爬虫系列(五)--爬取商城评论数据
爬虫系列(五)--爬取商城评论数据
这篇标题是爬取评论数据,实际上是一种类型的数据爬取。比如网页的下拉加载数据,使用js动态加载的数据。这类数据有一些爬取起来会比较麻烦,可能要深入分析目标页面运行机理。
迟迟没有写这个,原因是图片太多,步骤会多一点,有些麻烦。不过不用担心,这些步骤很简单,操作两次就熟悉起来了。也许你刚开始会觉得这一篇爬取数据的方式和之前很不一样,到最后你会惊奇的发现,这一篇内容和前面的内容没有什么差别,本质都是一样的。
1.打开某商城网站
建议用相同的商城网站,不同网页可能会有区别。我使用的是谷歌浏览器,强烈建议保持一致。
2.点开一个商品页面
任意一个商品即可,这里打开的是一本书。本来想打开一个让人想入非非的商品页面,担心被女同志,小学生看到。只好打开一本书了。如果你愿意,可以打开一个不能说的商品页面,但必须有评论。因为我们要抓取评论数据,特殊商品买家可能不好意思评论的。
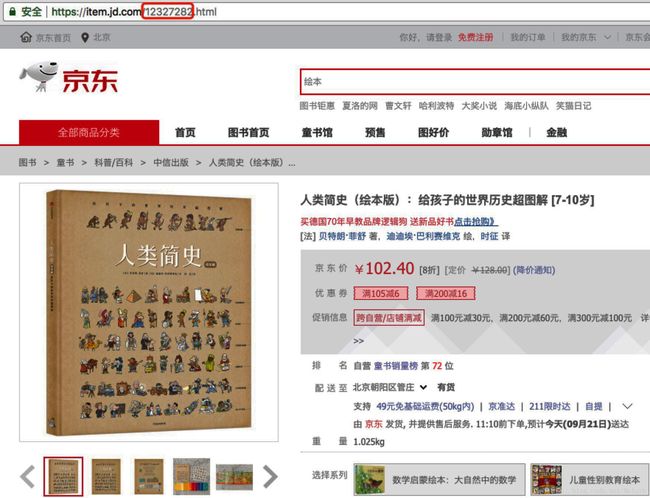
3.找到页面评论带有页码的部位
先不要急着点击下一页,找到这个的目的是为了研究点击下一页评论的时候,该页面做了什么操作。
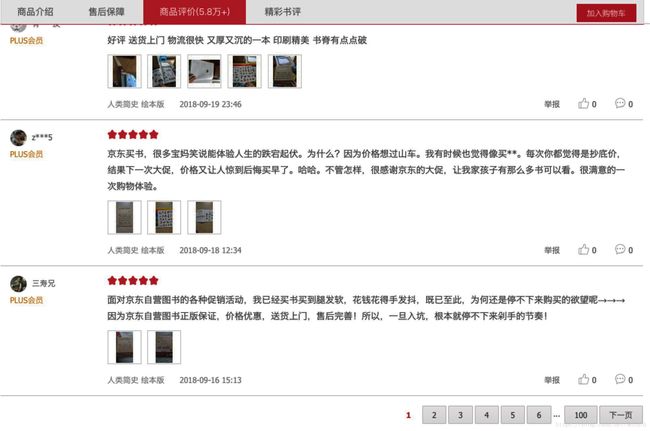
4.打开浏览器开发者工具
打开开发者工具后,如图所示,选择Network,然后点击页面上的“2”
使用开发者工具主要是协助我们了解网页运行机理,我们总不能每爬取一个网页,打开原始的html js文件,去一行一行的看吧。
什么!!!你不知道怎么打开开发者工具!!!好好反省一下吧。真的不知道的话,去百度一下吧。
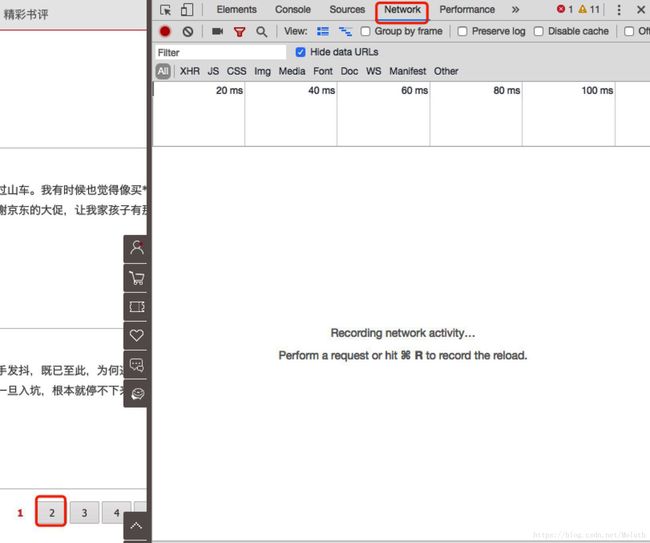
5.分析点击后页面下载的数据
如下图所示,找出要爬取的数据可能的类型,这里我们想要的是文本,不是图片,直接忽略图片数据。可以使用开发者工具的过滤功能。有可能会有多个数据,这时要看响应数据是不是我们想要的。直到找到需要的数据。
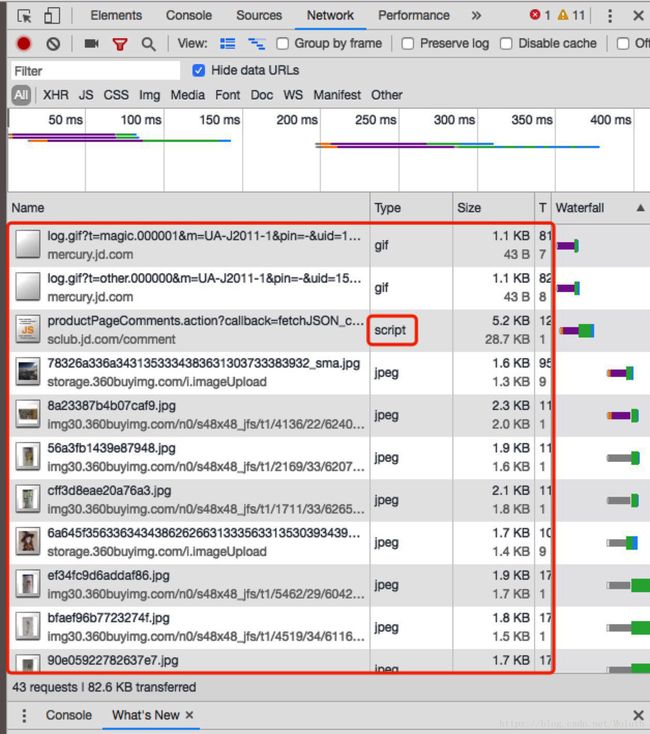
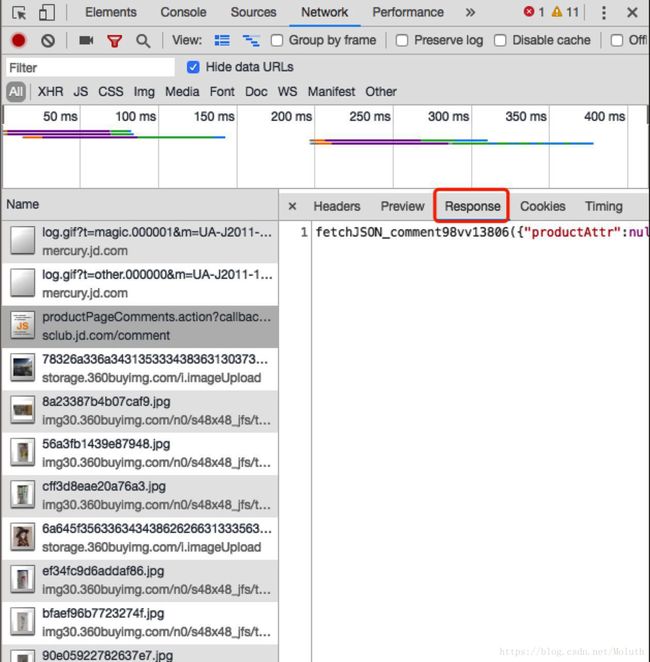
6.复制5中找的数据url
操作步骤如下图,很简单。
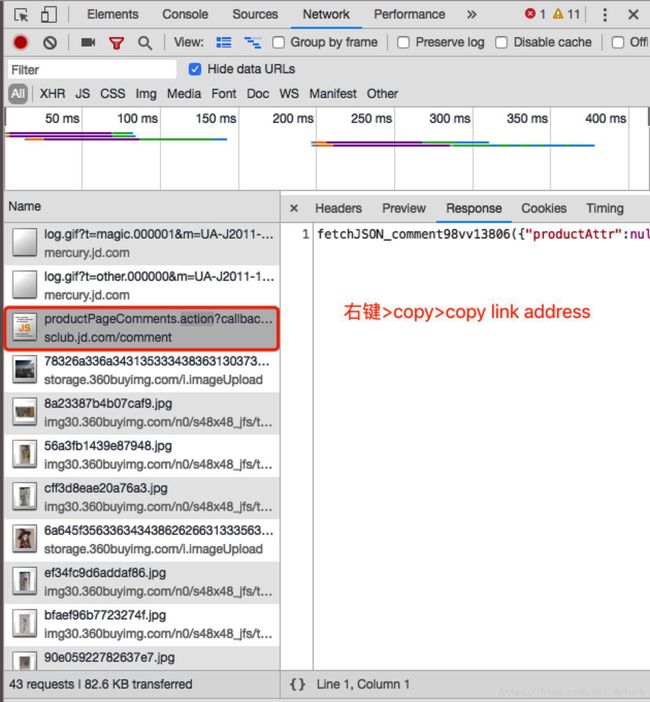
7.把6中复制下来的url粘贴到地址栏中
