深度网络的过拟合问题讨论
问题背景
最近做深度学习实验的时候遇到了一个很棘手的问题,那就是大名鼎鼎的“过拟合”,直观地表现在图中是长这个样子的,分析来讲就是说深度网络在拟合训练集的时候是可以很好地实现,Loss很小,Accuracy很大(我这儿能达到99.99%),但是呢,测试集的Loss很大,Accuracy在一个比较低的范围内波动(我这儿是70%-80%),并没有像论文中说的那样,测试集的Loss随着迭代的增加而减小,Accuracy随着迭代的增加而增大。
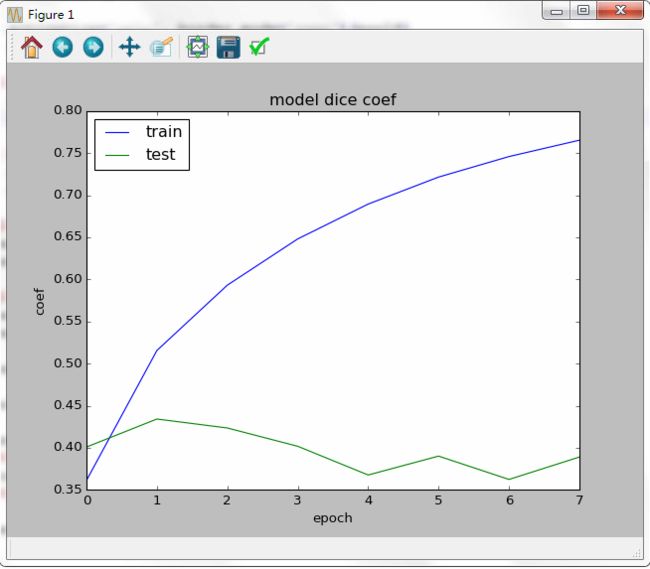
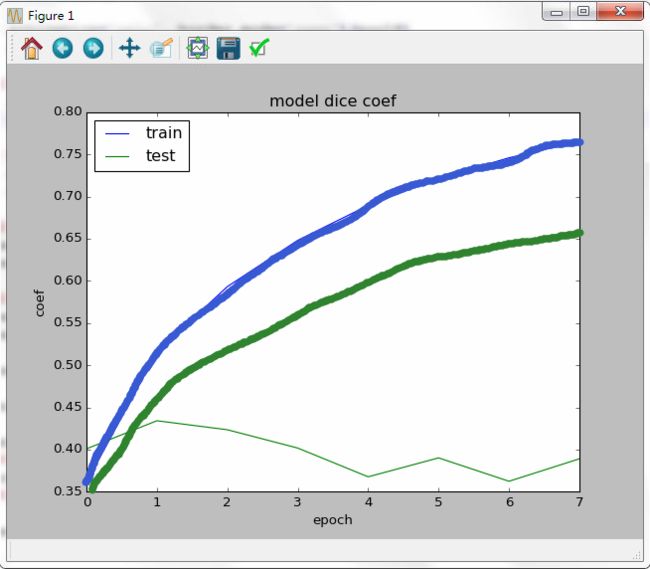
如果你没有看出来上图有什么毛病的话,我就放一张理想状态的结果图做对比(如下图粗粗的线),画的比较挫,但是大概的意思在那儿,随着迭代的增加,训练集和测试集的精确度应该上升,我们可以容忍测试集的精确度没有训练集那么高,毕竟有拟合的误差,但是像上图我做出来的结果那样,一定是“过拟合”啦。
用白话来说“过拟合”就是:老师给你的题你都会做了,考试给你换个花样你就懵逼了。好,老师给你的题就相当于我们的训练数据,考试的题相当于测试数据,“过拟合”就是深度网络把训练的数据拟合的特别好,但是有点好过头了,对训练数据当然是100%好用,但是一来测试数据就疯了,那这样的网络训练出来其实是没有用的,训练集已经是监督学习了,拟合的再好也没用。
体现在函数上就是下图
正常是测试数据是一个线性或者二次多项式的分布,如果过拟合了,深度网络很有可以弄出一个特别复杂的拟合曲线函数,把上面所有的黑点点都穿过,当然训练数据的误差超级小,但是测试数据一来整个的误差就比较高了。
网络结构介绍
我实验中用到的深度网络结构原型是Fully Convolutional Networks,参考的论文中也叫它U-Net,总之就是一个用来做图像分割的深度网络。示意图如下: 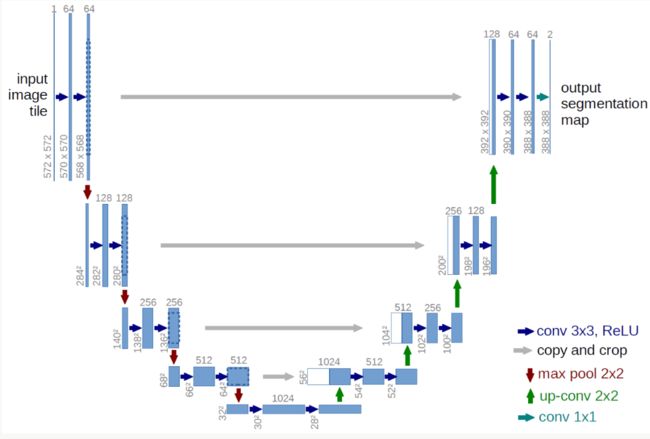

