[OpenCV实战]17 基于卷积神经网络的OpenCV图像着色
目录
1 彩色图像着色
1.1 定义着色问题
1.2 CNN彩色化结构
1.3 从 中恢复彩色图像
1.4 具有颜色再平衡的多项式损失函数
1.5 着色结果
2 OpenCV中实现着色
2.1 模型下载
2.2 加载量化信息
2.3 将图像转换为CIE Lab颜色空间
3 代码
3.1 图像着色代码
3.2 视频着色代码
4 参考
技术有时会提高艺术,但有时也会破坏艺术。着色黑白电影是一个可以追溯到1902年的古老想法。几十年来,许多电影创作者反对将黑白电影着色的想法,并将其视为对艺术的破坏。但今天它被接受为艺术形式的增强。该技术本身已经从艰苦的手工着色转变为如今的自动化技术。如下图所示。
![[OpenCV实战]17 基于卷积神经网络的OpenCV图像着色_第1张图片](http://img.e-com-net.com/image/info8/8f56a4239db940ac8fd9a903ef22fbf2.jpg)
基于传统的计算机视觉方法以及发表了许多关于图像着色的论文。我最喜欢的一篇文章是名为Colorization using Optimization的论文。它使用了一些彩色涂鸦来指导解决着色的优化问题。论文见https://www.cs.huji.ac.il/~yweiss/Colorization/
如果算法不需要用户输入任何参数,这不是很酷的事情吗?在过去几年中,随着深度学习的发展,着色自动化取得了巨大的飞跃。在这篇文章中,我们将了解一个这样的着色深度学习模型。我们还共享OpenCV代码,以便在Python或C ++应用程序中使用经过训练的模型。
1 彩色图像着色
在ECCV 2016中,一篇名为Colorful Image Colorization的论文,提出了一个用于着色灰度图像的卷积神经网络。论文使用ImageNet训练集的130万像素训练网络,并公开了一个训练好的基于Caffe的模型。在这篇文章中,我们将首先定义着色问题,解释论文的架构细节,最后分享代码和一些有趣的结果。
论文原文:http://videolectures.net/eccv2016_zhang_image_colorization/
1.1 定义着色问题
我们首先根据CIE Lab颜色空间定义颜色问题。与RGB颜色空间一样,它是3通道颜色空间,但与RGB颜色空间不同,颜色信息仅在a(绿红分量)和b(蓝黄分量)通道中编码。L(亮度)通道仅对亮度信息进行编码。
我们想要着色的灰度图像可以被认为是Lab颜色空间中图像的L通道,我们的目标是找到a和b分量。可以使用标准颜色空间变换将该Lab图像变换为RGB颜色图像。例如,在OpenCV中,这可以使用COLOR_BGR2Lab选项的cvtColor来实现。
为了简化计算,Lab颜色空间的ab空间进行312级量化,如图2所示。OpenCV会映射到0到312,由于这种量化我们只需找到0到312的数,而不是找到每个像素的a和b值。另一种思考问题的方法是我们已经有一个L通道,取值从0到255,我们需要找到一个取0到312之间值的ab通道。所以颜色预测任务现在是变成了多项分类问题,每个灰色像素有313个类可供选择。
![[OpenCV实战]17 基于卷积神经网络的OpenCV图像着色_第2张图片](http://img.e-com-net.com/image/info8/3a6cb3ef26294827a3369b2a61ee92c7.jpg)
1.2 CNN彩色化结构
Colorful Image Colorization这篇论文使用的CNN结构如下所示。类似与VGG网络,但是该CNN没有池化层或全连接层。
![[OpenCV实战]17 基于卷积神经网络的OpenCV图像着色_第3张图片](http://img.e-com-net.com/image/info8/8a9ff6d41554467d97b4d2873a61c438.jpg)
输入图像缩放为224×224,缩放后的灰度输入图像表示为X。当它通过上面显示的神经网络时,输出为:
![]()
![]() 的尺寸为H×W×Q,其中H=56和W=56是最后一个卷积层输出的高度和宽度。Q=313表示类别个数。对于每个H×W都有一个对应的值表示属于该类的概率。我们的目标是为每个概率分布
的尺寸为H×W×Q,其中H=56和W=56是最后一个卷积层输出的高度和宽度。Q=313表示类别个数。对于每个H×W都有一个对应的值表示属于该类的概率。我们的目标是为每个概率分布![]() 找到其对应的ab通道值。
找到其对应的ab通道值。
1.3 从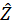 中恢复彩色图像
中恢复彩色图像
让我们看看如何从输出 恢复其对应的ab值。您可能会想到我们可以简单地采用 ![]() 各个量化级别的均值,并获取与其对应的ab值。不幸的是,由于
各个量化级别的均值,并获取与其对应的ab值。不幸的是,由于 ![]() 的各个量化级别分布不是高斯分布,分布的均值简单地对应于去饱和色。要理解这一点,想想天空的颜色有时是蓝色,有时是橙黄色。天空的颜色分布是双峰的。在着色天空时,无论是蓝色还是黄色都会产生合理的色彩。但蓝色和黄色的平均值是无趣的灰色。
的各个量化级别分布不是高斯分布,分布的均值简单地对应于去饱和色。要理解这一点,想想天空的颜色有时是蓝色,有时是橙黄色。天空的颜色分布是双峰的。在着色天空时,无论是蓝色还是黄色都会产生合理的色彩。但蓝色和黄色的平均值是无趣的灰色。
那么为什么不使用 ![]() 的值分布特点让你得到蓝色或黄色的天空?当然,作者尝试了这一点,虽然它给出了鲜艳的色彩,但它有时会破坏空间的一致性。他们的解决方案是在
的值分布特点让你得到蓝色或黄色的天空?当然,作者尝试了这一点,虽然它给出了鲜艳的色彩,但它有时会破坏空间的一致性。他们的解决方案是在 ![]() 的均值和期输出值之间进行插值,以获得称为annealed-mean的量。称为温度(T)的参数用于控制插值程度。最终值T=0.38用作最优插值。