我复制的地址是:
https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv13806&productId=12327282&score=0&sortType=5&page=1&pageSize=10&isShadowSku=0&rid=0&fold=1这个链接中有几个参数score,sortType,page,pageSize,productId,productId和2中圈出的值是一样的。其他几个参数含义和它们的名称表达的含义一致。具体值是什么意思,你们自己探索吧。好中差评,按时间排序等。
到了这一步,可以在浏览器地址栏中输入的地址,我们用之前几篇的内容,已经可以把需要的数据爬下来了。
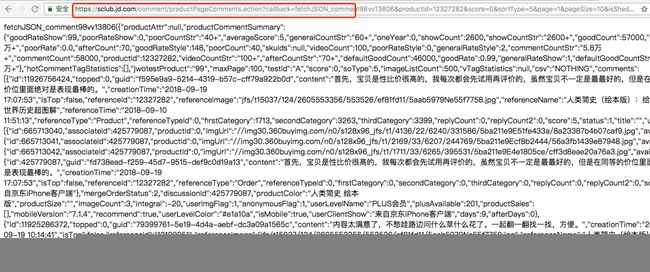
8.把7中结果复制下来,放在json解析工具中
这个数据是js数据,稍微处理一下(删除头部和尾部若干字节即可),中间部分是js数据。

9.简单实现
这里只实现单个商品评论的爬取,如果想实现多个或者全站爬取,需要参考前几篇文章。
#用来爬取京东商品评论
import json
from urllib import request
import time
header_dict = {
"Accept":"application/json, text/javascript, */*; q=0.01",
"Accept-Language":"zh-CN,zh;q=0.9",
"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36",
}
def get_http(load_url,header=None):
res=""
try:
req = request.Request(url=load_url,headers=header)#创建请求对象
coonect = request.urlopen(req)#打开该请求
byte_res = coonect.read()#读取所有数据,很暴力
try:
res=byte_res.decode(encoding='utf-8')
except:
try:
res=byte_res.decode(encoding='gbk')
except:
res=""
except Exception as e:
print(e)
return res
