Sqoop-1.99.7 简单使用
经过上一篇,我们已经安装并且配置好了 sqoop2,这一篇我们通过两个实例来简单使用一下。
1.HDFS ⇒ Mysql
1.1启动服务
[root@master ~]# sqoop2-server start1.2启动客户端
[root@master ~]# sqoop2-shell
Setting conf dir: /usr/hadoop/sqoop-1.99.7/bin/../conf
Sqoop home directory: /usr/hadoop/sqoop-1.99.7
Sqoop Shell: Type 'help' or '\h' for help.
sqoop:000> \h
For information about Sqoop, visit: http://sqoop.apache.org/
Available commands:
:exit (:x ) Exit the shell
:history (:H ) Display, manage and recall edit-line history
help (\h ) Display this help message
set (\st ) Configure various client options and settings
show (\sh ) Display various objects and configuration options
create (\cr ) Create new object in Sqoop repository
delete (\d ) Delete existing object in Sqoop repository
update (\up ) Update objects in Sqoop repository
clone (\cl ) Create new object based on existing one
start (\sta) Start job
stop (\stp) Stop job
status (\stu) Display status of a job
enable (\en ) Enable object in Sqoop repository
disable (\di ) Disable object in Sqoop repository
grant (\g ) Grant access to roles and assign privileges
revoke (\r ) Revoke access from roles and remove privileges
For help on a specific command type: help command
sqoop:000> 1.3简单配置
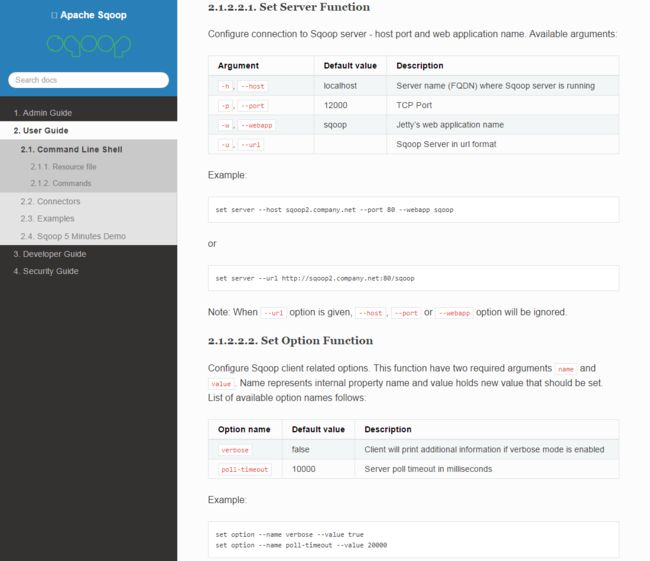
像官网上介绍的,有许多可选项可以供我们设置,对于 verbose 这一项建议设置成为 true,它默认是 false,表示不会在输出过多信息。设置成 true 可以显示更多信息,有助于我们的学习。
sqoop:000> set option --name verbose --value true
Verbose option was changed to true
sqoop:000> 之后设置连接 sqoop2 服务器
sqoop:000> set server --host master --port 80 --webapp sqoop
Server is set successfully
sqoop:000> 我们可以使用 show version –all 命令来验证是否连接成功,显示的版本是我们安装的就表示连接成功了
sqoop:000> show version -all
client version:
Sqoop 1.99.7 source revision 435d5e61b922a32d7bce567fe5fb1a9c0d9b1bbb