的均值和期输出值之间进行插值,以获得称为annealed-mean的量。称为温度(T)的参数用于控制插值程度。最终值T=0.38用作最优插值。
![[OpenCV实战]17 基于卷积神经网络的OpenCV图像着色_第4张图片](http://img.e-com-net.com/image/info8/15ec1b36965b47b4bd8450beb32c9e9d.jpg)
ab值所对应的annealed-mean值表示为 ![]() ,
, ![]() 与
与![]() 关系为:
关系为:
![]()
请注意,当图像通过CNN时,其大小减小到56×56。因此,预测的ab图像也具有56×56的尺寸。为了获得彩色图像,将其上采样到原始图像尺寸,然后添加到亮度通道L,以产生最终彩色图像。
1.4 具有颜色再平衡的多项式损失函数
通过定义损失函数来训练所有神经网络。培训过程的目标是最大限度地减少训练集的损失。在着色问题中,训练数据由数千个彩色图像及其灰度图组成。
CNN输入图像x对应的输出为 ![]() 。我们需要将训练集中的所有彩色图像转换为并获得相应的
。我们需要将训练集中的所有彩色图像转换为并获得相应的 ![]() 值。在数学上,我们只想反转映射H。即
值。在数学上,我们只想反转映射H。即
![]()
对于Y我们可以简单地找到与其对应的ab值并表示为Z,由于ab是量化后的值,因此Y对应的ab值为1,其他312个值为0。但是为了获得更好的结果,使用高斯分布来计算 ![]() 。
。
所以通过原始图像ab值Z和 ![]() 计算loss。
计算loss。

不幸的是,上述损失函数产生非常暗淡的颜色。这是因为ImageNet中的颜色分布与灰度图值分布接近。
为了推动算法产生鲜艳的色彩,作者将损失函数改为

其中颜色再平衡参数 ![]() 表示根据颜色等级的稀有度重新平衡损失。这有助于在输出中获得更加生动和饱和的色彩。
表示根据颜色等级的稀有度重新平衡损失。这有助于在输出中获得更加生动和饱和的色彩。
说实话由于原文实在解释太坑的。其实模型思路很简单,输入灰度图,输出ab值的概率图Z,然后将ab映射到ab估计值图Y,使得结果更加合理。由于有了灰度图也就是输入,输出就是我们由彩色图原图转换而来的ab值图。计算loss,调整模型就行了。
详细解释可以看:
https://blog.csdn.net/qq_16137569/article/details/83859156
1.5 着色结果
作者分享了两种版本的训练好的Caffe模型,有无色彩再平衡。我们尝试了两个版本,并在下图中分享了结果。中间列显示没有颜色重新平衡的版本,最后一列显示具有重新平衡的版本。正如我们所看到的,色彩重新平衡使许多图像非常生动和充满活力。大多数都是合理的颜色。另一方面,有时它也可能会为某些图像添加一些不需要的饱和色块。
请记住,当我们尝试将灰度图像转换为彩色图像时,可能会有多种合理的解决方案。因此,评估良好着色的方法并不是它与真实图像的匹配程度,而是它的颜色让人看起来多么合理和令人愉悦。
1)动物
该模型非常适合动物的图像,尤其是猫和狗。这是因为ImageNet包含了大量这些动物。
![[OpenCV实战]17 基于卷积神经网络的OpenCV图像着色_第5张图片](http://img.e-com-net.com/image/info8/943aac3fbeae4ea6b05393c89ef47b87.jpg)
![[OpenCV实战]17 基于卷积神经网络的OpenCV图像着色_第6张图片](http://img.e-com-net.com/image/info8/7fb86ad802be4981819eccfa872d425b.jpg)
2)户外场景
该模型也很好地展示了蓝天和绿色植被的户外场景。还要注意,模型能够重新着色橙色天空,表明它已经获得了日落的特征。
![[OpenCV实战]17 基于卷积神经网络的OpenCV图像着色_第7张图片](http://img.e-com-net.com/image/info8/c4e152e921a2404fb96571ab152a7936.jpg)
![[OpenCV实战]17 基于卷积神经网络的OpenCV图像着色_第8张图片](http://img.e-com-net.com/image/info8/0ac970d4eb6c44ccbdf190215fdcc34c.jpg)
![[OpenCV实战]17 基于卷积神经网络的OpenCV图像着色_第9张图片](http://img.e-com-net.com/image/info8/bd844ec5f70f46bca5eee6ff15ffbf78.jpg)
![[OpenCV实战]17 基于卷积神经网络的OpenCV图像着色_第10张图片](http://img.e-com-net.com/image/info8/504b942561d0439da3d12cafc393cb32.jpg)
3)手绘
最后,即使使用手绘草图,该模型也会产生合理的着色。
![[OpenCV实战]17 基于卷积神经网络的OpenCV图像着色_第11张图片](http://img.e-com-net.com/image/info8/910bdf149eb44179bb036a3eb803094c.jpg)
![[OpenCV实战]17 基于卷积神经网络的OpenCV图像着色_第12张图片](http://img.e-com-net.com/image/info8/059af6bafd344c2ebb4b70a44018cc73.jpg)
![[OpenCV实战]17 基于卷积神经网络的OpenCV图像着色_第13张图片](http://img.e-com-net.com/image/info8/e837f3d01abb46538b790b1f04e6e8c3.jpg)
2 OpenCV中实现着色
作者在其GitHub中提供了预先训练的模型和网络详细信息。
地址:https://github.com/richzhang/colorization
2.1 模型下载
