Spring自动扫描类的加载顺序
写这篇文章的原因是本地代码运行结果和线上服务器运行结果不一致,类的加载顺序不一样,导致了意想不到的bug,由此展开了对spring自动扫描类的加载机制的探索,先看一下代码,主要涉及到RedissonProperties类和MopFictionTurntableSchedule类。
代码整体结构如下:
spring用的4.2版本,本地用jetty7.6.9.v20130131 运行,服务器用resin4.0.36运行
@Component
public class RedissonProperties {
private static final Logger logger = LoggerFactory.getLogger(RedissonProperties.class);
public static String redissonHost = null;
public static Integer redissonPort = null;
@Value("${redisson.host}")
public void setRedissonHost(String redissonHostP) {
redissonHost = redissonHostP;
}
@Value("${redisson.port}")
public void setRedissonPort(Integer redissonPortP) {
redissonPort = redissonPortP;
}
}@Component
public class MopFictionTurntableSchedule {
private static final Logger logger = LoggerFactory.getLogger(MopFictionTurntableSchedule.class);
@Autowired
private FictionTurntableMapper fictionTurntableMapper = null;
private static RedissonClient redissonClient = null;
static {
logger.debug("start MopFictionTurntableSchedule init ");
logger.debug("redissonHost "+RedissonProperties.redissonHost );
logger.debug("redissonPort "+RedissonProperties.redissonPort);
if (redissonClient == null) {
String redissonAddress = "redis://" + RedissonProperties.redissonHost + ":" + RedissonProperties.redissonPort;
Config config = new Config();
config.useSingleServer().setAddress(redissonAddress);
redissonClient = Redisson.create(config);
}
}
//后面省略
}项目在本地运行并没有任何问题,输出结果如下:

但是当把项目丢在服务器上却报错了,输出结果如下:
![]()
对比分析可以得出在本地环境RedissonProperties 比MopFictionTurntableSchedule 加载的早,所以RedissonProperties 的静态属性成功注入,等到MopFictionTurntableSchedule 被加载的时候就没有问题。
服务器环境MopFictionTurntableSchedule 要比RedissonProperties 加载的早,所以导致异常。
由此可见spring在使用自动扫描过程中加载类的顺序是有区别的。
下面开始源码分析:
在web项目中我们配置了
org.springframework.web.context.ContextLoaderListener
通过idea的调试功能,一步步跟进去,很快可以找到spring初始化的核心代码。
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
// Prepare this context for refreshing.
prepareRefresh();
// Tell the subclass to refresh the internal bean factory.
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// Prepare the bean factory for use in this context.
prepareBeanFactory(beanFactory);
try {
// Allows post-processing of the bean factory in context subclasses.
postProcessBeanFactory(beanFactory);
// Invoke factory processors registered as beans in the context.
invokeBeanFactoryPostProcessors(beanFactory);
// Register bean processors that intercept bean creation.
registerBeanPostProcessors(beanFactory);
// Initialize message source for this context.
initMessageSource();
// Initialize event multicaster for this context.
initApplicationEventMulticaster();
// Initialize other special beans in specific context subclasses.
onRefresh();
// Check for listener beans and register them.
registerListeners();
// Instantiate all remaining (non-lazy-init) singletons.
finishBeanFactoryInitialization(beanFactory);
// Last step: publish corresponding event.
finishRefresh();
}
catch (BeansException ex) {
logger.warn("Exception encountered during context initialization - cancelling refresh attempt", ex);
// Destroy already created singletons to avoid dangling resources.
destroyBeans();
// Reset 'active' flag.
cancelRefresh(ex);
// Propagate exception to caller.
throw ex;
}
finally {
// Reset common introspection caches in Spring's core, since we
// might not ever need metadata for singleton beans anymore...
resetCommonCaches();
}
}
}我们先从结果开始看,finishBeanFactoryInitialization(beanFactory);
跟进去,代码如下
protected void finishBeanFactoryInitialization(ConfigurableListableBeanFactory beanFactory) {
// Initialize conversion service for this context.
if (beanFactory.containsBean(CONVERSION_SERVICE_BEAN_NAME) &&
beanFactory.isTypeMatch(CONVERSION_SERVICE_BEAN_NAME, ConversionService.class)) {
beanFactory.setConversionService(
beanFactory.getBean(CONVERSION_SERVICE_BEAN_NAME, ConversionService.class));
}
// Initialize LoadTimeWeaverAware beans early to allow for registering their transformers early.
