Spark Streaming 解析-输入转换和输出
1.初始化StreamingContext
import org.apache.spark._
import org.apache.spark.streaming._
val conf = new SparkConf().setAppName(appName).setMaster(master)
val ssc = new StreamingContext(conf, Seconds(1))
// 可以通过ssc.sparkContext 来访问SparkContext
// 或者通过已经存在的SparkContext来创建StreamingContext
import org.apache.spark.streaming._
val sc = ... // existing SparkContext
val ssc = new StreamingContext(sc, Seconds(1))初始化完StreamingContext之后:
• 定义消息输入源来创建DStreams.
• 定义DStreams的转化操作和输出操作。
• 通过 streamingContext.start()来启动消息采集和处理.
• 等待程序终止,可以通过streamingContext.awaitTermination()来设置
• 通过streamingContext.stop()来手动终止处理程序。
StreamingContext和SparkContext什么关系?
import org.apache.spark.streaming._
val sc = ... // existing SparkContext
val ssc = new StreamingContext(sc, Seconds(1))注意:
• StreamingContext一旦启动,对DStreams的操作就不能修改了。
• 在同一时间一个JVM中只有一个StreamingContext可以启动
• stop() 方法将同时停止SparkContext,可以传入参数stopSparkContext用于只停止StreamingContext
• 在Spark1.4版本后,如何优雅的停止SparkStreaming而不丢失数据,通过设置sparkConf.set("spark.streaming.stopGracefullyOnShutdown","true") 即可。在StreamingContext的start方法中已经注册了Hook方法。
2.什么是DStreams
Discretized Stream是Spark Streaming的基础抽象,代表持续性的数据流和经过各种Spark原语操作后的结果数据流。在内部实现上,DStream是一系列连续的RDD来表示。每个RDD含有一段时间间隔内的数据,如下图:

对数据的操作也是按照RDD为单位来进行的
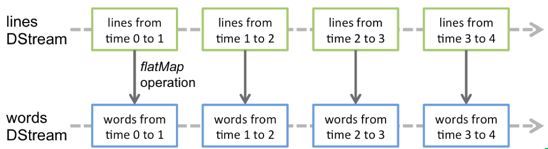
计算过程由Spark engine来完成

3.DStreams输入
Spark Streaming原生支持一些不同的数据源。一些“核心”数据源已经被打包到Spark Streaming 的 Maven 工件中,而其他的一些则可以通过 spark-streaming-kafka 等附加工件获取。每个接收器都以 Spark 执行器程序中一个长期运行的任务的形式运行,因此会占据分配给应用的 CPU 核心。此外,我们还需要有可用的 CPU 核心来处理数据。这意味着如果要运行多个接收器,就必须至少有和接收器数目相同的核心数,还要加上用来完成计算所需要的核心数。例如,如果我们想要在流计算应用中运行 10 个接收器,那么至少需要为应用分配 11 个 CPU 核心。所以如果在本地模式运行,不要使用local或者local[1]。
3.1 基本的数据源
3.1.1 文件数据源
3.1.2 自定义数据源
import java.io.{BufferedReader, InputStreamReader}
import java.net.Socket
import java.nio.charset.StandardCharsets
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.receiver.Receiver
/**
* Created by mkluo on 06/09/2017.
