关于布隆过滤器的本质
最早在吴军博士的《数学之美》上了解到布隆过滤器(Bloom Filter),它能以 O(1) 的时间代价完成集合元素的检索和插入,并以最小的空间代价保证了假正例(False Positive)概率不大于给定阈值。当时感觉得这东西是一个加强版的哈希表,后来算了一下发现确实如此:布隆过滤器的本质就是利用若干个哈希表的检索结果进行投票表决。
我们先来看一个普通哈希表做集合元素检索的效率。设全集为 S={a1,a2,...,an}, h(x):S→{0,1,...,m−1} 为某哈希函数将 S 映到一个长为 m 的数组 A 上,满足 A[h(ai)]=1. A 中的其他元素均置0.
现在有一个新元素 b ,我们想知道它是否也在集合 S 中。要下这个判断,我们只需计算 h(b) ,然后看 A[h(b)] 是否为0就行了。
然而这样会出现问题。当 b 和某个 aj≠b 的哈希地址发生冲撞时,我们会错误地判定 b∈S ,这就是假正例。我们可以计算一下这种情况发生的概率。假设我们的哈希函数 h 取得足够好,其值域在 {0,1,...,m−1} 中几乎分布均匀。那么 h(b) 和某个 h(aj) 不发生冲撞的概率为 (1−1m), 和任一 h(aj) 都不发生冲撞的概率为 (1−1m)n ,于是出错的概率为
注意到上式中 n 为定值,出错概率 P1 为空间开销 m 的减函数。为让 P1(m) 尽可能小,只能让 m 取得更大。由此可见出错概率和空间开销这两者是一对此消彼长的矛盾关系。
那么,通过牺牲空间代价来换取更小的出错率,除了把 m 取得更大,有没有其他更好的办法呢?显然是有的。我们可以取多个彼此独立的哈希函数 hi(x),i=1,2,...,k, 如法炮制出 k 个这样的数组 A1,A2,...,Ak .新来一个 b ,每一个 Ai 均会对 b 是否属于 S 下一个判断。显然,只要有一个 Ai 表示 b∉S ,那么 b 就一定不属于 S .出错的情况只可能有一种,就是 A1,A2,...,Ak 在检测 b 时均发生了地址冲撞。这件事情的概率是
好了,若现在就断言第二种方法要优于第一种,我们并一定买账。为证明这一点,我们不妨比较一下在同样空间开销 O(km) 下两个模型的出错概率:
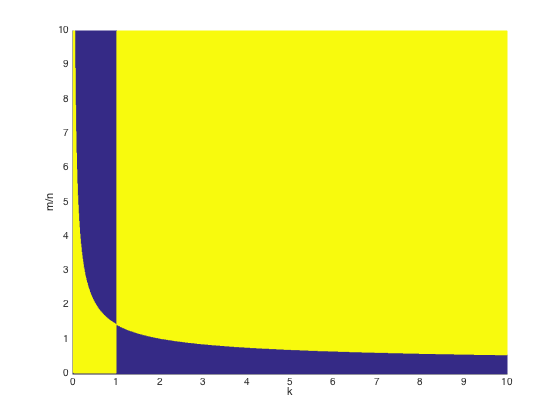
下图显示了在不同的参数下 P1(km) 与 P2(km) 的关系。其中横坐标为 k ,纵坐标为 m/n ,黄色区域表示 P1(km)>P2(km) ,蓝色区域表示 P1(km)≤P2(km) .在实际中 k>1 是显然成立的,因此只需要保证 k>1.5 我们就能断定第二种方法的效率要高于第一种。
不难看出,将 k 个bit array连起来,第二种方法正是一个典型的布隆过滤器。