String[] weaverAwareNames = beanFactory.getBeanNamesForType(LoadTimeWeaverAware.class, false, false);
for (String weaverAwareName : weaverAwareNames) {
getBean(weaverAwareName);
}
// Stop using the temporary ClassLoader for type matching.
beanFactory.setTempClassLoader(null);
// Allow for caching all bean definition metadata, not expecting further changes.
beanFactory.freezeConfiguration();
// Instantiate all remaining (non-lazy-init) singletons.
beanFactory.preInstantiateSingletons();
}到了beanFactory.preInstantiateSingletons();发现类还没有被初始化,继续跟入。
public void preInstantiateSingletons() throws BeansException {
if (this.logger.isDebugEnabled()) {
this.logger.debug("Pre-instantiating singletons in " + this);
}
// Iterate over a copy to allow for init methods which in turn register new bean definitions.
// While this may not be part of the regular factory bootstrap, it does otherwise work fine.
List beanNames = new ArrayList(this.beanDefinitionNames);
// Trigger initialization of all non-lazy singleton beans...
for (String beanName : beanNames) {
RootBeanDefinition bd = getMergedLocalBeanDefinition(beanName);
if (!bd.isAbstract() && bd.isSingleton() && !bd.isLazyInit()) {
if (isFactoryBean(beanName)) {
final FactoryBean factory = (FactoryBean) getBean(FACTORY_BEAN_PREFIX + beanName);
boolean isEagerInit;
if (System.getSecurityManager() != null && factory instanceof SmartFactoryBean) {
isEagerInit = AccessController.doPrivileged(new PrivilegedAction() {
@Override
public Boolean run() {
return ((SmartFactoryBean) factory).isEagerInit();
}
}, getAccessControlContext());
}
else {
isEagerInit = (factory instanceof SmartFactoryBean &&
((SmartFactoryBean) factory).isEagerInit());
}
if (isEagerInit) {
getBean(beanName);
}
}
else {
getBean(beanName);
}
}
}
// Trigger post-initialization callback for all applicable beans...
for (String beanName : beanNames) {
Object singletonInstance = getSingleton(beanName);
if (singletonInstance instanceof SmartInitializingSingleton) {
final SmartInitializingSingleton smartSingleton = (SmartInitializingSingleton) singletonInstance;
if (System.getSecurityManager() != null) {
AccessController.doPrivileged(new PrivilegedAction 终于来了关键代码。
// Trigger initialization of all non-lazy singleton beans...
