自动上色论文《Deep Exemplar-based Colorization》(2)
书接上文:https://blog.csdn.net/Najlepszy/article/details/85289496
回来填坑。
四、着色参考图片的推荐系统
正如前文所言,本文对参考图片的选择具有稳健性。为帮助用户发现更好的参考图片,我们提出一种新的图像检索方法,可自动为用户推荐良好的参考图片。此外,该方法通过Top-1候选法来产生全自动的系统。
全局排名:通过gray-VGG-19,我们还可以获得查询图像 T L T_L TL的Top 1 ID。根据类ID,我们将搜索域缩小到同一类的所有图像(大约1000个图像)。我们通过比较查询信息和所有候选者之间的f c特征来过滤不同的候选者。举例来说,查询信息可能是“在草地上奔跑的猫”,但候选图片可能是"坐在屋子里的猫"。然而我们希望这两张图片的语义信息尽可能越相像越好;为了实现这一点,对于该类中每个候选图片 R i R_i Ri(i=1,2,3,…),直接计算 F T 6 F_T^6 FT6和 F R i 6 F_{R_i}^6 FRi6的余弦相似性获得global score,并对这个global score进行排名。
局部排名:全局排名提供给我们前N个可选的图片 R i R_i Ri(N=200),而f c特征由于其会忽略空间信息,因此无法提供更为准确的信息。因此,我们在剩下的N张图片中进行一个局部的排序,来删除一些参考图片。
局部的一致性分数包括语义信息和照度信息。对于每个图片对 { T L , R i } \{T_L,R_i\} {TL,Ri},在 F T 5 F_T^5 FT5的任意像素p上,我们通过最小化 F T 5 ( p ) F_T^5(p) FT5(p)和 F R i 5 ( q ) F_{R_i}^5(q) FRi5(q)来获得最近邻的像素q,命名为q=NN§。因此,语义信息被定义为 F T 5 ( p ) F_T^5(p) FT5(p)和 F R i 5 ( q ) F_{R_i}^5(q) FRi5(q)
照度信息在像素p与q附近区域之间,我们把图片 T L T_L TL分解成有16x16分辨率的二维网格。每个网格经过四个下采样层对应着特征图 F T 5 F_T^5 FT5的一个点。因此, C T ( p ) C_T(p) CT(p)是点p在特征图 F T 5 F_T^5 FT5中点p对应的网格。同样, C R i ( q ) C_{R_i}(q) CRi(q)是特征图 F R i 5 ( q ) F_{R_i}^5(q) FRi5(q)中q点对应的网格。 d H ( ⋅ ) d_H(\cdot) dH(⋅)函数测量 C T ( p ) C_T(p) CT(p)和 C R i ( q ) C_{R_i}(q) CRi(q)的照度直方图之间的相关系数。
局部一致性分数如下所示:
s c o r e ( T , R i ) = ∑ p ( d ( F T 5 ( p ) , F R i 5 ( q ) + β d H ( C T ( p ) , C R i ( q ) ) ) score(T,R_i)=\sum_p(d(F_T^5(p),F_{R_i}^5(q) + \beta d_H(C_T(p),C_{R_i}(q))) score(T,Ri)=∑p(d(FT5(p),FRi5(q)+βdH(CT(p),CRi(q))), β \beta β确定两个信息的相应权重。实验中, β \beta β设置为0.25。一致性分数为每个图片对 T L , R i ( i = 1 , 2 , 3 , . . . ) {T_L,R_i}(i=1,2,3,...) TL,Ri(i=1,2,3,...)。通过全部的局部排名分数,我们重拍虚了全部可选图片并寻找排名靠前的图片。
我们通过PCA降维来加速计算能力。特征fc6的通道数由4096被压缩到128,特征relu5_4的通道数从512被压缩到64,并具有可忽略不计的影响。经过如上降维方式,我们的参考图片搜索算法可以实时运行了。
五、Discussion
通过消融研究,我们测试并证明了着色网络的性能。
问题一:着色子网络学习到了什么?
着色子网络 C \pmb{C} CCC根据目标和参考图片来学习如何选择,传播和预测颜色。如前所述,它是一个端到端网络,涉及两个分支,每个分支都扮演着不同的角色。首先,我们希望在学习过程中仅使用色度分支来理解网络的行为。为此,我们仅通过最小化色度损失来训练 C \pmb{C} CCC的色度分支,并在一个示例上对其进行评估以直观地理解其操作(图7)。
通过比较预测结果(第4列)的色度与对齐参考图片(第3列)的色度,我们注意到它们在大多数区域中具有一致的颜色(例如,“蓝色”天空,“白色”平面和“绿色”草坪)。这表明我们的Chrominance分支从参考图片中选取颜色样本,然后将它们传播到整个图像以实现平滑的着色。
为了了解网络选择哪些颜色样本,我们计算预测结果与第5列中对齐的参考图片之间的色度差(“蓝色”表示几乎没有差异,而“红色”表示显着差异)。具有较小错误的点的颜色更可能由网络选择,然后保留在最终结果中。
“网络如何推断出良好的样本?”或者“良好的样本可以从图像之间的匹配中直接推断出来吗?”为了回答这些问题,我们将差异图(第6列)与平均五级匹配误差 1 − s i m T → R 1 - sim_{T→R} 1−simT→R(第7列)和 1 − s i m R → T 1 - sim_{R→T} 1−simR→T(第8列)进行比较。
一方面,我们可以看到匹配错误与差异图基本一致。这表明我们的网络可以根据匹配质量学习良好的采样,这是确定适当位置的关键“提示”。另一方面,我们发现网络并不总是选择具有较小匹配误差的点,这是由大量不一致样本所证明的。没有相似性图片,Colorization子网很难推断出对齐参考图片和输入图片之间的匹配精度。它还会增加颜色预测的模糊性。因此,根据相似性的自适应选择可能通过直观的启发式是不可行的。但是,通过使用大规模数据,我们的网络可以更直接地学习这种机制。
为了理解感知分支的作用,我们通过单独最小化感知损失来训练它(在等式(6)中)。我们在下图中示出了一个例子。对于这种情况,一些区域与参考图片(即,右“主干”对象)没有很好的匹配。通过仅使用Chrominance分支,我们获得了树干对象的不正确颜色的结果(第4列)。但是,Perceptual分支能够解决这个问题(第8列)。它预测了躯干的单一和自然棕色,因为训练数据中的大部分树干都是棕色的。因此,感知分支的预测纯粹基于来自大规模数据的对象的主色,并且独立于参考。正如我们在第8列中所看到的,即使对于不同的参考,它也会预测相同的颜色。

