hive中UDF、UDTF、UDAF快速上手
在hive中新建表”apache_log”
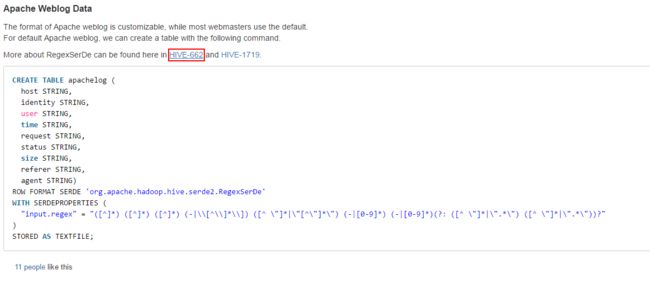
CREATE TABLE apachelog (
host STRING,
identity STRING,
user STRING,
time STRING,
request STRING,
status STRING,
size STRING,
referer STRING,
agent STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "([^ ]*) ([^ ]*) ([^ ]*) (-|\\[[^\\]*\\]]) ([^ \"]*|\"[^\"]*\") (-|[0-9]*) (-|[0-9]*) (?: ([^ \"]*|\".*\") ([^ \"]*|\".*\"))?"
)
STORED AS TEXTFILE;这个是官方给出的实例,但是是错的。
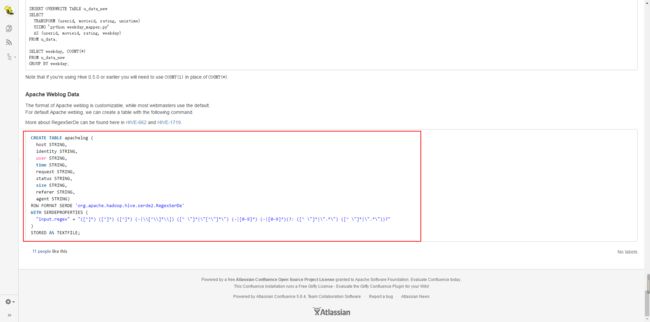
不过,已经有人给做出了修改。
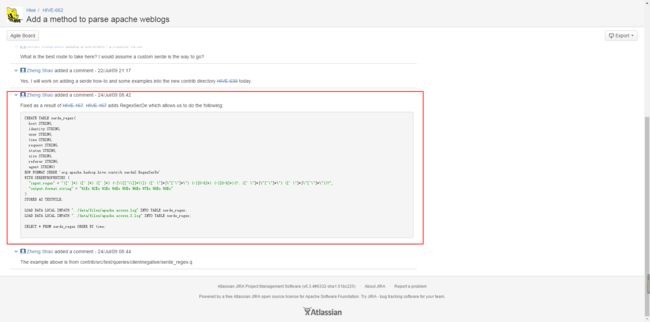
接下来结合一些样例数据(样例数据会在评论中给出下载连接):
27.19.74.143 - - [29/April/2016:17:38:20 +0800] "GET /static/image/common/faq.gif HTTP/1.1" 200 1127
110.52.250.126 - - [29/April/2016:17:38:20 +0800] "GET /data/cache/style_1_widthauto.css?y7a HTTP/1.1" 200 1292
27.19.74.143 - - [29/April/2016:17:38:20 +0800] "GET /static/image/common/hot_1.gif HTTP/1.1" 200 680
27.19.74.143 - - [29/April/2016:17:38:20 +0800] "GET /static/image/common/hot_2.gif HTTP/1.1" 200 682
27.19.74.143 - - [29/April/2016:17:38:20 +0800] "GET /static/image/filetype/common.gif HTTP/1.1" 200 90
110.52.250.126 - - [29/April/2016:17:38:20 +0800] "GET /source/plugin/wsh_wx/img/wsh_zk.css HTTP/1.1" 200 1482
110.52.250.126 - - [29/April/2016:17:38:20 +0800] "GET /data/cache/style_1_forum_index.css?y7a HTTP/1.1" 200 2331