所有不是懒加载的单例类的触发器初始化
由此可见List
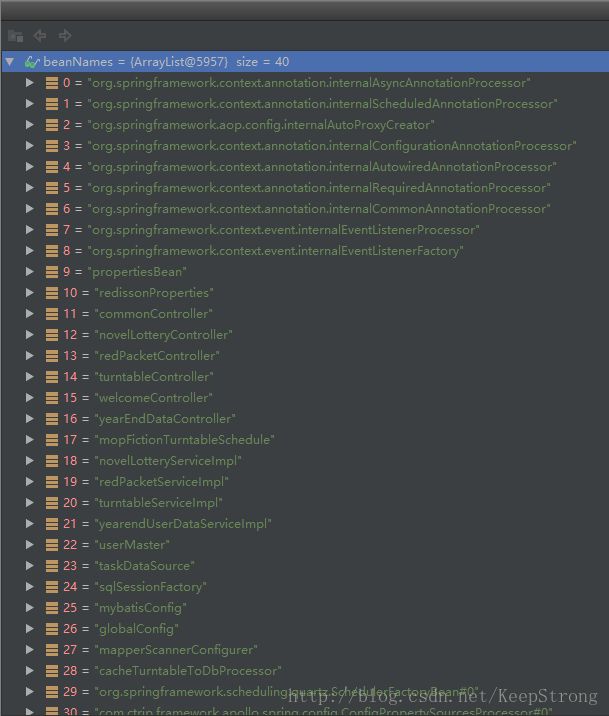
这里面beanNames的list里面存放了即将要初始化的类的顺序。
本地加载顺序:
通过远程断点获得了服务器加载顺序:
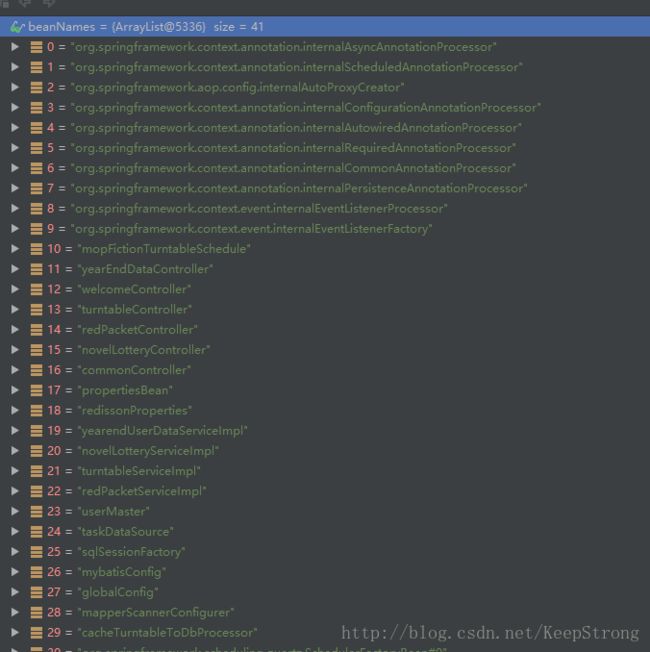
发现两者的加载顺序真的不一样。
带着疑问,继续去研究refresh()的过程。
通过调试发现,this.beanDefinitionNames是在refresh()的ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();完成的。
这一流程主要是完成了对spring配置xml的读取,分析等会需要初始化的类放入this.beanDefinitionNames
可以通过以下步骤跟入
obtainFreshBeanFactory()
->refreshBeanFactory()
->loadBeanDefinitions(beanFactory)属于XmlWebApplicationContext
->reader.loadBeanDefinitions(configLocation)
->loadBeanDefinitions(location, null)
->int loadCount = loadBeanDefinitions(resources)
->counter += loadBeanDefinitions(resource)
->loadBeanDefinitions(new EncodedResource(resource))
->doLoadBeanDefinitions(inputSource, encodedResource.getResource())
->registerBeanDefinitions(doc, resource)
->documentReader.registerBeanDefinitions(doc, createReaderContext(resource))
->doRegisterBeanDefinitions(root)
->parseBeanDefinitions(root, this.delegate)
->delegate.parseCustomElement(root)
->parseCustomElement(ele, null)
->handler.parse(ele, new ParserContext(this.readerContext, this, containingBd))
->findParserForElement(element, parserContext).parse(element, parserContext)
->parse(element, parserContext)属于ComponentScanBeanDefinitionParser
终于到了关键代码了
public BeanDefinition parse(Element element, ParserContext parserContext) {
String basePackage = element.getAttribute(BASE_PACKAGE_ATTRIBUTE);
basePackage = parserContext.getReaderContext().getEnvironment().resolvePlaceholders(basePackage);
String[] basePackages = StringUtils.tokenizeToStringArray(basePackage,
ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS);
// Actually scan for bean definitions and register them.