pid="12327282"#页面上的产品id
fout=open("./"+pid+".csv","w",encoding='utf-8')#输出文件
fout.write("uid,nickname,time,star,comment\n")#写csv头 微软的表格打开可能是乱码,解决方法是另存为带BOM头的编码
for score in ["3","2","1"]:#爬取好中差评3好评,2中评,1差评,0默认评论
#这个链接和从网页上的链接不太一样,少了几个参数,加载出来的是json数据。
url0="https://sclub.jd.com/comment/productPageComments.action?productId="+pid+"&score="+score+"&sortType=6&page="
#调整页码,这里只爬取前10页,用于演示,可以写成while True的
for page in range(10):
url=url0+str(page)+"&pageSize=10&isShadowSku=0&rid=0&fold=1"
res=get_http(url,header_dict)
time.sleep(0.1)
if res==None or len(res)<=30:
print("加载错误",url)
continue
jobj=json.loads(res)#解析json
comments=jobj["comments"]
if len(comments)==0:
break
#提取每一页的评论数据并保存
for comment in comments:
userImage=comment["userImage"]
nickname=comment["nickname"]
uid=str(hash(userImage+nickname))[0:18]
content=comment["content"]
creationTime=comment["creationTime"]
score1=str(comment["score"])
fout.write(uid+","+nickname+","+creationTime+","+score1+","+content+"\n")
fout.close()
下一篇文章爬取图片数据。看下一篇之前,可以自己先写一个。下一篇文章可能若干天后才会写。不要着急。