Compiled by abefine on Tue Jul 19 16:08:27 PDT 2016
server version:
Sqoop 1.99.7 source revision 435d5e61b922a32d7bce567fe5fb1a9c0d9b1bbb
Compiled by abefine on Tue Jul 19 16:08:27 PDT 2016
API versions:
[v1]
sqoop:000> 这些设置使用的命令都可以在官网的文档了查询到。
1.4创建 HDFS 的 Link对象
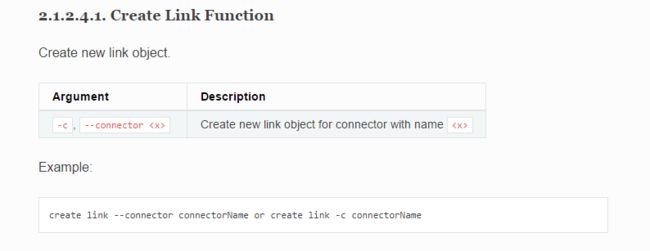
文档里给出了创建 Link 所使用的命令,但是,对于 connectorName 我们要使用什么呢。所以我们可以使用 show connector 命令来查看一下 sqoop2 提供有什么 connector:

如图,有这么多,我们先来创建 hdfs-connector 的吧:
要使用到的参数如下:
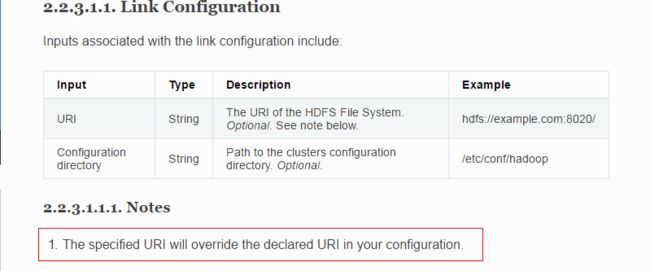
sqoop:000> create link --connector hdfs-connector
Creating link for connector with name hdfs-connector
Please fill following values to create new link object
Name: HDFS # 要创建的 link 的名称(必填)
HDFS cluster
URI: hdfs://master:9000/ # 这里要填的就是我之前要大家记住的 fs.defaultFS 的值(必填)
Conf directory: /usr/hadoop/hadoop-2.6.4/etc/hadoop # hadoop配置文件的目录(必填)
Additional configs::
There are currently 0 values in the map:
entry# (选填)
New link was successfully created with validation status OK and name HDFS
sqoop:000> 1.5创建 MYSQL 的 Link 对象
使用 generic-jdbc-connector 来创建 mysql 的 link:
要使用到的参数如下:
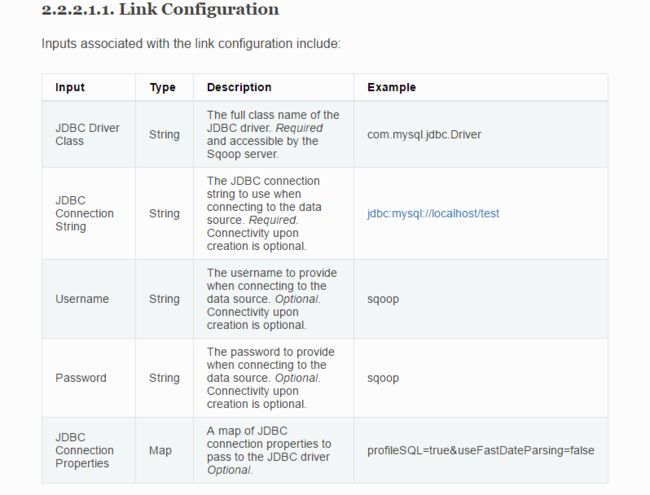
sqoop:000> create link --connector generic-jdbc-connector
Creating link for connector with name generic-jdbc-connector
Please fill following values to create new link object
Name: MYSQL # 要创建的 link 的名称(必填)
Database connection
Driver class: com.mysql.jdbc.Driver # (必填)
Connection String: jdbc:mysql://master:3306/test # (必填)
Username: root # (必填)
Password: ****** # (必填)
Fetch Size: # (选填)
Connection Properties: # (选填)
There are currently 0 values in the map:
entry# # (选填)
SQL Dialect
Identifier enclose: # (必填,这里是个空格)
New link was successfully created with validation status OK and name MYSQL