为了享受两个分支的优势,我们采用多任务训练策略同时训练两个分支。α用作它们的相对重量。图8第5至7列的双分支结果明确表明我们的网络学会自适应地融合两个分支的预测:在匹配良好的区域选择和传播参考颜色,但推广到从来自不匹配或不相关区域的大规模数据中学习自然颜色。相对权重α调整对每个分支的偏好。根据ImageNet验证数据进行评估,我们在实验中将α= 0.005设置为默认值。
问题二:端对端学习为什么重要?
我们的Colorization子网学习了颜色化中的三个关键组件:颜色样本选择,颜色传播和主色预测。据我们所知,没有其他工作可以通过神经网络同时学习三个步骤。
另一种方法是简单地顺序处理这三个步骤。在我们的研究中,我们采用了最先进的颜色传播和预测方法[Zhang et al。 2017年]。这种基于学习的方法显着推进了以前的优化方法特别是当用户点数很少时。我们尝试两种颜色选择策略:1)阈值:选择具有前10%平均双向相似度得分的色点; 2)交叉校验匹配:选择双向映射满足 ϕ T → R ( ϕ R → T ) ( p ) = p \phi_{T→R}(\phi_{R→T})(p)= p ϕT→R(ϕR→T)(p)=p的色点。一旦获得了这些点,我们就直接将它们送到预先训练好的颜色传播网络。我们分别在下图的第3和第4列中显示了两个预测的着色结果。

正如我们所看到的,着色效果不佳并且引入了许多明显的颜色伪影。一个可能的原因是网络[Zhang et al。 2017]未经过输入样本类型的培训,而是使用用户指导的点进行培训。因此,这种顺序学习总是会导致次优解。
此外,该研究还表明难以确定手工制作的点选择规则,如第5.1节所述。通过启发式方法很难消除所有不正确的颜色样本。
预训练的网络也将传播错误的样本,从而导致这种伪像。相反,我们的端到端学习方法通过联合学习选择,预测和预测来避免这些缺陷,从而形成直接优化最终着色质量的单一网络。
问题三:稳健性
与传统的基于样本的着色相比,我们网络的一个显着优势是参考选择的稳健性。无论参考是否与目标相关或不相关,它都可以提供合理的颜色。下图显示了我们的方法在对目标图像具有不同级别的相似性的变化参考上的效果。正如我们所看到的,当引用图片在其语义内容中更类似于目标时,着色结果自然更忠实于引用图片。在其他情况下,结果将退化为保守的着色。这是由感知分支引起的,该分支预测来自大规模数据集上获得的主要颜色。这种行为类似于现有的基于学习的方法。