下面,我们将介绍在OpenCV(3.4.1以上)基于Python和C++,使用这些预先训练的模型为给定的灰度图像和灰度视频着色。
模型下载地址:
http://eecs.berkeley.edu/~rich.zhang/projects/2016_colorization/files/demo_v2/colorization_release_v2.caffemodel
http://eecs.berkeley.edu/~rich.zhang/projects/2016_colorization/files/demo_v2/colorization_release_v2_norebal.caffemodel
其中colorization_release_v2.caffemodel颜色再平衡 后训练的模型,colorization_release_v2_norebal.caffemodel是没有加颜色再平衡的模型。
另外python版本需要加载pts_in_hull.py文件,该文件包含ab空间的量化信息。在C++版本中,量化信息是从pts_in_hull.py复制的。
C++代码:
string imageFileName = "./image/greyscaleImage.png";
Mat img = imread(imageFileName);
if (img.empty())
{
cout << "Can't read image from file: " << imageFileName << endl;
return 2;
}
string protoFile = "./model/colorization_deploy_v2.prototxt";
string weightsFile = "./model/colorization_release_v2.caffemodel";
//string weightsFile = "./model/colorization_release_v2_norebal.caffemodel";
double t = (double)cv::getTickCount();
// fixed input size for the pretrained network 加载模型
const int W_in = 224;
const int H_in = 224;
Net net = dnn::readNetFromCaffe(protoFile, weightsFile);python:
# Specify the paths for the model files
protoFile = "./models/colorization_deploy_v2.prototxt"
weightsFile = "./models/colorization_release_v2.caffemodel"
#weightsFile = "./models/colorization_release_v2_norebal.caffemodel";
# Read the input image
frame = cv.imread("./dog-greyscale.png")
W_in = 224
H_in = 224
# Read the network into Memory
net = cv.dnn.readNetFromCaffe(protoFile, weightsFile) 2.2 加载量化信息
接下来,我们加载量化分级信息。然后就是对输出进行变换。最后,我们添加一个非零值的缩放图层。
c++代码:
// setup additional layers 在网络里额外添加两层
int sz[] = { 2, 313, 1, 1 };
//添加一个ab转换层
const Mat pts_in_hull(4, sz, CV_32F, hull_pts);
Ptr class8_ab = net.getLayer("class8_ab");
class8_ab->blobs.push_back(pts_in_hull);
//一个防止为输出为0的层
Ptr conv8_313_rh = net.getLayer("conv8_313_rh");
conv8_313_rh->blobs.push_back(Mat(1, 313, CV_32F, Scalar(2.606))); python代码:
# Load the bin centers
pts_in_hull = np.load('./pts_in_hull.npy')
# populate cluster centers as 1x1 convolution kernel
pts_in_hull = pts_in_hull.transpose().reshape(2, 313, 1, 1)
net.getLayer(net.getLayerId('class8_ab')).blobs = [pts_in_hull.astype(np.float32)]
net.getLayer(net.getLayerId('conv8_313_rh')).blobs = [np.full([1, 313], 2.606, np.float32)]2.3 将图像转换为CIE Lab颜色空间
缩放输入RGB图像,使得值在0-1范围内,然后将其转换为Lab颜色空间,并提取出亮度通道。原始图像中的亮度通道的大小调整为网络输入大小,在这种情况下为(224,224)。通常,亮度通道的范围从0到100.因此我们减去50以0点对称。然后我们将缩放和平均居中的亮度送到网络作为前向通道的输入。前向传递的输出是图像的预测ab通道。将其缩放回原始图像大小,然后与原始大小的亮度图像(在原始分辨率中较早提取)合并,以获得输出Lab图像。然后将其转换为RGB色彩空间以获得最终的彩色图像,并保存输出图像。
C++代码:
// extract L channel and subtract mean 将原图转换为Lab空间图,并归一化
Mat lab, L, input;