sqoop:000> 现在,我们的两个 Link 对象就创建成功了,可以使用 show link 命令来查看我们所有的 link
sqoop:000> show link
+------------+------------------------+---------+
| Name | Connector Name | Enabled |
+------------+------------------------+---------+
| MYSQL | generic-jdbc-connector | true |
| HDFS | hdfs-connector | true |
+------------+------------------------+---------+
sqoop:000> 这样看到的是简略信息,可以使用 show link -all 命令查看详细信息:
sqoop:000> show link -all
2 link(s) to show:
link with name MYSQL (Enabled: true, Created by root at 11/16/16 8:32 PM, Updated by root at 11/16/16 8:32 PM)
Using Connector generic-jdbc-connector with name {1}
Database connection
Driver class: com.mysql.jdbc.Driver
Connection String: jdbc:mysql://master:3306/test
Username: root
Password:
Fetch Size:
Connection Properties:
SQL Dialect
Identifier enclose:
link with name HDFS (Enabled: true, Created by root at 11/16/16 8:13 PM, Updated by root at 11/16/16 8:13 PM)
Using Connector hdfs-connector with name {1}
HDFS cluster
URI: hdfs://master:9000/
Conf directory: /usr/hadoop/hadoop-2.6.4/etc/hadoop
Additional configs::
sqoop:000>1.6创建 job 对象
使用到的命令如下:
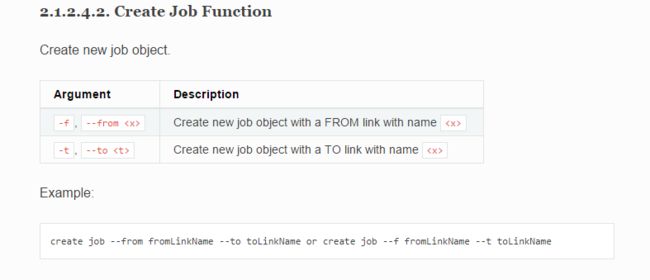
我们创建一个 job 需要指定一个 from link 和一个 to link。这次我们是从 hdfs 上把数据导入到 mysql 中,所以我们可以这样写:
sqoop:000> create job --from HDFS --to MYSQL
Creating job for links with from name HDFS and to name MYSQL
Please fill following values to create new job object
Name: FisrtJob # 要创建的job的名称(必填)
Input configuration
Input directory: /toMysql # 数据来源于hdfs上的哪个目录(必填)
Override null value: # (选填)
Null value: # (选填)
Incremental import
Incremental type:
0 : NONE
1 : NEW_FILES
Choose: 0 # (选填)
Last imported date: # (选填)
Database target
Schema name: test # 要导入到哪一个数据库(必填)
Table name: people # 要导入到数据库中的那张表(必填)
