spark 2.4.0源码分析--(二)AppStatusListener与SQLAppStatusListener事件响应及存储
文章目录
- 一、KVStore定义及实现
- 1、InMemoryStore内存方式存储
- 2、ElementTrackingStore中检测超过指定条目的数据,并删除
- 二、AppStatusListener及AppStatusStore
- 1、AppStatusListener实现的接口
- 2、注册Trigger,超过指定条目后,删除冗余数据(重要)
- 3、Spark UI Tab 调用AppStatusStore相关的方法
- 三、SQLAppStatusListener及SQLAppStatusStore
- 1、SQLAppStatusListener
- 2、源码中SparkPlanGraphWrapper数据无限增长的改进
- 3、SQLAppStatusStore
接上一篇文章,LiveListenerBus事件总线分发的event,一个非常重要的目标就是存入AppStatusListener,SQLAppStatusListener内部的kvstore: ElementTrackingStore,用于Spark UI展示 :
- Spark UI中Job、Stage、Task页面,调用AppStatusStore提供的方法,读取kvstore中存储的rdd任务相关信息。
- Spark UI中SQL页面,调用SQLAppStatusStore提供的方法,读取kvstore中存储的SparkPlan物理计划(SQL真实执行流程)相关信息。
一、KVStore定义及实现
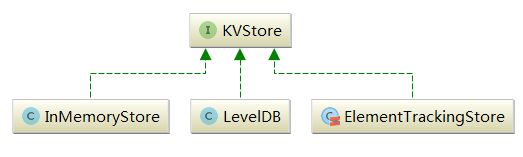
KVStore是一个特质,定义了数据的读、写、删除、count()计算总数等方法,其两个重要的实现是InMemoryStore和ElementTrackingStore
1、InMemoryStore内存方式存储
- InMemoryStore内部定义了数据结构:
ConcurrentMap - 上述data是围绕记录的class类型进行分类存储。
InstanceList内部保存了某个对应class数据的多条信息,例如UI默认展示的1000个Stage信息,其调用顺序AppStatusStore.stageList(xxx) —> store.view(classOf[StageDataWrapper]) - store.view(xxx)方法返回的是KVStoreView的子类InMemoryView(),可以对InstanceList内部的数据进行排序,也就是我们在UI中看到的最新Stage信息总在最前
- 在调用InMemoryView iterator()方法时,会先将内部elements数据进行排序,并根据设置的first、last、skip信息对sorted数据进行过滤,最后返回一个InMemoryIterator
public class InMemoryStore implements KVStore {
...
private ConcurrentMap, InstanceList> data = new ConcurrentHashMap<>();
// 统计某一class数据总量,例如store.count(classOf[SQLExecutionUIData])统计运行的SQL总量
@Override
public long count(Class type) {
InstanceList list = data.get(type);
return list != null ? list.size() : 0;
}
// 某一对象的数据量,例如store.count(classOf[TaskDataWrapper], "stage", Array(stageId, stageAttemptId))获取某个stage的task总数
@Override
public long count(Class type, String index, Object indexedValue) throws Exception {
InstanceList list = data.get(type);
int count = 0;
Object comparable = asKey(indexedValue);
KVTypeInfo.Accessor accessor = list.getIndexAccessor(index);
for (Object o : view(type)) {
if (Objects.equal(comparable, asKey(accessor.get(o)))) {
count++;
}
}
return count;
}
// 获取某一class指定key数据,例如:store.read(classOf[SQLExecutionUIData], executionId)获取指定executionId的SQL运行描述detail
@Override
public T read(Class klass, Object naturalKey) {
InstanceList list = data.get(klass);
Object value = list != null ? list.get(naturalKey) : null;
if (value == null) {
throw new NoSuchElementException();
}
return klass.cast(value);
}
// 写入一条数据,先获取数据的class,不存在则先创建class对应的数据列表InstanceList
@Override
public void write(Object value) throws Exception {