ClassPathBeanDefinitionScanner scanner = configureScanner(parserContext, element);
Set beanDefinitions = scanner.doScan(basePackages);
registerComponents(parserContext.getReaderContext(), beanDefinitions, element);
return null;
} 关键语句Set
protected Set doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
Set beanDefinitions = new LinkedHashSet();
for (String basePackage : basePackages) {
Set candidates = findCandidateComponents(basePackage);
for (BeanDefinition candidate : candidates) {
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder = AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
} 这一段就是从包名中获得等会要初始化的类。可以看到用的Set
Set的特性是无序不重复。
然后我们继续看一下findCandidateComponents(basePackage);
public Set findCandidateComponents(String basePackage) {
Set candidates = new LinkedHashSet();
try {
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + "/" + this.resourcePattern;
Resource[] resources = this.resourcePatternResolver.getResources(packageSearchPath);
boolean traceEnabled = logger.isTraceEnabled();
boolean debugEnabled = logger.isDebugEnabled();
for (Resource resource : resources) {
if (traceEnabled) {
logger.trace("Scanning " + resource);
}
if (resource.isReadable()) {
try {
MetadataReader metadataReader = this.metadataReaderFactory.getMetadataReader(resource);
if (isCandidateComponent(metadataReader)) {
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setResource(resource);
sbd.setSource(resource);
if (isCandidateComponent(sbd)) {
if (debugEnabled) {
logger.debug("Identified candidate component class: " + resource);
}
candidates.add(sbd);
}
else {
if (debugEnabled) {
logger.debug("Ignored because not a concrete top-level class: " + resource);
}
}
}
else {
if (traceEnabled) {
logger.trace("Ignored because not matching any filter: " + resource);
}
}
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to read candidate component class: " + resource, ex);
}
}
else {
if (traceEnabled) {
logger.trace("Ignored because not readable: " + resource);
}
}
}
}
catch (IOException ex) {
throw new BeanDefinitionStoreException("I/O failure during classpath scanning", ex);
}
return candidates;
} ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
Set
我们需要去寻找它的hashCode方法。
先看一下这个类的继承关系
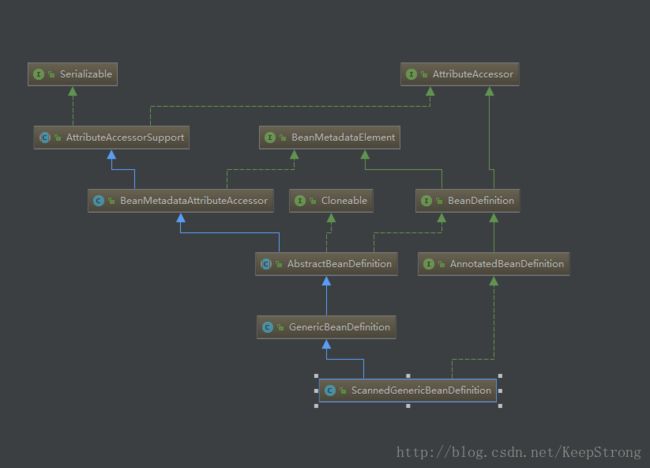
最后终于在AttributeAccessorSupport中找到hashCode方法
public abstract class AttributeAccessorSupport implements AttributeAccessor, Serializable {
/** Map with String keys and Object values */
private final Map attributes = new LinkedHashMap(0);
//多余代码删除
@Override
public int hashCode() {
return this.attributes.hashCode();
}
} 然后查看一下LinkedHashMap的源码,发现并没有hashCode
* @author Josh Bloch
* @see Object#hashCode()
* @see Collection
* @see Map
* @see HashMap
* @see TreeMap
* @see Hashtable
* @since 1.4
*/
public class LinkedHashMap
extends HashMap
implements Map 查看一下Object源码
public native int hashCode();native方法是java调用了本地系统的C函数库实现的。
到此真相大白,随着操作系统的不同,这个native 的hashCode可能会不一样,最终导致了服务器初始化顺序不一致。
最后说一下解决这个bug的思路,只需要让RedissonProperties比MopFictionTurntableSchedule加载早就能决绝问题。
第一个方法
到此问题解决。