Column names: # 要导入到表中的哪些列(选填)
There are currently 0 values in the list:
element# # (选填)
Staging table: # (选填)
Clear stage table: # (选填)
Throttling resources
Extractors: # (选填)
Loaders: # (选填)
Classpath configuration
Extra mapper jars: # (选填)
There are currently 0 values in the list:
element# # (选填)
New job was successfully created with validation status OK and name FisrtJob
sqoop:000> 虽然不明所以的创建成功了,但是我们有必要了解一些这些参数都是个什么意思吧:
官网上放出来的是这样的:
对于 hdfs 是 from,参数有如下:

对于 mysql 是 to ,参数有如下:
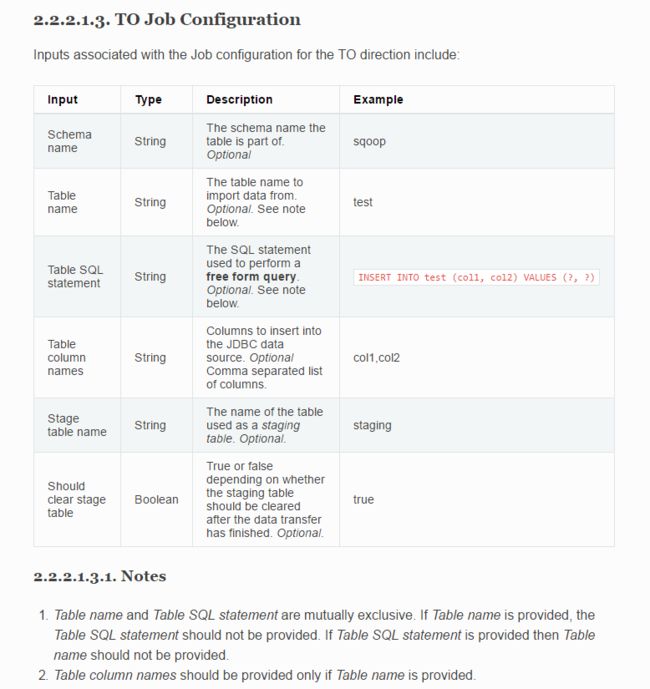
当然,我只是贴上来了一部分,我希望大家能够学会这种思路,好日后看文档的时候能够很快找到需要的东西。
1.7启动 job
要使用的命令如下:
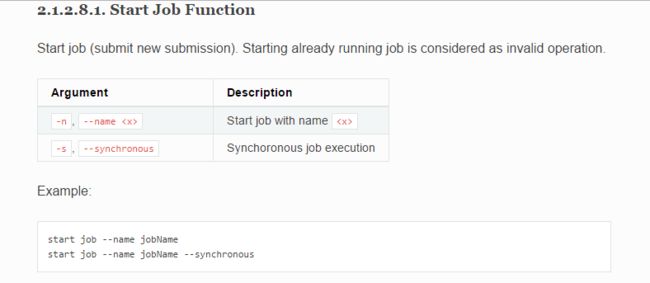
如果我们就是这样就启动的话,肯定会给你报一堆错。想想看,我们的 hdfs 上有数据吗,我们的数据库有 people 这张表吗?
我一时之间找不到官网上介绍了,大概意思就是,如果要往数据库中导数据的话,文件中的内容是以”,“逗号为分割的。这里我随便写了一个文件,将这个文件保存为 csv 格式,上传到 hdfs 上的 /toMysql 目录中
![]()
文件内容如下:
1,Signal,male
2,Hathway,female
3,May jay lee,beauty然后,我在 mysql 数据库中创建了 test,在 test 中创建了 people 这张表。
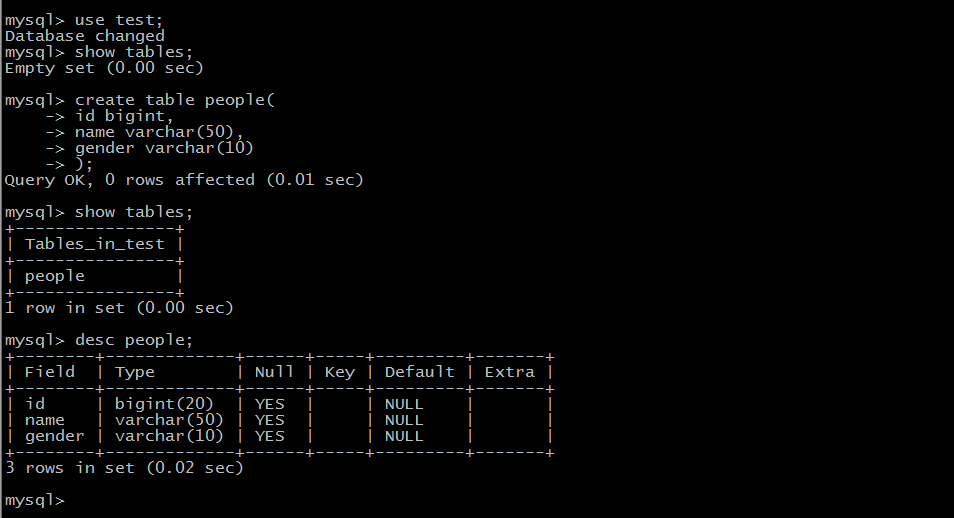
到这儿,我们的准备工作就做好了,接下来我们就可以启动 job 了。
先查看一下我们的 job
sqoop:000> show job
+----+--------------+------------------------------------+----------------------------------+---------+
| Id | Name | From Connector | To Connector | Enabled |
+----+--------------+------------------------------------+----------------------------------+---------+
| 1 | FisrtJob | HDFS (hdfs-connector) | MYSQL (generic-jdbc-connector) | true |
+----+--------------+------------------------------------+----------------------------------+---------+
sqoop:000> 启动:
sqoop:000> start job --name FisrtJob
Submission details
Job Name: FisrtJob
Server URL: http://master:12000/sqoop/
Created by: root
Creation date: 2016-11-16 21:27:16 CST
Lastly updated by: root
External ID: job_1479259884185_0002