110.52.250.126 - - [29/April/2016:17:38:20 +0800] "GET /source/plugin/wsh_wx/img/wx_jqr.gif HTTP/1.1" 200 1770
27.19.74.143 - - [29/April/2016:17:38:20 +0800] "GET /static/image/common/recommend_1.gif HTTP/1.1" 200 1028
110.52.250.126 - - [29/April/2016:17:38:20 +0800] "GET /static/image/common/logo.png HTTP/1.1" 200 4542
......这个是apache服务器的日志信息,一共七个字段,分别表示:”host”、”identity”、”user”、”time”、”request”、”status”、”size”,在hive官网上是有九个字段的,剩下两个为:”referer”、”agent”。
我们根据这些数据,从一些小需求中来体会一下这三种函数。
UDF(user-defined functions)
“小”需求:
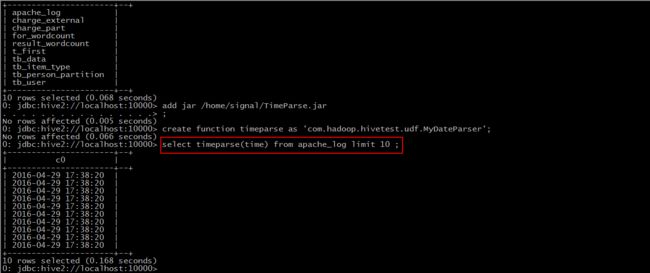
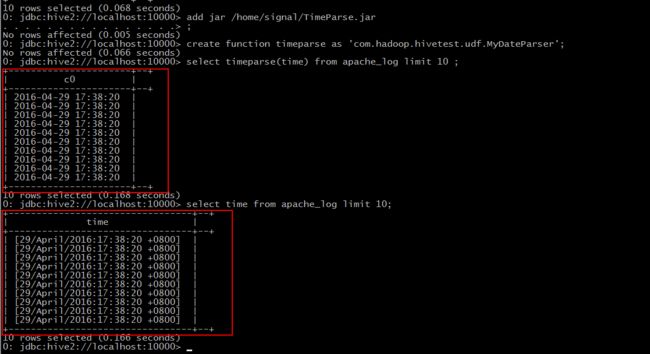
提取”time”,转换成”yyyy-MM-dd HH:mm:ss” 格式。
要点:
1.继承自“org.apache.hadoop.hive.ql.exec.UDF”;
2.实现”evaluate()”方法。
*JAVA 代码*
package com.hadoop.hivetest.udf;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Locale;
import org.apache.hadoop.hive.ql.exec.UDF;
public class MyDateParser extends UDF{
public String evaluate(String s){
SimpleDateFormat formator = new SimpleDateFormat("dd/MMMMM/yyyy:HH:mm:ss Z",Locale.ENGLISH);
if(s.indexOf("[")>-1){
s = s.replace("[", "");
}
if(s.indexOf("]")>-1){
s = s.replace("]", "");
}
try {
//将输入的string转换成date数据类型
Date date = formator.parse(s);
SimpleDateFormat rformator = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
return rformator.format(date);
} catch (ParseException e) {
e.printStackTrace();
return "";
}
}
}小插曲
导出为jar包,发送到Linux上。这次我们可以使用 editplus 编辑器来上传:
– 打开editplus,选择”File—FTP—FTP Setting” –

– 选择添加 –
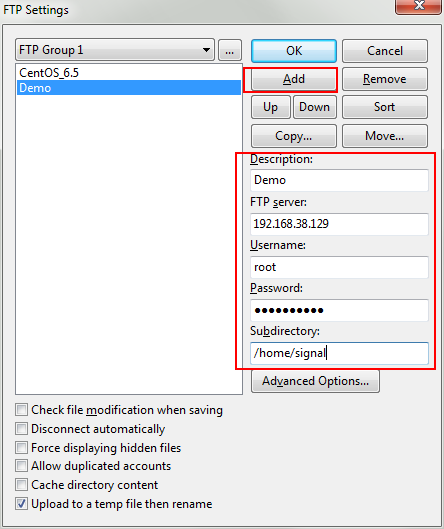
并且在相应的字段上填上值,对于”Subdirectory”这一项要填写的是你希望上传到Linux上的哪个目录。
– 点击”Advanced Options” –
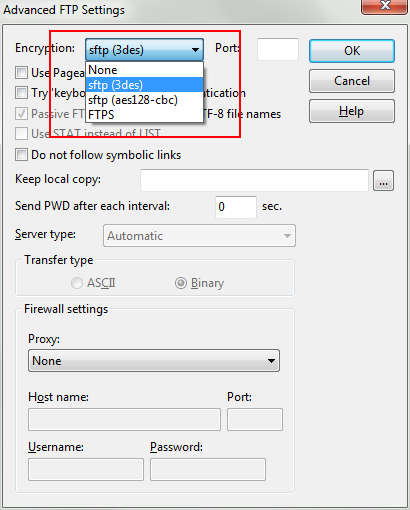
之后便可以一路OK回去。
– 选择FTP Upload –
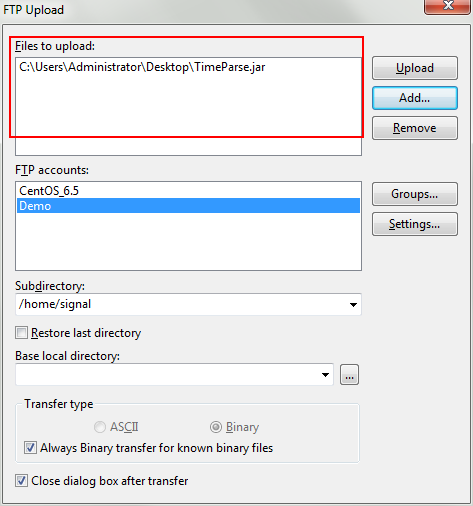
在这里找到要上传的文件,选择要上传到哪一个账户上,并选择”Upload”即可。
然后我们就可以在”Subdirectory”中写到的目录下去找我们的文件了。

– 小插曲结束 –
之后我们使用beeline客户端来连接hive
然后我们可以新建一个数据库,并使用之前的建表语句来创建”apache_log”,并导入数据(默认大家都会了^.^)。
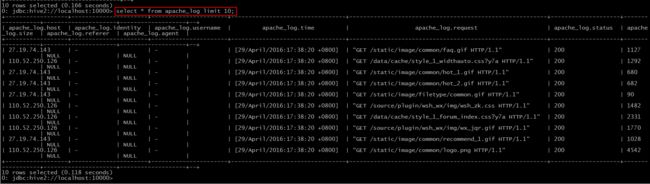
Step 1: add jar “jar-path”
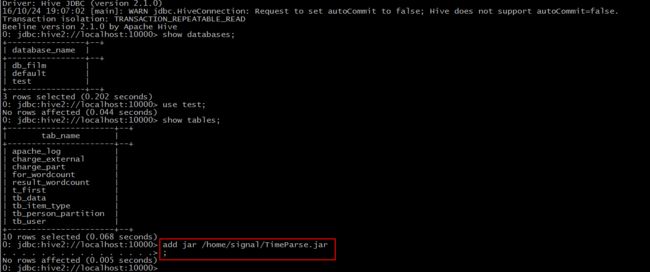
Step 2: create function timeparse as ‘包名+类名’
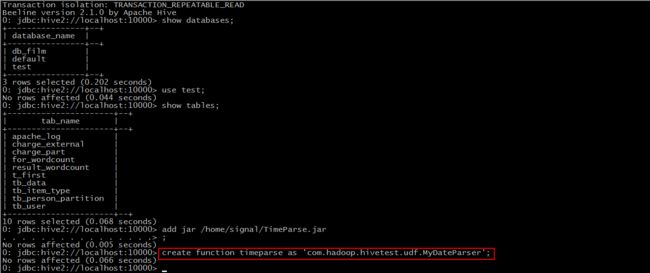
Step 3: 使用该函数
对比之前我们导入的数据
UDTF(user-defined table-generating functions)
“小”需求:
针对”request”字段,将其拆分,获取到用户的请求连接。
第一部分表示请求的方式,第二部分为用户请求的连接,第三部分为协及版本号。
要点:
1.继承自”org.apache.hadoop.hive.ql.udf.generic.GenericUDTF”;
2.实现initialize()、process()、close()三个方法。
*JAVA代码
package com.hadoop.hivetest.udf;
import java.util.ArrayList;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
public class MyRequestParser extends GenericUDTF {
@Override
public StructObjectInspector initialize(ObjectInspector[] arg0) throws UDFArgumentException {
if(arg0.length != 1){
throw new UDFArgumentException("参数不正确。");
}
ArrayList fieldNames = new ArrayList();
ArrayList fieldOIs = new ArrayList();
//添加返回字段设置