*/
// String就是接收數據的類型
class CustomReceiver(host: String, port: Int) extends Receiver[String](StorageLevel.MEMORY_AND_DISK_2) {
override def onStart(): Unit = {
// Start the thread that receives data over a connection
new Thread("Socket Receiver") {
override def run() { receive() }
}.start()
}
override def onStop(): Unit = {
// There is nothing much to do as the thread calling receive()
// is designed to stop by itself if isStopped() returns false
}
/** Create a socket connection and receive data until receiver is stopped */
private def receive() {
var socket: Socket = null
var userInput: String = null
try {
// Connect to host:port
socket = new Socket(host, port)
// Until stopped or connection broken continue reading
val reader = new BufferedReader(new InputStreamReader(socket.getInputStream(), StandardCharsets.UTF_8))
userInput = reader.readLine()
while(!isStopped && userInput != null) {
// 內部的函數,將數據存儲下倆
store(userInput)
userInput = reader.readLine()
}
reader.close()
socket.close()
// Restart in an attempt to connect again when server is active again
restart("Trying to connect again")
} catch {
case e: java.net.ConnectException =>
// restart if could not connect to server
restart("Error connecting to " + host + ":" + port, e)
case t: Throwable =>
// restart if there is any other error
restart("Error receiving data", t)
}
}
}
object CustomReceiver {
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local[*]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
// Create a DStream that will connect to hostname:port, like localhost:9999
val lines = ssc.receiverStream(new CustomReceiver("master01", 9999))
// Split each line into words
val words = lines.flatMap(_.split(" "))
//import org.apache.spark.streaming.StreamingContext._ // not necessary since Spark 1.3
// Count each word in each batch
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
// Print the first ten elements of each RDD generated in this DStream to the console
wordCounts.print()
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate
//ssc.stop()
}
}
3.1.3 RDD队列
3.2 高级数据源
除核心数据源外,还可以用附加数据源接收器来从一些知名数据获取系统中接收的数据,这些接收器都作为Spark Streaming的组件进行独立打包了。它们仍然是Spark的一部分,不过你需要在构建文件中添加额外的包才能使用它们。现有的接收器包括 Twitter、Apache Kafka、Amazon Kinesis、Apache Flume,以及ZeroMQ。可以通过添加与Spark版本匹配 的 Maven 工件 spark-streaming-[projectname]_2.10 来引入这些附加接收器。
3.2.1 Spark对Kafka两种连接方式的对比
Spark-Streaming获取kafka数据的两种方式Receiver与Direct
3.2.1.1 基于Receiver的方式(对应 Kafka 的High Level API)
这种方式使用Receiver来获取数据。Receiver是使用Kafka的高层次Consumer API来实现的。receiver从Kafka中获取的数据都是存储在Spark Executor的内存中的(如果突然数据暴增,大量batch堆积,很容易出现内存溢出的问题),然后Spark Streaming启动的job会去处理那些数据。