img.convertTo(img, CV_32F, 1.0 / 255);
cvtColor(img, lab, COLOR_BGR2Lab);
//提取亮度信息
extractChannel(lab, L, 0);
//重置大小
resize(L, input, Size(W_in, H_in));
input -= 50;
// run the L channel through the network 获得网络输出结果
Mat inputBlob = blobFromImage(input);
net.setInput(inputBlob);
Mat result = net.forward();
// retrieve the calculated a,b channels from the network output
Size siz(result.size[2], result.size[3]);
//输出为56X56
Mat a = Mat(siz, CV_32F, result.ptr(0, 0));
Mat b = Mat(siz, CV_32F, result.ptr(0, 1));
//重置大小
resize(a, a, img.size());
resize(b, b, img.size());
// merge, and convert back to BGR 合并lab,转换为RGB图像
Mat color, chn[] = { L, a, b };
merge(chn, 3, lab);
cvtColor(lab, color, COLOR_Lab2BGR);python版本:
img_rgb = (frame[:,:,[2, 1, 0]] * 1.0 / 255).astype(np.float32)
img_lab = cv.cvtColor(img_rgb, cv.COLOR_RGB2Lab)
img_l = img_lab[:,:,0] # pull out L channel
# resize lightness channel to network input size
img_l_rs = cv.resize(img_l, (W_in, H_in)) #
img_l_rs -= 50 # subtract 50 for mean-centering
net.setInput(cv.dnn.blobFromImage(img_l_rs))
ab_dec = net.forward()[0,:,:,:].transpose((1,2,0)) # this is our result
(H_orig,W_orig) = img_rgb.shape[:2] # original image size
ab_dec_us = cv.resize(ab_dec, (W_orig, H_orig))
img_lab_out = np.concatenate((img_l[:,:,np.newaxis],ab_dec_us),axis=2) # concatenate with original image L
img_bgr_out = np.clip(cv.cvtColor(img_lab_out, cv.COLOR_Lab2BGR), 0, 1)3 代码
算法速度很快,但是我个人觉得没加颜色再平衡的效果更好。代码分为图像版本和视频版本。但是总体效果一般般吧。
代码下载地址:
https://github.com/luohenyueji/OpenCV-Practical-Exercise
3.1 图像着色代码
C++:
// OpenCV_Colorization.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。
//
#include "pch.h"
#include
#include
#include
#include
#include
using namespace cv;
using namespace cv::dnn;
using namespace std;
// the 313 ab cluster centers from pts_in_hull.npy (already transposed)
static float hull_pts[] =
{
-90., -90., -90., -90., -90., -80., -80., -80., -80., -80., -80., -80., -80., -70., -70., -70., -70., -70., -70., -70., -70.,
-70., -70., -60., -60., -60., -60., -60., -60., -60., -60., -60., -60., -60., -60., -50., -50., -50., -50., -50., -50., -50., -50.,
-50., -50., -50., -50., -50., -50., -40., -40., -40., -40., -40., -40., -40., -40., -40., -40., -40., -40., -40., -40., -40., -30.,
-30., -30., -30., -30., -30., -30., -30., -30., -30., -30., -30., -30., -30., -30., -30., -20., -20., -20., -20., -20., -20., -20.,
-20., -20., -20., -20., -20., -20., -20., -20., -20., -10., -10., -10., -10., -10., -10., -10., -10., -10., -10., -10., -10., -10.,
-10., -10., -10., -10., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 10., 10., 10., 10., 10., 10., 10.,
