[TOC]
一、前言
前面基础部分学习的差不多了,是不是感觉卧槽,Django牛逼啊,哈哈哈,前面的部分内容还不是django的重头戏呢,接下来的部分才是精彩来袭,此处需要你擦亮自己的眼睛啦
下面讲的部分是我们django模型层的内容,此处插一嘴,想问一下之前django学习了那几层你还记得不,不记得自己回去找去,下面正式介绍模型层了:
大家听模型层这个名字,脑子里是否闪过模型飞机?哈哈哈,反正我有,来现在模型层的概念就来了
二、模型层的概念
这里先来说说django的ORM吧,不过不瞒你们说之前我自己也写过ORM,自己封装了一个建议版本的,当然,功能当然不能和Django的ORM比啦,敌方大强大,打不过呀!
那什么是ORM呢?很好奇吧! ORM就是我们现在要说的模型层,大家以前都学过数据库吧,学数据库的时候,是不是觉得哇塞SQL语句好难写啊,好多啊,在python里面我们要是需要用到数据库的话,不仅要和数据库进行连接,连接过后还要创建游标对象,然后还要写SQL语句,感觉贼麻烦,跟在命令行中敲SQL语句还麻烦啊。
现在ORM就是帮我们做了这个事情,让我们自己不用再希望SQL语句了,是不是又在想,不屑SQL语句,我怎么获取数据啊,这不是再开玩笑嘛!当然了不用你写SQL语句了,但是你需要敲正常的代码啊。
三、ORM简介
ORM:是Djaogo框架帮我们封装的,它是对象关系映射表
我们再使用Django框架开发web应用的过程中,不可避免的就是涉及到数据的管理操作(增、删、改、查),而一旦涉及到数据的管理操作,那肯定是要用到数据库了,比如mysql、sqlite等·····
如果应用程序需要操作数据(比如将用户注册信息永久存放起来),那么我们需 要在应用程序中编写原生sql语句,然后使用pymysql模块远程操作mysql数据库, 但是直接编写原生sql语句会存在两方面的问题,严重影响开发效率,如下:
- sql语句的执行效率:应用开发程序员需要耗费一大部分精力去优化sql语句
- 数据库迁移:针对mysql开发的sql语句无法直接应用到oracle数据库上,一旦需要迁移数据库,便需要考虑跨平 台问题
为了解决上述问题,django引入了ORM的概念,ORM全称Object Relational Mapping,即对象关系映射,是在pymysq之上又进行了一层封装,对于数据的操 作,我们无需再去编写原生sql,取而代之的是基于面向对象的思想去编写类、对象、调用相应的方法等,ORM会将其转换/映射成原生SQL然后交给pymysql执行,
如此,开发人员既不用再去考虑原生SQL的优化问题,也不用考虑数据库迁移的问 题,ORM都帮我们做了优化且支持多种数据库,这极大地提升了我们的开发效 率,下面就让我们来详细学习ORM的使用吧
四、Django 配置数据库
我们不管怎么样都是要先连接数据库的,Django中配置数据库如下:
首先去和项目名同名的文件夹下的settings.py文件里,此处这个文件是干嘛,我想我不用再说了吧,(配置app应用、配置静态文件static、配置templates·······),数据库配置如下:

注意1:在连接数据库之前,必须自己手动在数据库中创建好改数据库(book_db),名字要一一对应
**注意2:**python解释器在运行django项目时,django的orm底层操作的数据库是默认mysqldb而非 pymysql,然而对于解释器而言,python2.x解释器支持的操作数据库的模块是mysqldb,而python3.x解释器支持的操作 数据库的模块则是pymysql,,毫无疑问,目前我们的django程序都是运行于python3.x解释器下,于是我们需要修改 django的orm默认操作数据库的模块为pymysql,具体做法如下 :
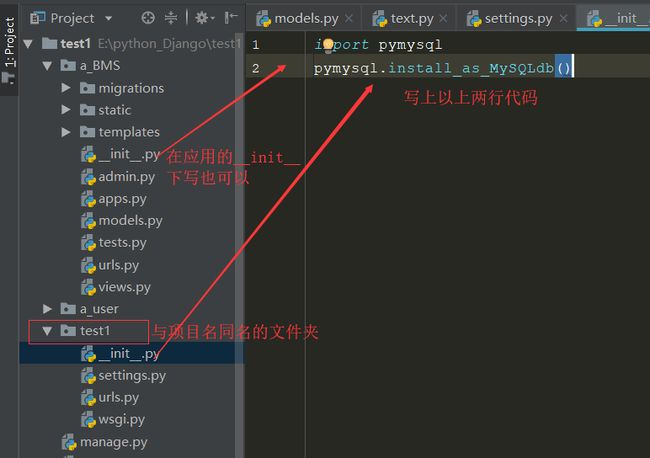
五、使用ORM
上述是ORM的概念,那我们如何去使用呢?