然而,在默认的配置下,这种方式可能会因为底层的失败而丢失数据。如果要启用高可靠机制,让数据零丢失,就必须启用Spark Streaming的预写日志机制(Write Ahead Log,WAL)。该机制会同步地将接收到的Kafka数据写入分布式文件系统(比如HDFS)上的预写日志中。所以,即使底层节点出现了失败,也可以使用预写日志中的数据进行恢复。
需要注意的要点:
• Kafka中的topic的partition,与Spark中的RDD的partition是没有关系的。所以,在KafkaUtils.createStream()中,提高partition的数量,只会增加一个Receiver中,读取partition的线程的数量。不会增加Spark处理数据的并行度。
• 可以创建多个Kafka输入DStream,使用不同的consumer group和topic,来通过多个receiver并行接收数据。
• 如果基于容错的文件系统,比如HDFS,启用了预写日志机制,接收到的数据都会被复制一份到预写日志中。因此,在KafkaUtils.createStream()中,设置的持久化级别是StorageLevel.MEMORY_AND_DISK_SER。
3.2.1.2 基于Direct的方式(对应Kafka 的 Low Level API,这个是我们项目中常用的)
这种新的不基于Receiver的直接方式,是在Spark 1.3中引入的,从而能够确保更加健壮的机制。替代掉使用Receiver来接收数据后,这种方式会周期性地查询Kafka,来获得每个topic+partition的最新的offset,从而定义每个batch的offset的范围。当处理数据的job启动时,就会使用Kafka的简单consumer api来获取Kafka指定offset范围的数据。
这种方式有如下优点:
• 简化并行读取:如果要读取多个partition,不需要创建多个输入DStream然后对它们进行union操作。Spark会创建跟Kafka partition一样多的RDD partition,并且会并行从Kafka中读取数据。所以在Kafka partition和RDD partition之间,有一个一对一的映射关系。
• 高性能:如果要保证零数据丢失,在基于receiver的方式中,需要开启WAL机制。这种方式其实效率低下,因为数据实际上被复制了两份,Kafka自己本身就有高可靠的机制,会对数据复制一份,而这里又会复制一份到WAL中。而基于direct的方式,不依赖Receiver,不需要开启WAL机制,只要Kafka中作了数据的复制,那么就可以通过Kafka的副本进行恢复。
• 一次且仅一次的事务机制:
3.2.1.3 对比:
基于receiver的方式,是使用Kafka的高阶API来在ZooKeeper中保存消费过的offset的。这是消费Kafka数据的传统方式。这种方式配合着WAL机制可以保证数据零丢失的高可靠性,但是却无法保证数据被处理一次且仅一次,可能会处理两次。因为Spark和ZooKeeper之间可能是不同步的。
基于direct的方式,使用kafka的简单api,Spark Streaming自己就负责追踪消费的offset,并保存在checkpoint中。Spark自己一定是同步的,因此可以保证数据是消费一次且仅消费一次。
在实际生产环境中大都用Direct方式
3.2.2 Spark对接 Kafka代码实现:
3.2.2.1 Idea代码实现之前测试
1、Kafka创建Topic的命令
bin/kafka-topics.sh --create --zookeeper hadoop102:2181,hadoop103:2181,hadoop104:2181 --replication-factor 2 --partitions 2 --topic source101
2、Producer Client
bin/kafka-console-producer.sh --broker-list hadoop102:9092, hadoop103:9092, hadoop104:9092 --topic source101
3、Consumer Client
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092, hadoop103:9092, hadoop104:9092 --topic source1013.2.2.2 Idea代码实现之后测试(在执行如下代码之前必须先启动Hadoop集群,ZK,Kafka和 下面的程序)
1、Kafka创建Topic的命令
bin/kafka-topics.sh --create --zookeeper hadoop102:2181,hadoop103:2181,hadoop104:2181 --replication-factor 2 --partitions 2 --topic target2
2、Producer Client
bin/kafka-console-producer.sh --broker-list hadoop102:9092, hadoop103:9092, hadoop104:9092 --topic source2
3、Consumer Client
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092, hadoop103:9092, hadoop104:9092 --topic target23.2.2.3 Idea代码实现如下(对应Kafka 的 Low Level API,这个是我们项目中常用的):
(1)KafkaPool类:
import java.util.Properties
import org.apache.commons.pool2.impl.{DefaultPooledObject, GenericObjectPool}
import org.apache.commons.pool2.{BasePooledObjectFactory, PooledObject}
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
//先创建一个包装类
class KafkaProxy(brokers:String){