10., 10., 10., 10., 10., 10., 10., 10., 10., 10., 10., 20., 20., 20., 20., 20., 20., 20., 20., 20., 20., 20., 20., 20., 20., 20.,
20., 20., 20., 30., 30., 30., 30., 30., 30., 30., 30., 30., 30., 30., 30., 30., 30., 30., 30., 30., 30., 30., 40., 40., 40., 40.,
40., 40., 40., 40., 40., 40., 40., 40., 40., 40., 40., 40., 40., 40., 40., 40., 50., 50., 50., 50., 50., 50., 50., 50., 50., 50.,
50., 50., 50., 50., 50., 50., 50., 50., 50., 60., 60., 60., 60., 60., 60., 60., 60., 60., 60., 60., 60., 60., 60., 60., 60., 60.,
60., 60., 60., 70., 70., 70., 70., 70., 70., 70., 70., 70., 70., 70., 70., 70., 70., 70., 70., 70., 70., 70., 70., 80., 80., 80.,
80., 80., 80., 80., 80., 80., 80., 80., 80., 80., 80., 80., 80., 80., 80., 80., 90., 90., 90., 90., 90., 90., 90., 90., 90., 90.,
90., 90., 90., 90., 90., 90., 90., 90., 90., 100., 100., 100., 100., 100., 100., 100., 100., 100., 100., 50., 60., 70., 80., 90.,
20., 30., 40., 50., 60., 70., 80., 90., 0., 10., 20., 30., 40., 50., 60., 70., 80., 90., -20., -10., 0., 10., 20., 30., 40., 50.,
60., 70., 80., 90., -30., -20., -10., 0., 10., 20., 30., 40., 50., 60., 70., 80., 90., 100., -40., -30., -20., -10., 0., 10., 20.,
30., 40., 50., 60., 70., 80., 90., 100., -50., -40., -30., -20., -10., 0., 10., 20., 30., 40., 50., 60., 70., 80., 90., 100., -50.,
-40., -30., -20., -10., 0., 10., 20., 30., 40., 50., 60., 70., 80., 90., 100., -60., -50., -40., -30., -20., -10., 0., 10., 20.,
30., 40., 50., 60., 70., 80., 90., 100., -70., -60., -50., -40., -30., -20., -10., 0., 10., 20., 30., 40., 50., 60., 70., 80., 90.,
100., -80., -70., -60., -50., -40., -30., -20., -10., 0., 10., 20., 30., 40., 50., 60., 70., 80., 90., -80., -70., -60., -50.,
-40., -30., -20., -10., 0., 10., 20., 30., 40., 50., 60., 70., 80., 90., -90., -80., -70., -60., -50., -40., -30., -20., -10.,
0., 10., 20., 30., 40., 50., 60., 70., 80., 90., -100., -90., -80., -70., -60., -50., -40., -30., -20., -10., 0., 10., 20., 30.,
40., 50., 60., 70., 80., 90., -100., -90., -80., -70., -60., -50., -40., -30., -20., -10., 0., 10., 20., 30., 40., 50., 60., 70.,
80., -110., -100., -90., -80., -70., -60., -50., -40., -30., -20., -10., 0., 10., 20., 30., 40., 50., 60., 70., 80., -110., -100.,
-90., -80., -70., -60., -50., -40., -30., -20., -10., 0., 10., 20., 30., 40., 50., 60., 70., 80., -110., -100., -90., -80., -70.,
-60., -50., -40., -30., -20., -10., 0., 10., 20., 30., 40., 50., 60., 70., -110., -100., -90., -80., -70., -60., -50., -40., -30.,
-20., -10., 0., 10., 20., 30., 40., 50., 60., 70., -90., -80., -70., -60., -50., -40., -30., -20., -10., 0.