InstanceList list = data.computeIfAbsent(value.getClass(), key -> {
try {
return new InstanceList(key);
} catch (Exception e) {
throw Throwables.propagate(e);
}
});
list.put(value);
}
//删除一条数据,例如kvstore.delete(t.getClass(), t.taskId)
@Override
public void delete(Class type, Object naturalKey) {
InstanceList list = data.get(type);
if (list != null) {
list.delete(naturalKey);
}
}
// 查看某个类对应的全部数据,返回InMemoryView排序后迭代器
@Override
public KVStoreView view(Class type){
InstanceList list = data.get(type);
return list != null ? list.view(type)
: new InMemoryView<>(type, Collections.emptyList(), null);
}
}
2、ElementTrackingStore中检测超过指定条目的数据,并删除
由ElementTrackingStore的代码可知,其主要代理其内部store: InMemorySotre的方法,并提供数据删除功能
private[spark] class ElementTrackingStore(store: KVStore, conf: SparkConf) extends KVStore {
def write(value: Any, checkTriggers: Boolean): Unit = {
write(value)
if (checkTriggers && !stopped) {
triggers.get(value.getClass()).foreach { list =>
doAsync {
val count = store.count(value.getClass())
list.foreach { t =>
if (count > t.threshold) {
t.action(count)
}
}
}
}
}
}
override def delete(klass: Class[_], naturalKey: Any): Unit = store.delete(klass, naturalKey)
override def getMetadata[T](klass: Class[T]): T = store.getMetadata(klass)
override def setMetadata(value: Any): Unit = store.setMetadata(value)
override def view[T](klass: Class[T]): KVStoreView[T] = store.view(klass)
override def count(klass: Class[_]): Long = store.count(klass)
override def count(klass: Class[_], index: String, indexedValue: Any): Long = {
store.count(klass, index, indexedValue)
}
}
二、AppStatusListener及AppStatusStore
在SparkContext中创建AppStatus存储体系:
_statusStore = AppStatusStore.createLiveStore(conf) listenerBus.addToStatusQueue(_statusStore.listener.get)
object AppStatusStore {
def createLiveStore(conf: SparkConf): AppStatusStore = {
val store = new ElementTrackingStore(new InMemoryStore(), conf)
val listener = new AppStatusListener(store, conf, true)
new AppStatusStore(store, listener = Some(listener))
}
}
1、AppStatusListener实现的接口
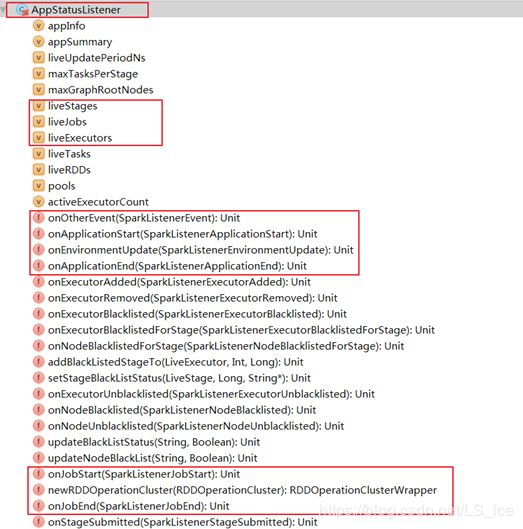
上述图中live相关的成员变量,一般表示任务已启动,尚未结束,临时的存储,例如onJobStart(xxx)调用时,存储到liveJobs中,onJobEnd(xxx)调用时,job信息从liveJobs中删除,存入kvStore
private[spark] class AppStatusListener(
kvstore: ElementTrackingStore,
...
live: Boolean) extends SparkListener with Logging {
override def onJobEnd(event: SparkListenerJobEnd): Unit = {
liveJobs.remove(event.jobId).foreach { job =>
val now = System.nanoTime()
// Check if there are any pending stages that match this job; mark those as skipped.