private val pros:Properties = new Properties()
pros.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers)
pros.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer")
pros.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer")
private val kafkaConn = new KafkaProducer[String,String](pros)
def send(topic:String, key:String, value:String): Unit ={
kafkaConn.send(new ProducerRecord[String,String](topic,key,value))
}
def send(topic:String,value:String): Unit ={
kafkaConn.send(new ProducerRecord[String,String](topic,value))
}
def close(): Unit ={
kafkaConn.close()
}
}
//需要创建一个用于创建对象的工厂
class KafkaProxyFactory(brokers:String) extends BasePooledObjectFactory[KafkaProxy]{
//创建一个实例
override def create(): KafkaProxy = new KafkaProxy(brokers)
override def wrap(t: KafkaProxy): PooledObject[KafkaProxy] = new DefaultPooledObject[KafkaProxy](t)
}
/**
* 用于Spark和kafka的连接
*/
object KafkaPool {
//声明一个连接池对象
private var kafkaProxyPool: GenericObjectPool[KafkaProxy] = null
def apply(brokers:String) : GenericObjectPool[KafkaProxy] = {
if(null == kafkaProxyPool){
KafkaPool.synchronized{
if(null == kafkaProxyPool){
kafkaProxyPool = new GenericObjectPool[KafkaProxy](new KafkaProxyFactory(brokers))
}
}
}
kafkaProxyPool
}
}(2)StreamingKafka 类:
import kafka.api.{OffsetRequest, PartitionOffsetRequestInfo, TopicMetadataRequest}
import kafka.common.TopicAndPartition
import kafka.consumer.SimpleConsumer
import kafka.message.MessageAndMetadata
import kafka.serializer.StringDecode
import kafka.utils.{ZKGroupTopicDirs, kUtils}
import org.I0Itec.zkclient.ZkClient
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka.{HasOffsetRanges, KafkaUtils, OffsetRange}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object StreamingKafka {
def main(args: Array[String]): Unit {
//conf
val conf = new SparkConf().setAppName("kafka").setMaster("local[*]")
val ssc = new StreamingContext(conf,Seconds(5))
//创建连接Kafka的参数
val brokerList = "hadoop102:9092,hadoop103:9092,hadoop104:9092"
val zookeeper = "hadoop102:2181,hadoop103:2181,hadoop104:2181"
val sourceTopic = "source2"
val tagetTopic = "target2"
val groupid = "consumer001"
//创建连接kafka的参数
val kafkaParam = Map[String,String](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> brokerList,
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer",
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer",
ConsumerConfig.GROUP_ID_CONFIG -> groupid,
ConsumerConfig.AUTO_OFFSET_RESET_CONFIG -> "largest"
)
//连接上Kafka
// 创建Kafka的连接需要从ZK中去恢复
var textKafkaDStream:InputDStream[(String,String)] = null
//创建连接到ZK,查看是否存在数据保存
val topicDirs = new ZKGroupTopicDirs(groupid, sourceTopic)
val zkTopicPath = s"${topicDirs.consumerOffsetDir}"