};
int main()
{
string imageFileName = "./image/greyscaleImage.png";
Mat img = imread(imageFileName);
if (img.empty())
{
cout << "Can't read image from file: " << imageFileName << endl;
return 2;
}
string protoFile = "./model/colorization_deploy_v2.prototxt";
string weightsFile = "./model/colorization_release_v2.caffemodel";
//string weightsFile = "./model/colorization_release_v2_norebal.caffemodel";
double t = (double)cv::getTickCount();
// fixed input size for the pretrained network 加载模型
const int W_in = 224;
const int H_in = 224;
Net net = dnn::readNetFromCaffe(protoFile, weightsFile);
// setup additional layers 在网络里额外添加两层
int sz[] = { 2, 313, 1, 1 };
//添加一个ab转换层
const Mat pts_in_hull(4, sz, CV_32F, hull_pts);
Ptr class8_ab = net.getLayer("class8_ab");
class8_ab->blobs.push_back(pts_in_hull);
//一个防止为输出为0的层
Ptr conv8_313_rh = net.getLayer("conv8_313_rh");
conv8_313_rh->blobs.push_back(Mat(1, 313, CV_32F, Scalar(2.606)));
// extract L channel and subtract mean 将原图转换为Lab空间图,并归一化
Mat lab, L, input;
img.convertTo(img, CV_32F, 1.0 / 255);
cvtColor(img, lab, COLOR_BGR2Lab);
//提取亮度信息
extractChannel(lab, L, 0);
//重置大小
resize(L, input, Size(W_in, H_in));
input -= 50;
// run the L channel through the network 获得网络输出结果
Mat inputBlob = blobFromImage(input);
net.setInput(inputBlob);
Mat result = net.forward();
// retrieve the calculated a,b channels from the network output
Size siz(result.size[2], result.size[3]);
//输出为56X56
Mat a = Mat(siz, CV_32F, result.ptr(0, 0));
Mat b = Mat(siz, CV_32F, result.ptr(0, 1));
//重置大小
resize(a, a, img.size());
resize(b, b, img.size());
// merge, and convert back to BGR 合并lab,转换为RGB图像
Mat color, chn[] = { L, a, b };
merge(chn, 3, lab);
cvtColor(lab, color, COLOR_Lab2BGR);
//计算时间
t = ((double)cv::getTickCount() - t) / cv::getTickFrequency();
cout << "Time taken : " << t << " secs" << endl;
//保存图像
string str = imageFileName;
str.replace(str.end() - 4, str.end(), "");
str = str + "_colorized.png";
//反归一化
color = color * 255;
color.convertTo(color, CV_8U);
imwrite(str, color);
cout << "Colorized image saved as " << str << endl;
return 0;
}
python:
import numpy as np
import cv2 as cv
# Read the input image
frame = cv.imread("./image/greyscaleImage.png")
# Specify the paths for the 2 model files
protoFile = "./model/colorization_deploy_v2.prototxt"
weightsFile = "./model/colorization_release_v2.caffemodel"
#weightsFile = "./model/colorization_release_v2_norebal.caffemodel"
# Load the cluster centers
pts_in_hull = np.load('./model/pts_in_hull.npy')
# Read the network into Memory
net = cv.dnn.readNetFromCaffe(protoFile, weightsFile)
# populate cluster centers as 1x1 convolution kernel
pts_in_hull = pts_in_hull.transpose().reshape(2, 313, 1, 1)
net.getLayer(net.getLayerId('class8_ab')).blobs = [pts_in_hull.astype(np.float32)]
net.getLayer(net.getLayerId('conv8_313_rh')).blobs = [np.full([1, 313], 2.606, np.float32)]
#from opencv sample
W_in = 224
H_in = 224
img_rgb = (frame[:,:,[2, 1, 0]] * 1.0 / 255).astype(np.float32)
img_lab = cv.cvtColor(img_rgb, cv.COLOR_RGB2Lab)
img_l = img_lab[:,:,0] # pull out L channel
# resize lightness channel to network input size
img_l_rs = cv.resize(img_l, (W_in, H_in)) #
img_l_rs -= 50 # subtract 50 for mean-centering
net.setInput(cv.dnn.blobFromImage(img_l_rs))
ab_dec = net.forward()[0,:,:,:].transpose((1,2,0)) # this is our result
(H_orig,W_orig) = img_rgb.shape[:2] # original image size
ab_dec_us = cv.resize(ab_dec, (W_orig, H_orig))
img_lab_out = np.concatenate((img_l[:,:,np.newaxis],ab_dec_us),axis=2) # concatenate with original image L
img_bgr_out = np.clip(cv.cvtColor(img_lab_out, cv.COLOR_Lab2BGR), 0, 1)
outputFile = '_colorized.png'
cv.imwrite(outputFile, (img_bgr_out*255).astype(np.uint8))
print('Colorized image saved as '+outputFile)
print('Done !!!')