fieldNames.add("rcol1");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
fieldNames.add("rcol2");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
fieldNames.add("rcol3");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
//将返回字段设置到该UDTF的返回值类型中
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);
}
@Override
public void close() throws HiveException {
}
//处理函数的输入并且输出结果的过程
@Override
public void process(Object[] args) throws HiveException {
String input = args[0].toString();
input = input.replace("\"", "");
String[] result = input.split(" ");
//如果解析错误或失败,则返回三个字段内容都是"--"
if(result.length != 3){
result[0] = "--";
result[1] = "--";
result[2] = "--";
}
forward(result);
}
}
依照上面的步骤,导出jar包,上传到Linux服务器上。在此不再赘述,其实是攒着另一种上传文件的方式,下次教给大家。
Step 1: add jar “jar-path”
略
Step 2: create function requestparse as ‘包名+类名’
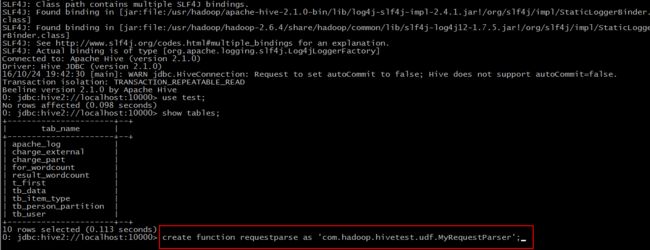
Step 3: 使用该函数
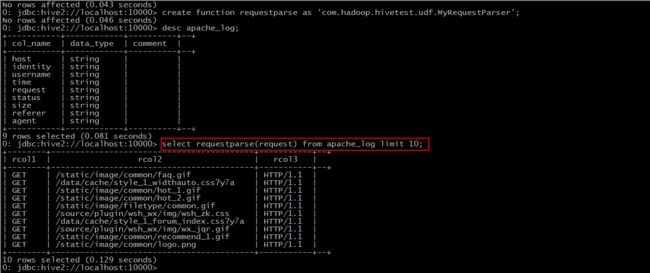
对比我们之前导入的数据
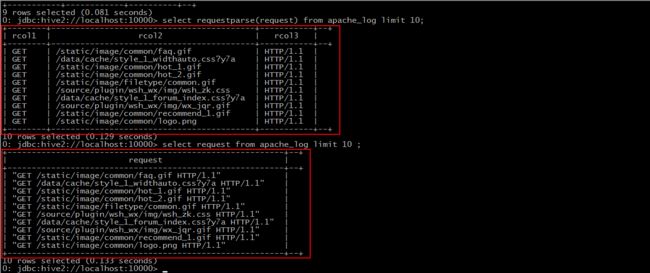
UDAF(user-defined aggregation functions)
“小”需求:
求出最大的流量值
要点:
1.继承自”org.apache.hadoop.hive.ql.exec.UDAF”;
2.自定义的内部类要实现接口”org.apache.hadoop.hive.ql.exec.UDAFEvaluator”;
3.要实现iterate()、terminatePartial()、merge()、terminate()四个方法。
*JAVA代码
package com.hadoop.hivetest.udf;
import org.apache.hadoop.hive.ql.exec.UDAF;
import org.apache.hadoop.hive.ql.exec.UDAFEvaluator;
import org.apache.hadoop.io.IntWritable;