此外,我们的网络对不同类型的密集匹配算法也很稳健,如下图所示。请注意,本文的网络仅使用Deep Image Analogy进行训练[Liao et al。 2017]作为默认匹配方法,并使用各种匹配算法测试网络。我们还可以观察到结果更加忠实于良好对齐区域的参考颜色;而结果在未对准区域退化为主色(dominant colors)。

注意,更好的对齐结果可以改善可以在引用图片中找到语义对应关系的对象的结果,但是不能帮助给引用对象中不存在的对象的着色。
问题四:可转移性
以前基于学习的方法是数据驱动的,因此只能将与共同属性共享的图像与训练集中的图像着色。由于他们的网络是在自然图像上训练的,例如ImageNet数据集,因此它们将无法为看不见的图像提供令人满意的颜色,例如人类创建的图像(例如,绘画或漫画)。它们的结果可能降低到没有着色(下图中的第1,第3列)或引入显着的颜色伪影(第2列)。相比之下,我们的方法受益于参考图片,并成功地在两种情况下都有效。虽然我们的网络在训练中没有看到这种类型的图像,但是通过Chrominance分支,它学习了基于图像对的相关性来预测颜色。学到的能力对于看不见的物体是常见的。

六、对比结果
结果好就完事了。(太晚了懒得挨个翻译……翻译完下一章睡觉吧)
放图放图。
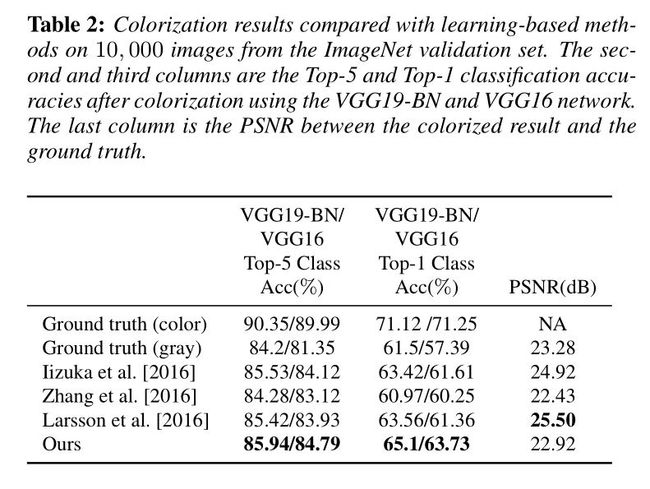 这个VGG Top-X 准确度忘了是干啥用的了……
这个VGG Top-X 准确度忘了是干啥用的了……
 与基于样例图片的方法进行比较
与基于样例图片的方法进行比较

图片的真实程度更高,更难以被用肉眼分辨
 与基于学习的方法作比较
与基于学习的方法作比较
 图片着色是否自然真实,是否能骗得了人的肉眼呢?上面给出了答案。
图片着色是否自然真实,是否能骗得了人的肉眼呢?上面给出了答案。

用户通过学习生成的一些结果(全自动学习??)

与基于交互的方式比较

与全局颜色直方图方式进行比较
 为经典的图片上色
为经典的图片上色
 对视频也可进行着色。
对视频也可进行着色。
七、网络的局限性以及总结
总结:
本文设计了一种基于样例图片的深度学习的方法。即使样例图片并不能提供有效的信息,本文这种方法依然可以生成合理而又自然的着色结果。不同于以往深度学习框架,我们仍可以手动控制着色的结果。与此同时,我们也可以通过自动着色来对图片和视频上色。
局限性:
1、受到感知力损失函数的影响,我们无法去生成含有特别奇怪或者艺术家所形成的颜色

2、其次,基于分类网络(VGG)的感知损失不能惩罚语义重要性较小的区域中的错误的颜色,例如图21第二行中的墙壁,或者不能区分具有相似局部纹理的较少语义区域,例如如图21第三行中类似的沙子和草纹理。此外,当图像之间存在明显的亮度差异时,我们的结果不太忠实于参考图片,如图21的底行所示。为了缓解最后这种情况,我们的参考图片推荐算法在本地排名中强制执行亮度相似性。我们的方法偶尔无法预测某些局部区域的颜色,如下图。因此,探索如何更好地平衡网络的两个分支是很重要的。