3.2 视频着色代码
C++:
#include "pch.h"
#include
#include
#include
#include
using namespace cv;
using namespace cv::dnn;
using namespace std;
// the 313 ab cluster centers from pts_in_hull.npy (already transposed)
static float hull_pts[] = {
-90., -90., -90., -90., -90., -80., -80., -80., -80., -80., -80., -80., -80., -70., -70., -70., -70., -70., -70., -70., -70.,
-70., -70., -60., -60., -60., -60., -60., -60., -60., -60., -60., -60., -60., -60., -50., -50., -50., -50., -50., -50., -50., -50.,
-50., -50., -50., -50., -50., -50., -40., -40., -40., -40., -40., -40., -40., -40., -40., -40., -40., -40., -40., -40., -40., -30.,
-30., -30., -30., -30., -30., -30., -30., -30., -30., -30., -30., -30., -30., -30., -30., -20., -20., -20., -20., -20., -20., -20.,
-20., -20., -20., -20., -20., -20., -20., -20., -20., -10., -10., -10., -10., -10., -10., -10., -10., -10., -10., -10., -10., -10.,
-10., -10., -10., -10., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 10., 10., 10., 10., 10., 10., 10.,
10., 10., 10., 10., 10., 10., 10., 10., 10., 10., 10., 20., 20., 20., 20., 20., 20., 20., 20., 20., 20., 20., 20., 20., 20., 20.,
20., 20., 20., 30., 30., 30., 30., 30., 30., 30., 30., 30., 30., 30., 30., 30., 30., 30., 30., 30., 30., 30., 40., 40., 40., 40.,
40., 40., 40., 40., 40., 40., 40., 40., 40., 40., 40., 40., 40., 40., 40., 40., 50., 50., 50., 50., 50., 50., 50., 50., 50., 50.,
50., 50., 50., 50., 50., 50., 50., 50., 50., 60., 60., 60., 60., 60., 60., 60., 60., 60., 60., 60., 60., 60., 60., 60., 60., 60.,
60., 60., 60., 70., 70., 70., 70., 70., 70., 70., 70., 70., 70., 70., 70., 70., 70., 70., 70., 70., 70., 70., 70., 80., 80., 80.,
80., 80., 80., 80., 80., 80., 80., 80., 80., 80., 80., 80., 80., 80., 80., 80., 90., 90., 90., 90., 90., 90., 90., 90., 90., 90.,
90., 90., 90., 90., 90., 90., 90., 90., 90., 100., 100., 100., 100., 100., 100., 100., 100., 100., 100., 50., 60., 70., 80., 90.,
20., 30., 40., 50., 60., 70., 80., 90., 0., 10., 20., 30., 40., 50., 60., 70., 80., 90., -20., -10., 0., 10., 20., 30., 40., 50.,
60., 70., 80., 90., -30., -20., -10., 0., 10., 20., 30., 40., 50., 60., 70., 80., 90., 100., -40., -30., -20., -10., 0., 10., 20.,
30., 40., 50., 60., 70., 80., 90., 100., -50., -40., -30., -20., -10., 0., 10., 20., 30., 40., 50., 60., 70., 80., 90., 100., -50.,
-40., -30., -20., -10., 0., 10., 20., 30., 40., 50., 60., 70., 80., 90., 100., -60., -50., -40., -30., -20., -10., 0., 10., 20.,
30., 40., 50., 60., 70., 80., 90., 100., -70., -60., -50., -40., -30., -20., -10., 0., 10., 20., 30., 40., 50., 60., 70., 80., 90.,
100., -80., -70., -60., -50., -40., -30., -20., -10., 0., 10., 20., 30., 40., 50., 60., 70., 80., 90., -80., -70., -60., -50.,
-40., -30., -20., -10., 0., 10., 20., 30., 40., 50., 60., 70., 80., 90., -90., -80., -70., -60., -50., -40., -30., -20., -10.,
0., 10., 20., 30., 40., 50., 60., 70., 80., 90., -100., -90., -80., -70., -60., -50., -40., -30., -20., -10., 0., 10., 20., 30.,
40., 50., 60., 70., 80., 90., -100., -90., -80., -70., -60., -50., -40., -30., -20., -10., 0., 10., 20., 30., 40., 50., 60., 70.,
80., -110., -100., -90., -80., -70., -60., -50., -40., -30., -20., -10., 0., 10., 20., 30., 40., 50., 60., 70., 80., -110., -100.,
-90., -80., -70., -60., -50., -40., -30., -20., -10., 0., 10., 20., 30., 40., 50., 60., 70., 80., -110., -100., -90., -80., -70.,
-60., -50., -40., -30., -20., -10., 0., 10., 20., 30., 40., 50., 60., 70., -110., -100., -90., -80., -70., -60., -50., -40., -30.,
-20., -10., 0., 10., 20., 30., 40., 50., 60., 70., -90., -80., -70., -60., -50., -40., -30., -20., -10., 0.