val zkClient = new ZkClient(zookeeper)
val children = zkClient.countChildren(zkTopicPath)
//如果有保存,那么从上一个状态恢复
if(children > 0){
//最终保存上一次的状态
var fromOffsets:Map[TopicAndPartition, Long] = Map()
//获取Kafka集群的元信息
val topicList = List(sourceTopic)
//创建一个连接
val getLeaderConsumer = new SimpleConsumer("hadoop102",9092, 100000,10000,"OffsetLookUp")
//创建一个获取元信息的Request
val request = new TopicMetadataRequest(topicList,0)
//获取返回的元信息
val response = getLeaderConsumer.send(request)
//解出元信息
val topicMetadataOption = response.topicsMetadata.headOption
//partitons 就是包含了每一个分区的主节点所在的主机名称
val partitons = topicMetadataOption match {
case Some(tm) => tm.partitionsMetadata.map( pm => (pm.partitionId, pm.leader.get.host)).toMap[Int,String]
case None => Map[Int,String]()
}
getLeaderConsumer.close()
println("partition info is: " + partitons)
println("children info is: " + children)
//获取每一个分区的最小Offset
for(i <- 0 until children){
//先获取ZK中第i个分区保存的offset
val partitionOffset = zkClient.readData[String](s"${topicDirs.consumerOffsetDir}/${i}")
println(s"Patition ${i} 目前的Offset是: ${partitionOffset}")
//获取第i个分区的最小Offset
//创建一个到第i个分区主分区所在的Host上的连接
val consumerMin = new SimpleConsumer(partitons(i),9092,100000,10000,"getMinOffset")
//创建一个请求
val tp = TopicAndPartition(sourceTopic,i)
val requestMin = OffsetRequest(Map(tp -> PartitionOffsetRequestInfo(OffsetRequest.EarliestTime,1) ))
//获取最小的Offset
val curOffsets = consumerMin.getOffsetsBefore(requestMin).partitionErrorAndOffsets(tp).offsets
consumerMin.close()
//校准
var nextOffset = partitionOffset.toLong
if(curOffsets.length >0 && nextOffset < curOffsets.head){
nextOffset = curOffsets.head
}
fromOffsets += (tp -> nextOffset)
println(s"Patition ${i} 校准后的Offset是: ${nextOffset}")
}
zkClient.close()
println("从ZK中恢复创建")
val messageHandler = (mmd: MessageAndMetadata[String,String]) => (mmd.topic, mmd.message())
textKafkaDStream = KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder,(String,String)](ssc,kafkaParam,fromOffsets,messageHandler)
}else{
//直接创建
println("直接创建")
textKafkaDStream = KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](ssc,kafkaParam,Set(sourceTopic))
}
//注意:需要先拿到新读取进来的数据的Offset,不要转换成为另外一个DStream后再去拿去
var offsetRanges = Array[OffsetRange]()
val textKafkaDStream2 = textKafkaDStream.transform{ rdd =>
offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd
}
textKafkaDStream2.map(s => "key:"+ s._1 + " value:" + s._2).foreachRDD{ rdd =>
rdd.foreachPartition{ items =>
//写回Kafka
//创建到Kafka的连接
val pool = KafkaPool(brokerList)
val kafkaProxy = pool.borrowObject()
//写数据
for(item <- items)
kafkaProxy.send(tagetTopic, item)
pool.returnObject(kafkaProxy)
//关闭连接
}
//需要将Kafka每一个分区中读取的Offset更新到ZK