val it = liveStages.entrySet.iterator()
while (it.hasNext()) {
val e = it.next()
if (job.stageIds.contains(e.getKey()._1)) {
val stage = e.getValue()
if (v1.StageStatus.PENDING.equals(stage.status)) {
stage.status = v1.StageStatus.SKIPPED
job.skippedStages += stage.info.stageId
job.skippedTasks += stage.info.numTasks
job.activeStages -= 1
pools.get(stage.schedulingPool).foreach { pool =>
pool.stageIds = pool.stageIds - stage.info.stageId
update(pool, now)
}
it.remove()
update(stage, now, last = true)
}
}
}
job.status = event.jobResult match {
case JobSucceeded => JobExecutionStatus.SUCCEEDED
case JobFailed(_) => JobExecutionStatus.FAILED
}
job.completionTime = if (event.time > 0) Some(new Date(event.time)) else None
update(job, now, last = true)
if (job.status == JobExecutionStatus.SUCCEEDED) {
appSummary = new AppSummary(appSummary.numCompletedJobs + 1, appSummary.numCompletedStages)
kvstore.write(appSummary)
}
}
}
override def onEnvironmentUpdate(event: SparkListenerEnvironmentUpdate): Unit = {
val details = event.environmentDetails
val jvmInfo = Map(details("JVM Information"): _*)
val runtime = new v1.RuntimeInfo(
jvmInfo.get("Java Version").orNull,
jvmInfo.get("Java Home").orNull,
jvmInfo.get("Scala Version").orNull)
val envInfo = new v1.ApplicationEnvironmentInfo(
runtime,
details.getOrElse("Spark Properties", Nil),
details.getOrElse("System Properties", Nil),
details.getOrElse("Classpath Entries", Nil))
coresPerTask = envInfo.sparkProperties.toMap.get("spark.task.cpus").map(_.toInt)
.getOrElse(coresPerTask)
kvstore.write(new ApplicationEnvironmentInfoWrapper(envInfo))
}
}
类中kvstore.write(new ApplicationEnvironmentInfoWrapper(envInfo))或update(xxx)相关的方法均会调用kvstore进行存储:
private[spark] class AppStatusListener(
kvstore: ElementTrackingStore,
...
live: Boolean) extends SparkListener with Logging {
private def update(entity: LiveEntity, now: Long, last: Boolean = false): Unit = {
entity.write(kvstore, now, checkTriggers = last)
}
}
2、注册Trigger,超过指定条目后,删除冗余数据(重要)
I、Trigger在AppStatusListener中向kvStore注册
private[spark] class AppStatusListener(
kvstore: ElementTrackingStore,
...
live: Boolean) extends SparkListener with Logging {
kvstore.addTrigger(classOf[ExecutorSummaryWrapper], conf.get(MAX_RETAINED_DEAD_EXECUTORS))
{ count => cleanupExecutors(count) }
kvstore.addTrigger(classOf[JobDataWrapper], conf.get(MAX_RETAINED_JOBS)) { count =>
cleanupJobs(count)
}
kvstore.addTrigger(classOf[StageDataWrapper], conf.get(MAX_RETAINED_STAGES)) { count =>
cleanupStages(count)
}
}
3、Spark UI Tab 调用AppStatusStore相关的方法
AppStatusStore主要是一个方法包装的类,从store中获取数据,处理后返回给Spark UI体系中提供的各种UI Tab,进行数据展示:
private[spark] class AppStatusStore(
val store: KVStore,
val listener: Option[AppStatusListener] = None) {
def applicationInfo(): v1.ApplicationInfo = {
store.view(classOf[ApplicationInfoWrapper]).max(1).iterator().next().info
}
def environmentInfo(): v1.ApplicationEnvironmentInfo = {
val klass = classOf[ApplicationEnvironmentInfoWrapper]
store.read(klass, klass.getName()).info
}
def jobsList(statuses: JList[JobExecutionStatus]): Seq[v1.JobData] = {
val it = store.view(classOf[JobDataWrapper]).reverse().asScala.map(_.info)
if (statuses != null && !statuses.isEmpty()) {
it.filter { job => statuses.contains(job.status) }.toSeq
} else {
it.toSeq
}
}
...