};
int main()
{
String videoFileName = "./video/greyscaleVideo.mp4";
cv::VideoCapture cap(videoFileName);
if (!cap.isOpened())
{
cerr << "Unable to open video" << endl;
return 1;
}
string protoFile = "./model/colorization_deploy_v2.prototxt";
string weightsFile = "./model/colorization_release_v2.caffemodel";
//string weightsFile = "./model/colorization_release_v2_norebal.caffemodel";
Mat frame, frameCopy;
int frameWidth = cap.get(CAP_PROP_FRAME_WIDTH);
int frameHeight = cap.get(CAP_PROP_FRAME_HEIGHT);
string str = videoFileName;
str.replace(str.end()-4, str.end(), "");
string outVideoFileName = str+"_colorized.avi";
VideoWriter video(outVideoFileName, VideoWriter::fourcc('M','J','P','G'), 60, Size(frameWidth,frameHeight));
// fixed input size for the pretrained network
const int W_in = 224;
const int H_in = 224;
Net net = dnn::readNetFromCaffe(protoFile, weightsFile);
// setup additional layers:
int sz[] = {2, 313, 1, 1};
const Mat pts_in_hull(4, sz, CV_32F, hull_pts);
Ptr class8_ab = net.getLayer("class8_ab");
class8_ab->blobs.push_back(pts_in_hull);
Ptr conv8_313_rh = net.getLayer("conv8_313_rh");
conv8_313_rh->blobs.push_back(Mat(1, 313, CV_32F, Scalar(2.606)));
int i = 0;
for(;;)
{
cap >> frame;
if (frame.empty()) break;
frameCopy = frame.clone();
// extract L channel and subtract mean
Mat lab, L, input;
frame.convertTo(frame, CV_32F, 1.0/255);
cvtColor(frame, lab, COLOR_BGR2Lab);
extractChannel(lab, L, 0);
resize(L, input, Size(W_in, H_in));
input -= 50;
// run the L channel through the network
Mat inputBlob = blobFromImage(input);
net.setInput(inputBlob);
Mat result = net.forward();
// retrieve the calculated a,b channels from the network output
Size siz(result.size[2], result.size[3]);
Mat a = Mat(siz, CV_32F, result.ptr(0,0));
Mat b = Mat(siz, CV_32F, result.ptr(0,1));
resize(a, a, frame.size());
resize(b, b, frame.size());
// merge, and convert back to BGR
Mat coloredFrame, chn[] = {L, a, b};
merge(chn, 3, lab);
cvtColor(lab, coloredFrame, COLOR_Lab2BGR);
coloredFrame = coloredFrame*255;
coloredFrame.convertTo(coloredFrame, CV_8U);
video.write(coloredFrame);
i++;
cout << "the current frame is: " << to_string(i) << "th" << endl;
}
cout << "Colorized video saved as " << outVideoFileName << endl << "Done !!!" << endl;
cap.release();
video.release();
return 0;
}
python:
import numpy as np
import cv2 as cv
import argparse
import os.path
# Read the input video
cap = cv.VideoCapture('video/greyscaleVideo.mp4')
hasFrame, frame = cap.read()
outputFile = 'colorized.avi'
vid_writer = cv.VideoWriter(outputFile, cv.VideoWriter_fourcc('M','J','P','G'), 60, (frame.shape[1],frame.shape[0]))
# Specify the paths for the 2 model files
protoFile = "./model/colorization_deploy_v2.prototxt"
#weightsFile = "./model/colorization_release_v2.caffemodel"
weightsFile = "./model/colorization_release_v2_norebal.caffemodel"
# Load the cluster centers
pts_in_hull = np.load('./model/pts_in_hull.npy')
# Read the network into Memory
net = cv.dnn.readNetFromCaffe(protoFile, weightsFile)
# populate cluster centers as 1x1 convolution kernel
pts_in_hull = pts_in_hull.transpose().reshape(2, 313, 1, 1)
net.getLayer(net.getLayerId('class8_ab')).blobs = [pts_in_hull.astype(np.float32)]
net.getLayer(net.getLayerId('conv8_313_rh')).blobs = [np.full([1, 313], 2.606, np.float32)]
#from opencv sample
W_in = 224
H_in = 224
i=0
while cv.waitKey(1):
hasFrame, frame = cap.read()
frameCopy = np.copy(frame)
if not hasFrame:
break
img_rgb = (frame[:,:,[2, 1, 0]] * 1.0 / 255).astype(np.float32)
img_lab = cv.cvtColor(img_rgb, cv.COLOR_RGB2Lab)
img_l = img_lab[:,:,0] # pull out L channel
# resize lightness channel to network input size
img_l_rs = cv.resize(img_l, (W_in, H_in))
img_l_rs -= 50 # subtract 50 for mean-centering
net.setInput(cv.dnn.blobFromImage(img_l_rs))
ab_dec = net.forward()[0,:,:,:].transpose((1,2,0)) # this is our result
(H_orig,W_orig) = img_rgb.shape[:2] # original image size
ab_dec_us = cv.resize(ab_dec, (W_orig, H_orig))
img_lab_out = np.concatenate((img_l[:,:,np.newaxis],ab_dec_us),axis=2) # concatenate with original L channel
img_bgr_out = np.clip(cv.cvtColor(img_lab_out, cv.COLOR_Lab2BGR), 0, 1)
vid_writer.write((img_bgr_out*255).astype(np.uint8))
i +=1
print("the current frame is: {}th".format(i))
vid_writer.release()
print('Colorized video saved as '+outputFile)
print('Done !!!')
4 参考
https://www.learnopencv.com/convolutional-neural-network-based-image-colorization-using-opencv/