val updateTopicDirs = new ZKGroupTopicDirs(groupid,sourceTopic)
val updateZkClient = new ZkClient(zookeeper)
for(offset <- offsetRanges){
//将读取的最新的Offset保存到ZK中
println(s"Patiton ${offset.partition} 保存到ZK中的数据Offset 是:${offset.fromOffset.toString}" )
val zkPath = s"${updateTopicDirs.consumerOffsetDir}/${offset.partition}"
ZkUtils.updatePersistentPath(updateZkClient, zkPath, offset.fromOffset.toString)
}
updateZkClient.close()
}
ssc.start()
ssc.awaitTermination()
}
}3.2.3 Flume-ng
4.Dstream 的转换
DStream上的原语与RDD的类似,分为Transformations(转换)和Output Operations(输出)两种,此外转换操作中还有一些比较特殊的原语,如:updateStateByKey()、transform()以及各种Window相关的原语。
| Transformation |
Meaning |
| map(func) |
将源DStream中的每个元素通过一个函数func从而得到新的DStreams。
|
| flatMap(func) |
和map类似,但是每个输入的项可以被映射为0或更多项。
|
| filter(func) |
选择源DStream中函数func判为true的记录作为新DStreams
|
| repartition(numPartitions) |
通过创建更多或者更少的partition来改变此DStream的并行级别。
|
| union(otherStream) |
联合源DStreams和其他DStreams来得到新DStream
|
| count() |
统计源DStreams中每个RDD所含元素的个数得到单元素RDD的新DStreams。
|
| reduce(func) |
通过函数func(两个参数一个输出)来整合源DStreams中每个RDD元素得到单元素RDD的DStreams。这个函数需要关联从而可以被并行计算。
|
| countByValue() |
对于DStreams中元素类型为K调用此函数,得到包含(K,Long)对的新DStream,其中Long值表明相应的K在源DStream中每个RDD出现的频率。
|
| reduceByKey(func, [numTasks]) |
对(K,V)对的DStream调用此函数,返回同样(K,V)对的新DStream,但是新DStream中的对应V为使用reduce函数整合而来。Note:默认情况下,这个操作使用Spark默认数量的并行任务(本地模式为2,集群模式中的数量取决于配置参数spark.default.parallelism)。你也可以传入可选的参数numTaska来设置不同数量的任务。
|
| join(otherStream, [numTasks]) |
两DStream分别为(K,V)和(K,W)对,返回(K,(V,W))对的新DStream。
|
| cogroup(otherStream, [numTasks]) |
两DStream分别为(K,V)和(K,W)对,返回(K,(Seq[V],Seq[W])对新DStreams
|
| transform(func) |
将RDD到RDD映射的函数func作用于源DStream中每个RDD上得到新DStream。这个可用于在DStream的RDD上做任意操作。 |
| transform(func) 详解: |
能够将DStream的Transformations 操作转换为RDD的Transformations操作。 |

DStream 的转化操作可以分为无状态(stateless)和有状态(stateful)两种。
• 在无状态转化操作中,每个批次的处理不依赖于之前批次的数据。常见的 RDD 转化操作,例如 map()、filter()、reduceByKey() 等,都是无状态转化操作。
• 相对地,有状态转化操作需要使用之前批次的数据或者是中间结果来计算当前批次的数据。有状态转化操作包括基于滑动窗口的转化操作和追踪状态变化的转化操作。
4.1 无状态转化
无状态转化操作就是把简单的 RDD 转化操作应用到每个批次上,也就是转化 DStream 中的每一个 RDD。部分无状态转化操作列在了下表中。
注意,针对键值对的 DStream 转化操作(比如 reduceByKey())要添加import StreamingContext._ 才能在 Scala中使用。

需要记住的是,尽管这些函数看起来像作用在整个流上一样,但事实上每个 DStream 在内部是由许多 RDD(批次)组成,且无状态转化操作是分别应用到每个 RDD 上的。例如, reduceByKey() 会归约每个时间区间中的数据,但不会归约不同区间之间的数据。
举个例子,在之前的wordcount程序中,我们只会统计1秒内接收到的数据的单词个数,而不会累加。
无状态转化操作也能在多个 DStream 间整合数据,不过也是在各个时间区间内。例如,键 值对 DStream 拥有和 RDD 一样的与连接相关的转化操作,也就是 cogroup()、join()、 leftOuterJoin() 等。我们可以在 DStream 上使用这些操作,这样就对每个批次分别执行了对应的 RDD 操作。
我们还可以像在常规的 Spark 中一样使用 DStream 的 union() 操作将它和另一个 DStream 的内容合并起来,也可以使用 StreamingContext.union() 来合并多个流。
4.2 有状态转化操作
特殊的Transformations
4.2.1 追踪状态变化UpdateStateByKey