@SuppressWarnings("deprecation")
public class MaxFlowUDAF extends UDAF {
public static class MaxNumberUDAFEvaluator implements UDAFEvaluator{
private IntWritable result;
public void init() {
result = null;
}
//聚合的多行中每行的被聚合的值都会被调用interate方法,所以这个方法里面我们来定义聚合规则
public boolean iterate(IntWritable value){
if(value == null){
return false;
}
if(result == null){
result = new IntWritable(value.get());
}else{
//需求是求出流量最大值,在这里进行流量的比较,将最大值放入result
result.set(Math.max(result.get(), value.get()));
}
return true;
}
//hive需要部分聚合结果时会调用该方法,返回当前的result作为hive取部分聚合值得结果
public IntWritable terminatePartial(){
return result;
}
//聚合值,新行未被处理的值会调用merge加入聚合,这里直接调用上面定义的聚合规则方法iterate
public boolean merge(IntWritable other){
return iterate(other);
}
//hive需要最后总聚合结果时调用的方法,返回聚合的最终结果
public IntWritable terminate(){
return result;
}
}
}导出jar包,上传到Linux服务器…
Step 1: add jar ‘jar-path’
略
Step 2: create function maxflow as ‘包名+类名’
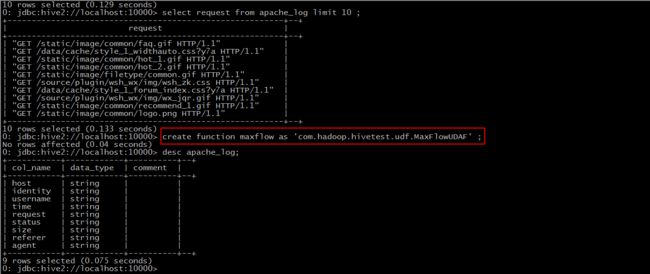
Step 3: 使用该函数

于是此时,hive便会将sql语句转换为mapreduce任务去执行了。
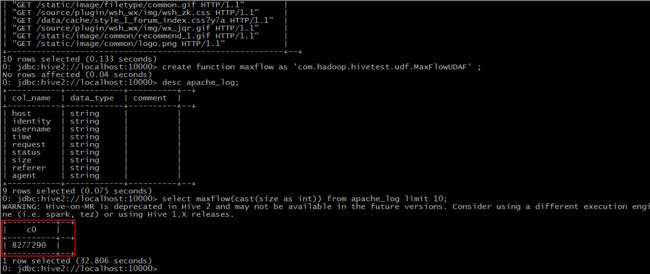
当我们创建函数之后,得出的结果却不是想要的结果的时候,我们将Java代码修改之后,重新打了包上传过来,也重新加到了hive的classpath中,但是新创建出来的函数得出的结果跟修改之前的一样。这个因为新修改过后的类名与之前的类名重复了,在当前session中会优先以之前的来创建函数。此时有两种办法解决,一是断开当前的连接,重新使用beeline客户端登陆一次,还有就是将修改后的Java类改一个名称,重新导入,使用新的Java类来创建函数。
当然,这些才都只是 UDF 的小皮毛,我们可以发现,通过自定义函数,我们可以省去写很多sql,并且通过使用api,我们可以更随意的操作数据库里的字段,实现多种计算和统计。