在我们创建Django项目,并且项目中的每一个app应用,都包含了一个models.py文件,这个文件部分就是模型层,同样在这里使用ORM
ORM就是模型表,它是面向类、对象的,我们知道数据库里的每一条记录是以一个大字典的形式,字典里存放着key:value这个value也是一个字典,也就是说字典套字典的形式,我们应该牢记一个概念,在python中,一切皆对象。那么想到了对象,我们就能联想了,对象最重要的特点是**可以点取值。**这里就有冲突了,字典不能点取值、赋值、所以我们怎么实现对象关系映射呢?
**对象关系映射:**就是把从数据里拿出的数据变为对象的形式,可以用点去操作数据,从数据库里拿出来的数据叫做记录,所以每一条记录就是一个对象,那什么才能产生一个对象呢?那当然是类啦,所以数据库中的表称之为类。下面直接看代码把:
# 在app应用下的models.py模型层中写ORM
from django.db import models
class Employee(models.Model): # 必须是models.Model的子类
id=models.AutoField(primary_key=True)
name=models.CharField(max_length=16)
gender=models.BooleanField(default=1)
birth=models.DateField()
department=models.CharField(max_length=30)
salary=models.DecimalField(max_digits=10,decimal_places=1)
以上就是一张模型表写好了,但是只是写完这个代码,运行项目,模型表就生成了?
然而并不是,我们要是真正的想讲这张表创建出来,并且可以正常使用,我们还要做如下操作:
六、数据库表迁移
# 执行数据的迁移命令
1.首先打开终端,在命令行中输入:
python manage.py makemigrations # 仅仅是数据库迁移命令,仅仅是讲我们迁移数据库表的记录保存起来的,并没有把表创建出来。该数据库迁移记录是放在migrations文件下
python.manahe.py migrate # 真正的创建数据库表的命令,执行完词条命令,表employee就被创建出来了。
**注意1:**只要我们完成了上面的两条数据库表迁移命令以后,并且表被创建出来以后,我们日后只要修改了上面模型表的内容,哪怕是一个字母,我们都要执行上面两条数据库表迁移命令。
**注意2:**我们只要执行过数据库迁移命令,在migrations文件夹就会增加一条记录,
七、打印ORM在转换过程中的SQL
如果想打印我们在用ORM执行数据库操作时它对应的SQL语句的话,需要在settings.py文件夹中做如下配置:
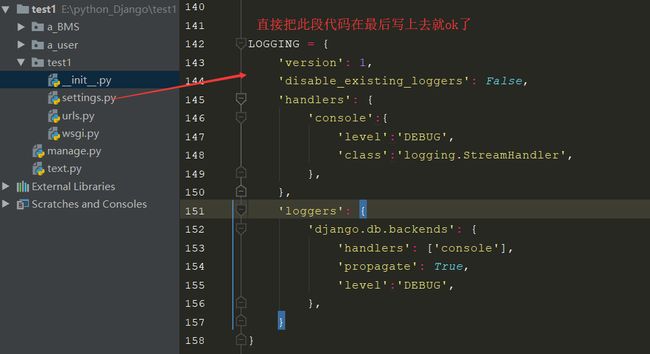
八、配置好数据库报错时
在使用django1.x版本时,如果报如下错误
django.core.exceptions.ImproperlyConfigured: mysqlclient 1.3.3 or newer is required; you have 0.7.11.None
**原因:**那是因为MySQLclient目前只支持到python3.4,如果使用的更高版本的python, 需要找到文件C:\Programs\Python\Python36-32\Lib\site-packages\Django-2.0py3.6.egg\django\db\backends\mysql 这个路径里的文件
# 注释下述两行内容即可
if version < (1, 3, 3):
raise ImproperlyConfigured("mysqlclient 1.3.3 or newer is required; you have %s" % Database.__version__)
九、数据库中生成的表
当我们直接去数据库里查看生成的表时,会发现数据库中的表与orm规定 的并不一致,这完全是正常的,事实上,orm的字段约束就是不会全部体现在数据 库的表中,比如我们为字段gender设置的默认值default=1,去数据库中查看会发 现该字段的default部分为null
mysql> desc app01_employee; # 数据库中标签前会带有前缀app01_
+------------+---------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra
| +------------+---------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(16) | NO | | NULL | |