UpdateStateByKey原语用于记录历史记录,有时,我们需要在 DStream 中跨批次维护状态(例如流计算中累加wordcount)。针对这种情况,updateStateByKey() 为我们提供了对一个状态变量的访问,用于键值对形式的 DStream。给定一个由(键,事件)对构成的 DStream,并传递一个指定如何根据新的事件 更新每个键对应状态的函数,它可以构建出一个新的 DStream,其内部数据为(键,状态) 对。
updateStateByKey() 的结果会是一个新的 DStream,其内部的 RDD 序列是由每个时间区间对应的(键,状态)对组成的。
updateStateByKey操作使得我们可以在用新信息进行更新时保持任意的状态。为使用这个功能,你需要做下面两步:
1. 定义状态,状态可以是一个任意的数据类型。
2. 定义状态更新函数,用此函数阐明如何使用之前的状态和来自输入流的新值对状态进行更新。
使用updateStateByKey需要对检查点目录进行配置,会使用检查点来保存状态。
4.2.2 Window Operations
Window Operations有点类似于Storm中的State,可以设置窗口的大小和滑动窗口的间隔来动态的获取当前Steaming的允许状态。
基于窗口的操作会在一个比 StreamingContext 的批次间隔更长的时间范围内,通过整合多个批次的结果,计算出整个窗口的结果。
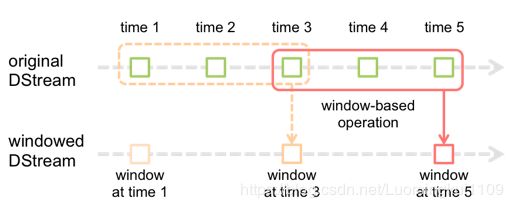
所有基于窗口的操作都需要两个参数,分别为窗口时长以及滑动步长,两者都必须是 StreamContext 的批次间隔的整数倍。窗口时长控制每次计算最近的多少个批次的数据,其实就是最近的 windowDuration/batchInterval 个批次。如果有一个以 10 秒为批次间隔的源 DStream,要创建一个最近 30 秒的时间窗口(即最近 3 个批次),就应当把 windowDuration 设为 30 秒。而滑动步长的默认值与批次间隔相等,用来控制对新的 DStream 进行计算的间隔。如果源 DStream 批次间隔为 10 秒,并且我们只希望每两个批次计算一次窗口结果, 就应该把滑动步长设置为 20 秒。
假设,你想拓展前例从而每隔十秒对持续30秒的数据生成word count。为做到这个,我们需要在持续30秒数据的(word,1)对DStream上应用reduceByKey。使用操作reduceByKeyAndWindow。
5. DStreams输出
输出操作指定了对流数据经转化操作得到的数据所要执行的操作(例如把结果推入外部数据库或输出到屏幕上)。与 RDD 中的惰性求值类似,如果一个 DStream 及其派生出的 DStream 都没有被执行输出操作,那么这些 DStream 就都不会被求值。如果 StreamingContext 中没有设定输出操作,整个 context 就都不会启动。
| Output Operation |
Meaning |
| print() |
在运行流程序的驱动结点上打印DStream中每一批次数据的最开始10个元素。这用于开发和调试。在Python API中,同样的操作叫pprint()。
|
| saveAsTextFiles(prefix, [suffix]) |
以text文件形式存储这个DStream的内容。每一批次的存储文件名基于参数中的prefix和suffix。”prefix-Time_IN_MS[.suffix]”.
|
| saveAsObjectFiles(prefix, [suffix]) |
以Java对象序列化的方式将Stream中的数据保存为 SequenceFiles . 每一批次的存储文件名基于参数中的为"prefix-TIME_IN_MS[.suffix]". Python中目前不可用。 |
| saveAsHadoopFiles(prefix, [suffix]) |
将Stream中的数据保存为 Hadoop files. 每一批次的存储文件名基于参数中的为"prefix-TIME_IN_MS[.suffix]". Python API Python中目前不可用。 |
| foreachRDD(func) |
这是最通用的输出操作,即将函数func用于产生于stream的每一个RDD。其中参数传入的函数func应该实现将每一个RDD中数据推送到外部系统,如将RDD存入文件或者通过网络将其写入数据库。注意:函数func在运行流应用的驱动中被执行,同时其中一般函数RDD操作从而强制其对于流RDD的运算。
|
| foreachRDD(func)详解 |
|
通用的输出操作 foreachRDD(),它用来对 DStream 中的 RDD 运行任意计算。这和transform() 有些类似,都可以让我们访问任意 RDD。在 foreachRDD() 中,可以重用我们在 Spark 中实现的所有行动操作。比如,常见的用例之一是把数据写到诸如 MySQL 的外部数据库中。
需要注意的:
1) 连接不能写在driver层面
2) 如果写在foreach则每个RDD都创建,得不偿失
3) 增加foreachPartition,在分区创建 4) 可以考虑使用连接池优化
dstream.foreachRDD { rdd =>
// error val connection = createNewConnection() // executed at the driver 序列化错误
rdd.foreachPartition { partitionOfRecords =>
// ConnectionPool is a static, lazily initialized pool of connections
val connection = ConnectionPool.getConnection()
partitionOfRecords.foreach(record => connection.send(record) // executed at the worker
)
ConnectionPool.returnConnection(connection) // return to the pool for future reuse
}
}