问题分析
当年LeNet-5在手写字的识别上出尽了风头,但是当LeNet-5应用到其他数据集中的时候却出现了很多问题,从此,学者们开始了疯狂的理论、实践探索。“过拟合”问题算是深度学习中一个特别重要的问题,老生常谈了,也有不少解决的方法供我选择。
举例来讲(感谢“知乎深度学习Keras”——QQ群中大神们的帮助):
1. 加入Dropout层
2. 检查数据集是否过小(Data Augmentation)
3. 用一用迁移学习的思想
4. 调参小tricks.
- 调小学习速率(Learning Rate)
- 调小每次反向传播的训练样本数(batch_size)
5. 试一试别的优化器(optimizer)
评价:我认为第一个是比较可行,因为“教科书”上的确有说dropout是专门用来对付“过拟合”问题的。
关于数据集的大小,这也是导致过拟合的原因,如果太小,很容易过拟合。那么多大的数据集够了呢?反正我的肯定够了,我的深度网络输入图像是369,468幅,68*80像素的,二通道输入,总共的大小是19.5GB。这个数据量可以说是十分可观了,所以对我来说,第二条可能不适用。那么如果想要扩充数据集,需要用到Data Augmentation,这个是在医学影像中十分常用的手段,包括平移,旋转,拉伸,扭曲等等变换造出新的数据,来增加数据量。
第三条是深度学习中比较有效的方法了,英文名叫fine-tuning,就是用已有的训练完的网络参数作为初始化,在这个基础上继续训练。原来的网络参数往往会在很多论文和github里头能找到,这是在很大的图像数据集中训练完的网络,根据图形图像的“语义”相似性(我也不知道该怎么描述,就是认为世界上的图片都有某种相似性,就像人类,每个人都长得不一样,但是你不会把人和其他动物混在一起,这就是一个宏观的,抽象的相似性),把这个网络“迁移”到一个新的图像数据集中是有一定的道理的。由于时间原因,我暂时还没有采用这个。
第四条就是比较说不清道不明的调参了,这几乎是机器学习的主要话题,人说“有多少人工,就有多少智能”,这个调参真的需要“经验”啊哈哈哈。
不好意思,第五条又是试凑法。。。可供选择的Optimizers有很多,都试一下,看看用哪儿效果好,听上去有点丧心病狂了。
第六条方法是一个小函数,叫做EarlyStopping,代码如下
early_stopping = EarlyStopping(monitor = 'val_loss', patience = 5)不幸的是,以上六个方案,我测试了以后都没有很好地解决“过拟合”问题。
正则化方法
正则化方法是指在进行目标函数或代价函数优化时,在目标函数或代价函数后面加上一个正则项,一般有L1正则与L2正则等。这个很理论了,会涉及到一些公式。