| gender | tinyint(1) | NO | | NULL | |
| birth | date | NO | | NULL | |
| department | varchar(30) | NO | | NULL | |
| salary | decimal(10,1) | NO | | NULL | |
+------------+---------------+------+-----+---------+----------------+
虽然数据库没有增加默认值,但是我们在使用orm插入值时,完全为gender字段插 入空,orm会按照自己的约束将空转换成默认值后,再提交给数据库执行
十、django操作数据库
10.1 添加记录
# 方式一:
models.employee.objects.create(name='xichen',gender=0,brith='1998-01-01',department='财务部',salary=10001.1)
# 方式二:
obj = models.employee(name='xichen',gender=0,brith='1998-01-01',department='财务部',salary=10001.1)
obj.save()
10.2 查询数据
- 下述方法查询的结果都有可能包含多个记录对象,为了存放 查询出的多个记录对象,django的ORM自定义了一种数据类型Queryset,所以下 述方法的返回值均为QuerySet类型的对象,QuerySet对象中包含了查询出的多个 记录对象
1. filter(**kwargs)
# 参数是过滤条件
# 返回的是Queryset对象:[对象···]返回的是符合条件的多个或一个记录对象
# 可以按照索引取记录对象,但是最好不要这样做
obj = models.employee.objects.filter(id=1)
# 返回:,]>
2.all()
# 取所有的记录对象
# 与filter的区别就是,无参
# 返回的是Queryset对象:[对象···]返回的是表中所有的记录对象
obj = models.employee.objects.all()
# 返回:,]>
3.exclude(**kwargs)
# 取除了条件以外的所有记录对象
# 有参
# 返回的是Queryset对象:[对象···]返回的是表中所有除了赛选条件以外的记录对象
obj = models.employee.object.exclude(id=2)
print(obj)
4.order_by(*field)
# 有参,参数为字段名,可以指定多个字段
# 返回的Queryset对象,但是QuerySet对象中包含的并不是一个个的记录对象,而上多个字典,字典的key即我 们传入的字段名
# 这个时候就不能点取值了
obj = models.employee.object.order_by('id') # 默认是升序的
# 想要降序,就在字段前加上一个-号
5.values(*field)
# 有参,参数为字段名
# 返回值为QuerySet对象,QuerySet对象中包含的并不是一个个的记录对象,而是多个字典,字典的key即我们传入的字段名 ,values是字段对应的值
obj = models.employee.objects.values('id','name')
print(obj)
6.values_list(*field)
# 有参,参数为字段名,可以指定多个字段
# 返回值为QuerySet对象,QuerySet对象中包含的并不是一个个的记录对象,而上多个小元组
# 元组的内容是我们传入的字段的值
obj = models.employee.objects.values_list('id','name')
print(obj)
- 下述方法(除了count外)的返回值都是一个模型类Employee的 对象,为了后续描述方便,我们统一将模型类的对象称为"记录对象",每一个”记 录对象“都唯一对应表中的一条记录,
1.get(**kwargs)
# 有参,参数为筛选条件
# 查出来的结果有且只有一个,只要有多个,报错
# 结果就是一个记录对象,可以直接点操作
obj = models.employee.objects.get(id=1)
print(obj)
2.first() # 取第一个记录对象
# 由于返回的Queryset是一个列表,想要取其中的第一条记录对象
# 所有返回Queryset对象的方法都可以用这个区第一条记录对象
obj = models.employee.objects.filter(id=1).first()
3.last() # 取最后一个记录对象