http://master:8088/proxy/application_1479259884185_0002/
2016-11-16 21:27:16 CST: BOOTING - Progress is not available
sqoop:000>这个时候我们可以使用浏览器,访问:http://master:8088 来查看运行状态
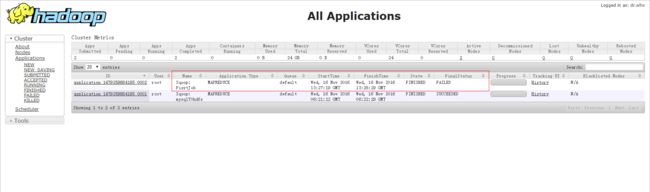
这里看到我的失败了^_^
但是,我查看数据库的时候发现,写进去两条:
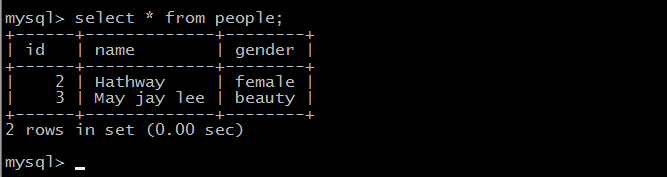
于是乎,我追进去看日志,发现果然报错了:
Caused by: java.lang.NumberFormatException: For input string: "1"
at java.lang.NumberFormatException.forInputString(NumberFormatException.java:65)
at java.lang.Long.parseLong(Long.java:589)
at java.lang.Long.valueOf(Long.java:803)
at org.apache.sqoop.connector.common.SqoopIDFUtils.toFixedPoint(SqoopIDFUtils.java:152)
at org.apache.sqoop.connector.common.SqoopIDFUtils.toObject(SqoopIDFUtils.java:724)
at org.apache.sqoop.connector.common.SqoopIDFUtils.fromCSV(SqoopIDFUtils.java:792)
at org.apache.sqoop.connector.common.SqoopIDFUtils.fromCSV(SqoopIDFUtils.java:765)
at org.apache.sqoop.connector.idf.CSVIntermediateDataFormat.getObjectData(CSVIntermediateDataFormat.java:77)
at org.apache.sqoop.job.mr.SqoopMapper$SqoopMapDataWriter.writeContent(SqoopMapper.java:165)
... 25 more找到错误的源头了,肯定是我的 people.csv 文件中的数据出来问题,于是按照之前的再来一遍…..
(未补充)
现在是简单体验了一下 hdfs 导出到 mysql,我们接下来试试官网上的例子,官网上是从 mysql 导出到 hdfs 上。
2. Mysql ⇒ Hdfs
我们依然使用之前创建的 MYSQL 和 HDFS 的 link 对象,link对象可以重复使用。
2.1 创建 job 对象
命令什么鬼的我之前都贴上来了,大家忘记了的可以返回去看看,不过我更希望能去看官方文档。
sqoop:000> create job --from MYSQL --to HDFS
Creating job for links with from name MYSQL and to name HDFS
Please fill following values to create new job object
Name: SecondJob # 要创建的job对象的名称(必填)
Database source
Schema name: test # 数据来源于哪个数据库(必填)
Table name: people # 数据来源于数据库中的哪张表(选填)
SQL statement: # SQL语句(选填)
Column names: # 列名(选填)
There are currently 0 values in the list:
element# # (选填)
Partition column: # (选填)
