最低效的(因为它对子查询中的表执行了一个全表遍历).
为了避免使用NOT IN, 我们可以把它改写成外连接(Outer Joins)或NOT EXISTS.
高效: SELECT * FROM EMP (基础表) WHERE EXISTS (SELECT ‘X’ FROM DEPT WHERE DEPT.DEPTNO = EMP.DEPTNO AND LOC = ‘MELB’)
低效: SELECT * FROM EMP (基础表) WHERE DEPTNO IN(SELECT DEPTNO FROM DEPT WHERE LOC = ‘MELB’)备份和还原
笔者也没有用过,感觉实用性不强
Mysqldump -uroot -proot dbname > d:/t.sql;
mysql -u root -p < C:\backup.sql(写在最后:欢迎指正。)