这部分内容我在学习的时候就当它纯理论来记,当时根本没有想过会去真正用它,看来现在是必须要try一下了。

要在Keras中修改这部分代价函数(Objectives)的代码,可以参考这部分内容,里面包括了若干个代价函数,如果想要自己编写代价函数也可以的。根据这个博客:基于Theano的深度学习(Deep Learning)框架Keras学习随笔-08-规则化(规格化),有效解决过拟合的方法就是加入规则项。具体的规则化可以参见深度学习(DL)与卷积神经网络(CNN)学习笔记随笔-04-基于Python的LeNet之MLP中对于规则化的介绍。博主Tig_Free是真神啊,膜拜一下!
问题解决
最终,过拟合的现象基本上被控制住了,总的来说,L1/L2规范化的确是很牛逼,在学术论文中也有所体现:

网络调整如下:
model = Sequential()
model.add(Convolution2D(64, 4, 4, border_mode='valid', input_shape=data.shape[-3:]))
model.add(Convolution2D(64, 3, 3, border_mode='valid'))
model.add(Activation('relu'))
model.add(Dropout(0.3))
#model.add(BatchNormalization(epsilon=1e-06, mode=0, axis=-1, momentum=0.9, weights=None, beta_init='zero', gamma_init='one'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(64, 4, 4, border_mode='valid'))
model.add(Convolution2D(64, 3, 3, border_mode='valid'))
model.add(Activation('relu'))
model.add(Dropout(0.3))
#model.add(BatchNormalization(epsilon=1e-06, mode=0, axis=-1, momentum=0.9, weights=None, beta_init='zero', gamma_init='one'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(128, 4, 4, border_mode='valid'))
model.add(Activation('relu'))
model.add(Dropout(0.3))
#model.add(BatchNormalization(epsilon=1e-06, mode=0, axis=-1, momentum=0.9, weights=None, beta_init='zero', gamma_init='one'))
model.add(Convolution2D(128, 3, 3, border_mode='valid'))
model.add(Activation('relu'))
model.add(Dropout(0.3))
#model.add(BatchNormalization(epsilon=1e-06, mode=0, axis=-1, momentum=0.9, weights=None, beta_init='zero', gamma_init='one'))
model.add(Convolution2D(128, 3, 3, border_mode='valid'))
model.add(Activation('relu'))
model.add(Dropout(0.3))
#model.add(BatchNormalization(epsilon=1e-06, mode=0, axis=-1, momentum=0.9, weights=None, beta_init='zero', gamma_init='one'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(512, init='normal',W_regularizer=l2(0.02), activity_regularizer=activity_l2(0.01)))
model.add(Activation('relu'))
model.add(Dropout(0.3))
model.add(Dense(512, init='normal',W_regularizer=l2(0.02), activity_regularizer=activity_l2(0.01)))
model.add(Activation('relu'))
model.add(Dropout(0.3))
model.add(Dense(LABELTYPE, init='normal'))
model.add(Activation('softmax')) 配置:)
- dropout层(0.3)
- 全连接层的L2规范化
- 优化器(adadelta)
- 学习速率(1e-9)
达到的效果比较令人满意,不仅训练集的Loss在降低,Acc在上升,测试集的Loss也同样降低,测试集的Acc在上升,整体的网络学习性能也变得比以前好了。

至此,深度网络的过拟合问题暂时告一段落。
关于过拟合的参考材料
机器学习中使用「正则化来防止过拟合」到底是一个什么原理?为什么正则化项就可以防止过拟合?
机器学习中防止过拟合的处理方法
用简单易懂的语言描述「过拟合 overfitting」?
Reducing Overfitting in Deep Networks by Decorrelating Representations. Michael Cogswell, Faruk Ahmed, Ross Girshick, Larry Zitnick, Dhruv Batra (2015)
Dropout: A Simple Way to Prevent Neural Networks from Overfitting. N Srivastava, G Hinton, A Krizhevsky, I Sutskever, R Salakhutdinov (2014)
Overfitting & Regularization (墙)
Regularization in Statistics. PJ Bickel, B Li (2006)
Overfitting, Regularization, and Hyperparameters (墙)
Overfitting. by Hal Daume III (墙)
Data Science 101: Preventing Overfitting in Neural Networks. by Nikhil Buduma (墙)