Partition column nullable: # (选填)
Boundary query: # (选填)
Incremental read
Check column: # (选填)
Last value: # (选填)
Target configuration
Override null value: # (选填)
Null value: # (选填)
File format:
0 : TEXT_FILE
1 : SEQUENCE_FILE
2 : PARQUET_FILE
Choose: 0 # (必填)
Compression codec:
0 : NONE
1 : DEFAULT
2 : DEFLATE
3 : GZIP
4 : BZIP2
5 : LZO
6 : LZ4
7 : SNAPPY
8 : CUSTOM
Choose: 0 # (必填)
Custom codec: # (选填)
Output directory: /OutputMysql # 输出到 hdfs 上的哪个目录
Append mode: true # (选填)
Throttling resources
Extractors: # (选填)
Loaders: # (选填)
Classpath configuration
Extra mapper jars: # (选填)
There are currently 0 values in the list:
element# # (选填)
New job was successfully created with validation status OK and name SecondJob
sqoop:000> 这里有一些参数的说明:
from jdbc job Configuration:
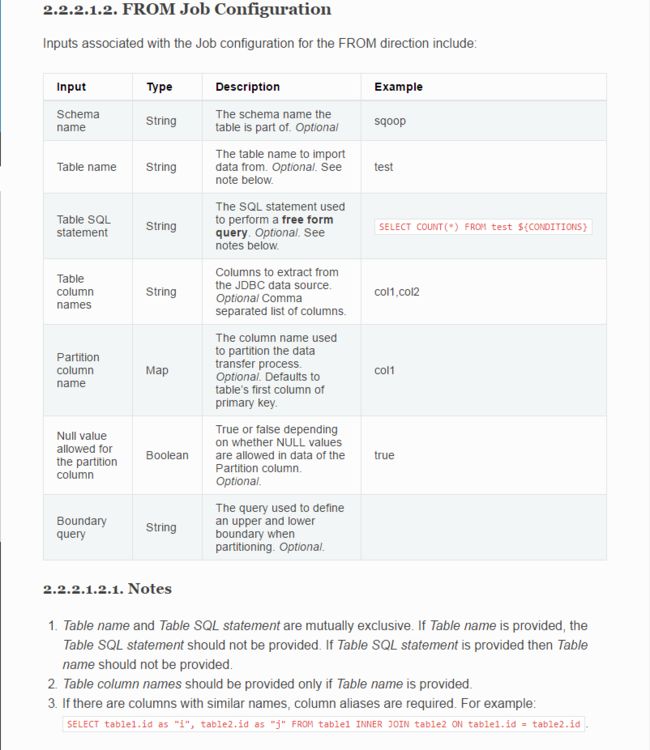
这里我们需要注意的就是,表名称和 SQL 语句只能选填其中一项。如果表中存在有相同字段,则需要给相应的字段设置别名。
to hdfs job Configuration:
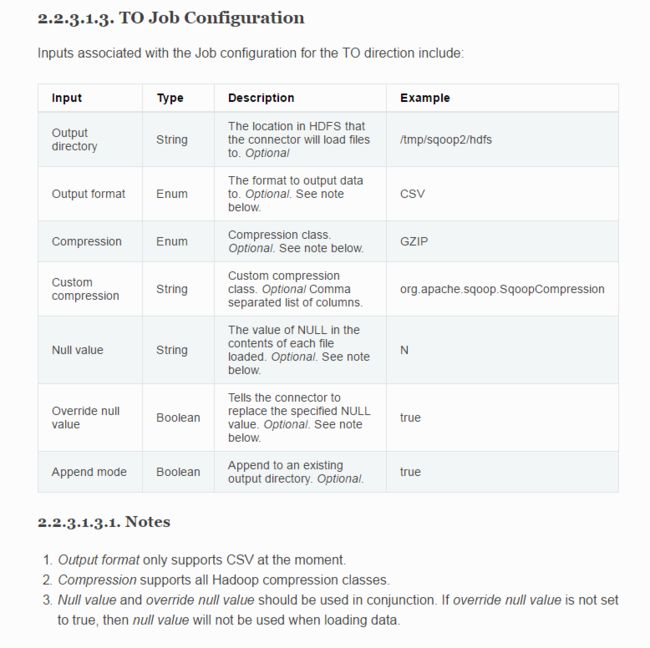
2.2 启动 job
sqoop:000> show job
+----+--------------+------------------------------------+----------------------------------+---------+
| Id | Name | From Connector | To Connector | Enabled |
+----+--------------+------------------------------------+----------------------------------+---------+
| 1 | FisrtJob | HDFS (hdfs-connector) | MYSQL (generic-jdbc-connector) | true |
| 2 | SecondJob | MYSQL (generic-jdbc-connector) | HDFS (hdfs-connector) | true |
+----+--------------+------------------------------------+----------------------------------+---------+
sqoop:000> start job --name SecondJob
Exception has occurred during processing command
Exception: org.apache.sqoop.common.SqoopException Message: GENERIC_JDBC_CONNECTOR_0025:No primary key - Please specify partition column.