# 由于Queryset的是一个列表,想要取其中的最后一条记录对象
# 所有返回Queryset对象的方法都可以用这个取最后一条记录对象
obj = models.employee.objects.filter(id=1).last()
4.count()
# 无参
# 返回包含记录的总数量
obj = models.employee.objects.count() # 统计表所有记录的个数
print(obj)
5.distict()
# 对取出来的记录录像去重
# 必须是数据一摸一样的才能去重
6.reverse()
# 反转
# 前提:必须经过排序以后才能反转
# 也就是说将排序号的数据对象,进行反序
7.exists()
# 判断一条记录是否存在
- 并且django的ORM支持链式 操作,于是我们可以像下面这样使用
# 简单示范:
res=models.employee.objects.filter(gender=1).order_by('-id').values_list('id','name') print(res)
先筛选性别为1的所有人,再将他们进行降序排序,然后取id,name字段的值(最后的结果是Queryset对象,[(,),(,)]--列表套元组)
10.3 神奇的双下划线查询
双下划线查询其实就是一些逻辑判断式,查询非等于的条件表达式
1.查询id号大于2的员工
models.employee.objectsfilter(id__gt=2)# select * form employee where id>2
2.查询id号小于2的员工
models.employee.objects.filter(id__lt=2)# select * form employee where id<2
3.查询id为2/4/7的员工
models.employee.objects.filter(id__in=[2,4,7])
# select * form employee where id in(2,4,7)
4.查询id为2-7之间的员工
models.employee.objects.filter(id__range=[2,7])
# select * form employee where id between 2 and 7
5.查询名字中包含p的员工
models.employee.objects.filter(name__contains='p')
# select * form employee where name like binary '%p%'
# 注意:此方法区分大小写
# 忽略大小写
models.employee.objects.filter(name__icontains='p')
# select * form employee where name like '%p%'
6.查询名字以p字符开头的员工
models.employee.objects.filter(name__startwith='p') # 区分大小写
# select * form employee where name like 'p%'
7.查询名字以p字符结尾的员工
models.employee.objects.filter(name__endwith='p') # 区分大小写
# select * form employee where name like '%p'
8.查询出生年份为1999年的人
models.employee.objects.filter(name__year='2019')
# select * form employee where brith between '1999-01-01' and '1999-12-30'
8.查询出生月份为5年的人
models.employee.objects.filter(name__monthr='5')
# select * form employee where extra(mounth from employee.brith)=5
10.4 修改数据
# 方式一:
models.employee,objects.filter(id=1).update(name='xxx',gender=1)
# 修改id为1的员工的名字为xxx,性别为1
# 方式二: 这种方法不推荐使用
# 因为效率比较低
# 相当于把这条记录重新写了一遍,没改值的重写写一遍,改了值的改掉
obj = models.employee,objects.filter(id=1).first()
obj.name='xxx'
obj.gender=1
obj.save
10.5 删除数据
1.直接删除单条数据
models.employee.objects.filter(id=1).first().delete()
2.删除多条数据
models.employee.objects.filter(id__gt=5).delete()