}
三、SQLAppStatusListener及SQLAppStatusStore
在sparkContex成员shareState中创建SQLAppStatusStore,注意kvStore和AppStatusStore共用:
private[sql] class SharedState(val sparkContext: SparkContext) extends Logging {
val statusStore: SQLAppStatusStore = {
val kvStore = sparkContext.statusStore.store.asInstanceOf[ElementTrackingStore]
val listener = new SQLAppStatusListener(sparkContext.conf, kvStore, live = true)
sparkContext.listenerBus.addToStatusQueue(listener)
val statusStore = new SQLAppStatusStore(kvStore, Some(listener))
sparkContext.ui.foreach(new SQLTab(statusStore, _))
statusStore
}
}
SQLAppStatusListener及SQLAppStatusStore与本文第二章节介绍的AppStatus相关逻辑十分类似,这里我们介绍一些额外的信息:
1、SQLAppStatusListener
接上篇文章SQLExecution.withNewExecutionId(xxx)跟踪sql执行生命周期,提交SparkListenerSQLExecutionStart 、SparkListenerSQLExecutionEnd 事件,其处理逻辑:

class SQLAppStatusListener(
conf: SparkConf,
kvstore: ElementTrackingStore,
live: Boolean) extends SparkListener with Logging {
override def onOtherEvent(event: SparkListenerEvent): Unit = event match {
case e: SparkListenerSQLExecutionStart => onExecutionStart(e)
case e: SparkListenerSQLExecutionEnd => onExecutionEnd(e)
case e: SparkListenerDriverAccumUpdates => onDriverAccumUpdates(e)
case _ => // Ignore
}
private def onExecutionStart(event: SparkListenerSQLExecutionStart): Unit = {
val SparkListenerSQLExecutionStart(executionId, description, details,
physicalPlanDescription, sparkPlanInfo, time) = event
def toStoredNodes(nodes: Seq[SparkPlanGraphNode]): Seq[SparkPlanGraphNodeWrapper] = {
nodes.map {
case cluster: SparkPlanGraphCluster =>
val storedCluster = new SparkPlanGraphClusterWrapper(
cluster.id,
cluster.name,
cluster.desc,
toStoredNodes(cluster.nodes),
cluster.metrics)
new SparkPlanGraphNodeWrapper(null, storedCluster)
case node =>
new SparkPlanGraphNodeWrapper(node, null)
}
}
val planGraph = SparkPlanGraph(sparkPlanInfo)
val sqlPlanMetrics = planGraph.allNodes.flatMap { node =>
node.metrics.map { metric => (metric.accumulatorId, metric) }
}.toMap.values.toList
val graphToStore = new SparkPlanGraphWrapper(
executionId,
toStoredNodes(planGraph.nodes),
planGraph.edges)
kvstore.write(graphToStore)
// 创建LiveExecutionData,放入liveExecutions列表中
val exec = getOrCreateExecution(executionId)
exec.description = description
exec.details = details
exec.physicalPlanDescription = physicalPlanDescription
exec.metrics = sqlPlanMetrics
exec.submissionTime = time
update(exec)
}
private def onExecutionEnd(event: SparkListenerSQLExecutionEnd): Unit = {
val SparkListenerSQLExecutionEnd(executionId, time) = event
// 从liveExecutions从查找LiveExecutionData
Option(liveExecutions.get(executionId)).foreach { exec =>
exec
exec.metricsValues = aggregateMetrics(exec)
exec.completionTime = Some(new Date(time))
exec.endEvents += 1
// 调用update方法将LiveExecutionData写入kvStore,其内部是调用exec.write(kvstore, now),即LiveEntity.write()方法,注意LiveEntiy内部有个doUpdate()方法需要子类实现,这里可以创建SQLExecutionUIData
update(exec)
// Remove stale LiveStageMetrics objects for stages that are not active anymore.