sqoop:000> ^_^又报错了,因为没有主键,需要指定一下分区的列。因为它默认是按照主键来分区的,然而我建表的时候没有指定主键。所以,这时候需要修改一下 SecondJob
sqoop:000> update job --name SecondJob
Updating job with name SecondJob
Please update job:
Name: SecondJob
Database source
Schema name: test
Table name: people
SQL statement:
Column names:
There are currently 0 values in the list:
element#
Partition column: id # 修改了这里,指定按照 id 列来分区
Partition column nullable:
Boundary query:
Incremental read
Check column:
Last value:
Target configuration
Override null value:
Null value:
File format:
0 : TEXT_FILE
1 : SEQUENCE_FILE
2 : PARQUET_FILE
Choose: 0
Compression codec:
0 : NONE
1 : DEFAULT
2 : DEFLATE
3 : GZIP
4 : BZIP2
5 : LZO
6 : LZ4
7 : SNAPPY
8 : CUSTOM
Choose: 0
Custom codec:
Output directory: /OutputMysql
Append mode: true
Throttling resources
Extractors:
Loaders:
Classpath configuration
Extra mapper jars:
There are currently 0 values in the list:
element#
Job was successfully updated with status OK
sqoop:000> 再启动一次:
sqoop:000> start job --name SecondJob
Submission details
Job Name: SecondJob
Server URL: http://master:12000/sqoop/
Created by: root
Creation date: 2016-11-16 22:15:10 CST
Lastly updated by: root
External ID: job_1479259884185_0003
http://master:8088/proxy/application_1479259884185_0003/
2016-11-16 22:15:10 CST: BOOTING - Progress is not available
sqoop:000> 成功启动,我们使用 webUI 来查看
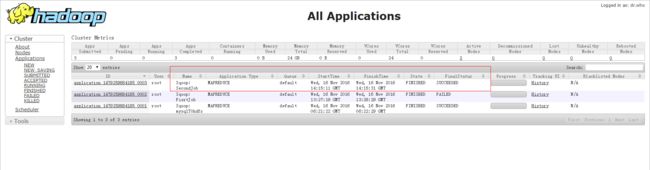
这次可以看到,我们成功了,我们成功了,我们成功了…^U^(得瑟的不知道去哪儿了)
我们可以查看一下 hdfs 上 /OutputMysql 目录下是否有文件

我们可以看到,已经成功的导出了 people 表中的数据,为什么没有1号的呢,因为我之前那个错还没解决呢!
总结
1 为什么不使用 status 命令查看 job 的运行状态
答:一是因为 webUI 更好用,当 job 运行的时候,你去某个节点上 jps 一下,会发现有几个 YarnChild 和 AppMaster 的进程。所以,sqoop2也是由 yarn 框架来管理的,我们可以通过 http://hostname:8088 来查看进程的运行的状态。而且真的挺好用的,谁用谁知道。
二是因为
sqoop:000> status job --name FisrtJob
Exception has occurred during processing command
Exception: org.apache.sqoop.common.SqoopException Message: MAPREDUCE_0003:Can't get RunningJob instance -
sqoop:000>看到了,这就是 status 命令的执行结果!具体原因还没有研究出来。(未解决)
2 关于从 hdfs 导出到 mysql 的一些东西
后来发现,要是建表时指定了主键,从 hdfs 导数据进来的时候是有序的,如果没有主键则是无序的。这个试验的比较少,按照数学上的抽样调查来说,样本不具有代表性…别听我瞎扯,这一点我也不确定。
从 mysql 导出到 hdfs 时,表没有主键的话必须指定按照哪一列来分区,哈哈,这个是千真万确的。
未完待续…