hadoop - hadoop2.6 伪分布式 示例 wordcount 分词 和 hdfs常用操作命令
1.背景
上篇已经学习了hadoop伪分布式安装,这篇演示一个例子;更好的理解hdfs 文件系统!
2.hdfs 命令操作
说明:我这里hadoop进行了path 变量配置,所以可以使用 hadoop命令,如果你没有配置的话,看下篇文章进行配置或者 进入 hadoop 根目录 ,使用 bin目录下的hadoop 执行 hdfs 操作;
2.1 fs -ls / 查看目录下的内容
yuan@LABELNET:~$ hadoop fs -ls /user/yuan/inpu
2.2 fs -lsr / 查看目录下的所有内容,递归遍历
yuan@LABELNET:~$ hadoop fs -lsr /user/yuan/
或
yuan@LABELNET:~$ hadoop fs -ls -R /ming/
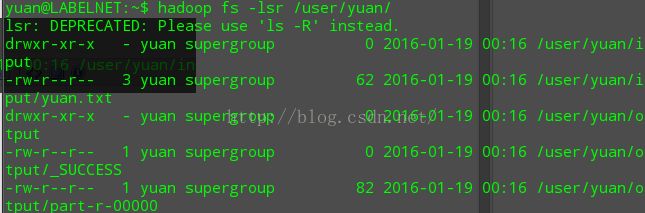
2.3 结果分析
代表是文件的是 [ - ] 开头
-rw-r--r-- 1 yuan supergroup 258 2016-01-21 16:24 /ming/yuan.txt
代表是文件夹开头的是 [ d ]开头
drwxr-xr-x - yuan supergroup 0 2016-01-19 00:16 /user/yuan/input具体含义 自己看下面翻译吧!
其实 ,如果你伪分布式配置好的话,可以在 浏览器中看见 hdfs的文件 :
(1) 查看hdfs文件系统
(2)文件夹 (d 开头的)

(3)文件 (- 开头的)

(4)含义
drwxr-xr-x - yuan supergroup 0 2016-01-19 00:16 input
权限 目录所有者 所属组群 文件大小 时间 目录位置
-rw-r--r-- 1 yuan supergroup 82 2016-01-19 00:16 output/part-r-00000
权限 备份数 所有者 所属组群 大小 时间 文件目录地址
2.4 fs -mkdir /d1 在hdfs上创建d1文件夹
yuan@LABELNET:~$ hadoop fs -mkdir /ming
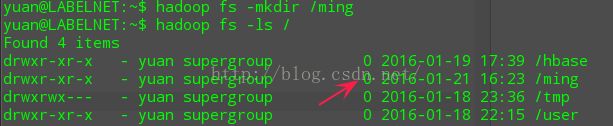
2.5 fs -put [linux 上传文件] [hdfs 目的文件夹]
yuan@LABELNET:~$ hadoop fs -put /home/yuan/桌面/yuan.txt /ming

2.6 fs -get [hdfs 下载文件地址] [linux 目的文件夹]
yuan@LABELNET:~$ hadoop fs -get /ming/yuan.txt ~/Java/

2.7 fs -text hdfs [hdfs 文件地址] 查看hdfs文件
yuan@LABELNET:~$ hadoop fs -text /ming/yuan.txt
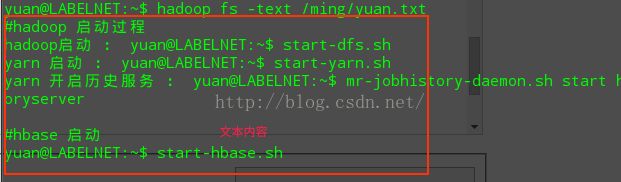
2.8 fs -rm [hdfs 文件地址] 删除文件
yuan@LABELNET:~$ hadoop fs -rm /ming/yuan.txt

2.9 fs -rmr [目录地址] 删除文件
yuan@LABELNET:~$ hadoop fs -rmr /ming
或
yuan@LABELNET:~$ hadoop fs -rm -R /ming

剩下的命令自己学习吧,常用的就这些吧!
3.wordcount 分词 示例
3.1 创建文件夹
yuan@LABELNET:/usr/local/hadoop$ bin/hdfs dfs -mkdir /user/hadoop/input![]()
3.2 上传文件
yuan@LABELNET:/usr/local/hadoop$ bin/hdfs dfs -put yuan.txt /user/hadoop/input
3.3 查看文件
(1) 可以使用命令
yuan@LABELNET:/usr/local/hadoop$ bin/hdfs fs -ls /user/hadoop/input
(2)也可以在浏览器中查看
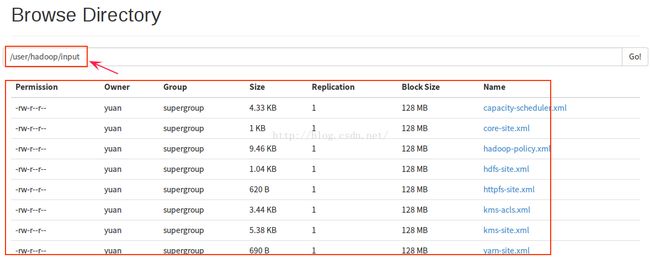
3.4 操作执行
yuan@LABELNET:/usr/local/hadoop$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep /user/hadoop/input output 'dfs[a-z.]+'
执行完毕 :
注意执行前,将Output文件夹 移除:
$ rm -R ./output 或
$ bin/hdfs dfs -rm -r /user/hadoop/output
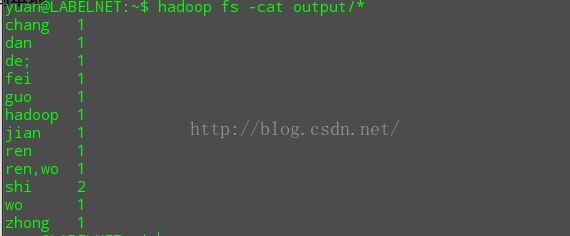
3.5 查看输出
yuan@LABELNET:usr/local/hadoop$ bin/hadoop fs -cat output/*
3.6 将输出的下载到本地
yuan@LABELNET:usr/local/hadoop$ bin/hadoop fs -get output/* ~/Java

3.7 关闭 hadoop
yuan@LABELNET:usr/local/hadoop$ sbin/stop-dfs.sh4.总结
下面配置 hadoop 的全局使用和yarn 配置!