val activeStages = liveExecutions.values().asScala.flatMap { other =>
if (other != exec) other.stages else Nil
}.toSet
stageMetrics.keySet().asScala
.filter(!activeStages.contains(_))
.foreach(stageMetrics.remove)
}
}
}
2、源码中SparkPlanGraphWrapper数据无限增长的改进
- 由于2.4.0源码中只对SQLExecutionUIData增加了数据删除的Trigger,而SparkPlanGraphWrapper无数据删除机制,导致持续运行的流计算会无限创建SparkPlanGraphWrapper导致内存泄漏
- 场景:7x24小时运行spark structrued streaming(micro batch),每分钟提交10次withNewExecutionID(xxx),触发onExecutionStart()无限创建SparkPlanGraphWrapper,以下是增加对应的Trigger
class SQLAppStatusListener(
conf: SparkConf,
kvstore: ElementTrackingStore,
live: Boolean) extends SparkListener with Logging {
kvstore.addTrigger(classOf[SQLExecutionUIData], conf.get(UI_RETAINED_EXECUTIONS)) { count =>
cleanupExecutions(count)
}
kvstore.addTrigger(
classOf[SparkPlanGraphWrapper], conf.get(UI_RETAINED_SPARK_PLAN_GRAPH)) { count =>
cleanSparkPlanGraphWrapper(count)
}
}
3、SQLAppStatusStore
SQLAppStatusStore代码较少,其主要围绕SQLExecutionUIData、SparkPlanGraphWrapper进行Sql执行数据的展示
class SQLAppStatusStore(
store: KVStore,
val listener: Option[SQLAppStatusListener] = None) {
def executionsList(): Seq[SQLExecutionUIData] = {
store.view(classOf[SQLExecutionUIData]).asScala.toSeq
}
def execution(executionId: Long): Option[SQLExecutionUIData] = {
try {
Some(store.read(classOf[SQLExecutionUIData], executionId))
} catch {
case _: NoSuchElementException => None
}
}
def executionsCount(): Long = {
store.count(classOf[SQLExecutionUIData])
}
def planGraphCount(): Long = {
store.count(classOf[SparkPlanGraphWrapper])
}
def executionMetrics(executionId: Long): Map[Long, String] = {
def metricsFromStore(): Option[Map[Long, String]] = {
val exec = store.read(classOf[SQLExecutionUIData], executionId)
Option(exec.metricValues)
}
metricsFromStore()
.orElse(listener.flatMap(_.liveExecutionMetrics(executionId)))
// Try a second time in case the execution finished while this method is trying to
// get the metrics.
.orElse(metricsFromStore())
.getOrElse(Map())
}
def planGraph(executionId: Long): SparkPlanGraph = {
store.read(classOf[SparkPlanGraphWrapper], executionId).toSparkPlanGraph()
}
}
class SQLExecutionUIData(
@KVIndexParam val executionId: Long,
val description: String,
val details: String,
val physicalPlanDescription: String,
val metrics: Seq[SQLPlanMetric],
val submissionTime: Long,
val completionTime: Option[Date],
@JsonDeserialize(keyAs = classOf[Integer])
val jobs: Map[Int, JobExecutionStatus],
@JsonDeserialize(contentAs = classOf[Integer])
val stages: Set[Int],
/**
* This field is only populated after the execution is finished; it will be null while the
* execution is still running. During execution, aggregate metrics need to be retrieved
* from the SQL listener instance.
*/
@JsonDeserialize(keyAs = classOf[JLong])
val metricValues: Map[Long, String]) {
@JsonIgnore @KVIndex("completionTime")
private def completionTimeIndex: Long = completionTime.map(_.getTime).getOrElse(-1L)
}
class SparkPlanGraphWrapper(
@KVIndexParam val executionId: Long,
val nodes: Seq[SparkPlanGraphNodeWrapper],
val edges: Seq[SparkPlanGraphEdge]) {
def toSparkPlanGraph(): SparkPlanGraph = {
SparkPlanGraph(nodes.map(_.toSparkPlanGraphNode()), edges)
}
@JsonIgnore @KVIndex("completionTime")
private def completionTimeIndex: Long = executionId
}